TensorFlow2.0入门到进阶2.10 —— 批归一化、dropout、激活函数
文章目录
- 1、批归一化
- 2、dropout
- 3、激活函数
- 3.1 原理部分:
- 3.2 各直观图像激活函数
- 3.3 代码
1、批归一化
原理部分:一文轻松搞懂Keras神经网络(理论+实战)
批归一化其实就是在每经过一层神经网络训练后,将训练结果重新归一化,从而为经过下一层神经网络提过一个良好的数据,消除量纲的影响。
代码: model.add(keras.layers.BatchNormalization())
model=keras.models.Sequential()
#添加输入层,输入的图片展开,Flatten为展平
model.add(keras.layers.Flatten(input_shape=[28,28]))
for _i in range(20):
model.add(keras.layers.Dense(100,activation='relu'))
model.add(keras.layers.BatchNormalization())
"""
#也可将激活函数放在批归一化之后
model.add(keras.layers.Dense(100))
model.add(keras.layers.BatchNormalizaation())
model.add(keras.layers.Activation('relu'))
"""
model.add(keras.layers.Dense(10,activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
模型内部结构查看:
可以通过下面的指令,查看模型内部结构,发现在没经过一个中间层,都有一个batch_normalization,这个就是批归一化处理的结构。
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 100) 78500
_________________________________________________________________
batch_normalization (BatchNo (None, 100) 400
_________________________________________________________________
dense_1 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_1 (Batch (None, 100) 400
_________________________________________________________________
dense_2 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_2 (Batch (None, 100) 400
_________________________________________________________________
dense_3 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_3 (Batch (None, 100) 400
_________________________________________________________________
dense_4 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_4 (Batch (None, 100) 400
_________________________________________________________________
dense_5 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_5 (Batch (None, 100) 400
_________________________________________________________________
dense_6 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_6 (Batch (None, 100) 400
_________________________________________________________________
dense_7 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_7 (Batch (None, 100) 400
_________________________________________________________________
dense_8 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_8 (Batch (None, 100) 400
_________________________________________________________________
dense_9 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_9 (Batch (None, 100) 400
_________________________________________________________________
dense_10 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_10 (Batc (None, 100) 400
_________________________________________________________________
dense_11 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_11 (Batc (None, 100) 400
_________________________________________________________________
dense_12 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_12 (Batc (None, 100) 400
_________________________________________________________________
dense_13 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_13 (Batc (None, 100) 400
_________________________________________________________________
dense_14 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_14 (Batc (None, 100) 400
_________________________________________________________________
dense_15 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_15 (Batc (None, 100) 400
_________________________________________________________________
dense_16 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_16 (Batc (None, 100) 400
_________________________________________________________________
dense_17 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_17 (Batc (None, 100) 400
_________________________________________________________________
dense_18 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_18 (Batc (None, 100) 400
_________________________________________________________________
dense_19 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_19 (Batc (None, 100) 400
_________________________________________________________________
dense_20 (Dense) (None, 10) 1010
=================================================================
Total params: 279,410
Trainable params: 275,410
Non-trainable params: 4,000
2、dropout
理论部分:实战深度神经网络
- Dropout是一种通过删除部分节点单元,来防止模型过拟合的方法
- 一般在模型的后几层添加Dropout
- rate为比例,一般设置为0.5即删除一半的单元
- AlphaDropout:1、均值和方差不变 2、归一化性质也不变
- Dropout:只是传统的普通Dropout,目前主流使用AlphaDropout
- model.add(keras.layers.Dropout(rate=0.5))
model=keras.models.Sequential()
#添加输入层,输入的图片展开,Flatten为展平
model.add(keras.layers.Flatten(input_shape=[28,28]))
for _i in range(20):
model.add(keras.layers.Dense(100,activation='selu'))
model.add(keras.layers.AlphaDropout(rate=0.5))
model.add(keras.layers.Dense(10,activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
3、激活函数
3.1 原理部分:
详见:一文轻松搞懂Keras神经网络(理论+实战)
ReLU:
ReLU函数的计算是在卷积之后进行的,因此它与tanh函数和sigmoid函数一样,同属于非线性激活函数。ReLU函数的倒数在正数部分是恒等于1的,因此在深度网络中使用relu激活函数就不会导致梯度小时和爆炸的问题。并且,ReLU函数计算速度快,加快了网络的训练。不过,如果梯度过大,导致很多负数,由于负数部分值为0,这些神经元将无法激活(可通过设置较小学习率来解决)。
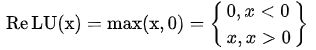
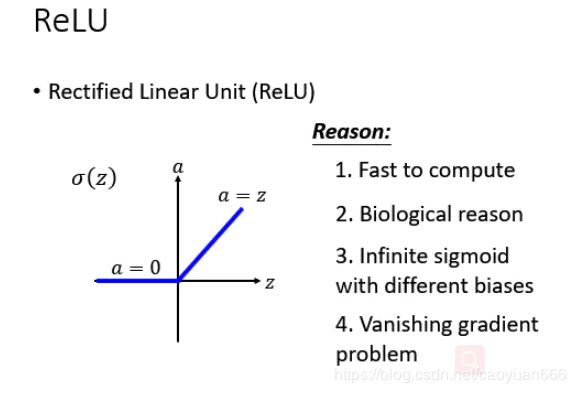
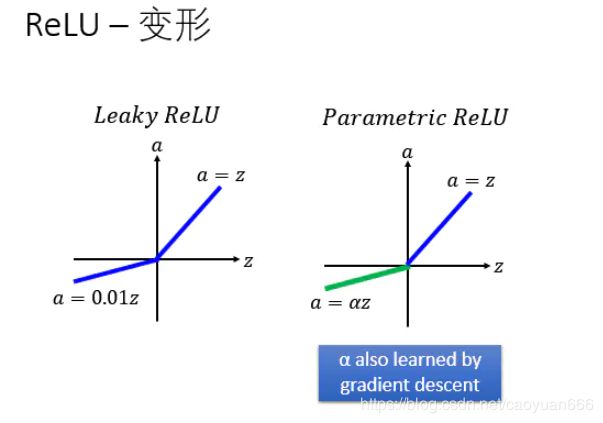
自从有了ReLU以后,就有各式各样的变形,举例来说,有一个东西叫做Leaky ReLU,Leaky ReLU就是说小于0的地方我们不是乘0,我们小于零的地方乘上0.01,马上就会有人问说为什么是乘0.01呢 ? 那么就出现了Parametric ReLU,Parametric ReLU就是说小于0的地方,我们就乘上一个系数。
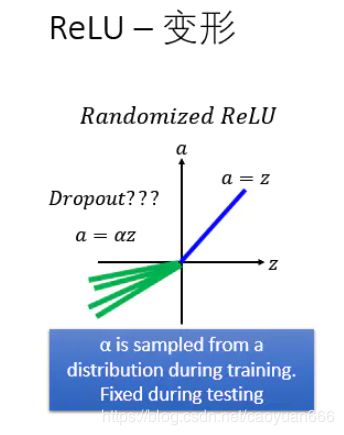
后来又有人想了一招叫Randomized ReLU,那就我所知,Randomized ReLU应该是没有paper的,但是某一个比赛的时候有人用了这一招,然后就得到好的结果,所以就被广为流传这个叫Randomized ReLU,他是说我们今天小于0的地方一样是乘上一个系数,但是的值也不是从data learn出来的,他是从distribution做sample出来的。也就是说以前在做training的时候,每次你的都是不一样的,但是在testing的时候你会fix保存之气那的系数,他就有点类似它是想要做到类似有点dropout的效果。
后来有人提出了一个ReLU的进化版叫做ELU,ELU就是Exponential Linear Unit的意思,如果他在大于0的地方跟其他的ReLU的家族是一样的,不一样的地方是在小于零的地方,它是 α \alpha α乘上e的z次方减1,z就是那个激活函数的input,所以你可以想象说假设等于0的时候, α \alpha α=0,所以这边是接在一起的。而如果趋向于负无穷大的时候,的负无穷大次方是零,0减-1是-1,然后再乘,所以是,所以如下图绿色的线会收敛在。
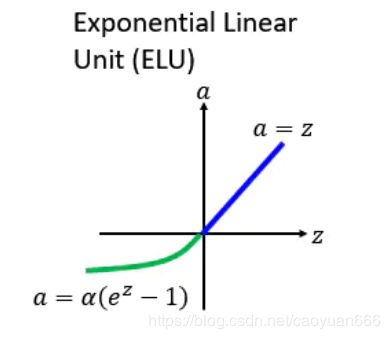
上面那个ELU,α要设多少?后来又出现一种新的方法,叫做:SELU。它相对于ELU做了一个新的变化:就是现在把每一个值的前面都乘上一个λ,然后他告诉你说λ跟α应该设多少,α=1.67326324……,然后λ=1.050700987……。
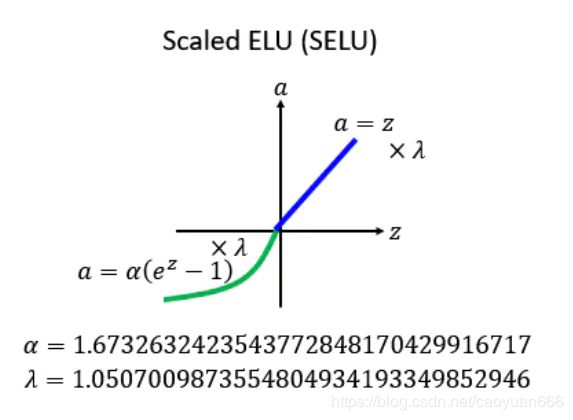
这个λ跟α的值看似是乱讲的,实际上是作者推导出来的,很麻烦的推导,详情也可以看作者的github:https://github.com/bioinf-jku/SNNs
3.2 各直观图像激活函数
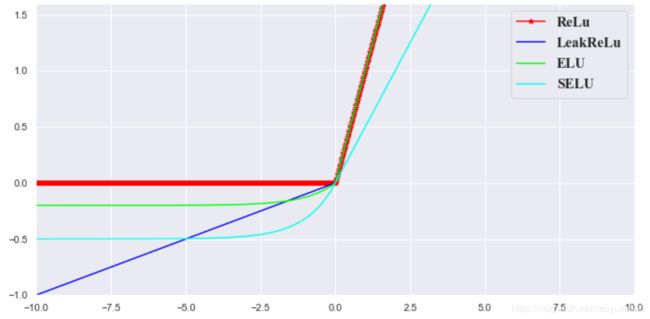
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
sns.set(style="darkgrid")
fig = plt.figure(figsize=(12,6))
plt.xlim([-10, 10]);
plt.ylim([-1, 1.6]);
# 定义数值
x = np.sort(np.linspace(-10,10,1000))
# ReLu 函数
relu= [max(item,0) for item in x]
# LeakReLu函数
alpha = 0.1
leakRelu = [item if item>0 else item*alpha for item in x]
# PReLu函数
alpha = 0.1 # 可以学习的参数
leakRelu = [item if item>0 else item*alpha for item in x]
# ELU函数
alpha = 0.2
elu = [item if item>0 else (np.exp(item)-1)*alpha for item in x]
# SELU函数
alpha = 1
r = 0.5
selu = [item if item>0 else (np.exp(item)-1)*alpha for item in x]
selu = list(map(lambda x:x*r,selu))
# 绘图
plt.plot(x,relu,color="#ff0000", label = r"ReLu", marker='*')
plt.plot(x,leakRelu,color="#0000ff", label = r"LeakReLu")
plt.plot(x,elu,color="#00ff00", label = r"ELU")
plt.plot(x,selu,color="#00ffee", label = r"SELU")
plt.legend(prop={'family' : 'Times New Roman', 'size' : 16})
plt.show()
3.3 代码
代码很简单了,就是在:model.add(keras.layers.Dense(100,activation=‘selu’))中,改变activation内的内容即可。更多激活函数详见官方手册。
model=keras.models.Sequential()
#添加输入层,输入的图片展开,Flatten为展平
model.add(keras.layers.Flatten(input_shape=[28,28]))
for _i in range(20):
model.add(keras.layers.Dense(100,activation='selu'))
model.add(keras.layers.Dense(10,activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])