国外大神制作的超棒 Pandas 可视化教程
本文原创发布于微信公众号「极客猴」,欢迎关注第一时间获取更多原创分享
链接:https://mp.weixin.qq.com/s/JJzlu6mBjUcgoEZLi1JSXw
如果读者们计划学习数据分析、机器学习、或者用 Python 做数据科学的研究,你会经常接触到 Pandas 库。Pandas 是一个开源、能用于数据操作和分析的 Python 库。
1.加载数据
加载数据最方便、最简单的办法是我们能一次性把表格(CSV 文件或者 EXCEL 文件)导入。然后我们能用多种方式对它们进行切片和裁剪。
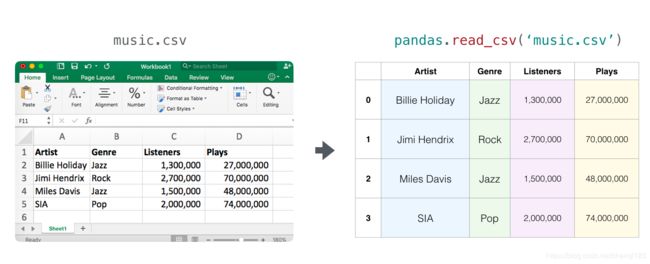
Pandas 可以说是我们加载数据的完美选择。Pandas 不仅允许我们加载电子表格,而且支持对加载内容进行预处理。
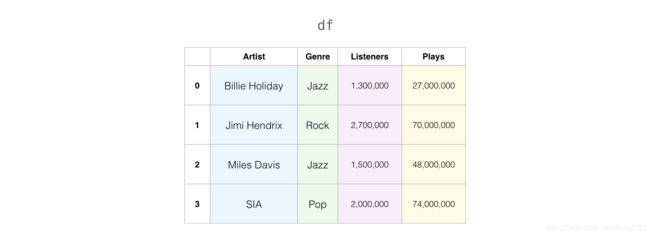
Pandas 有个核心类型叫 DataFrame。DataFrame 是表格型的数据结构。因此,我们可以将其当做表格。DataFrame 是以表格类似展示,而且还包含行标签、列标签。另外,每列可以是不同的值类型(数值、字符串、布尔型等)。
我们可以使用 read_csv() 来加载 CSV 文件。
# 加载音乐流媒体服务的 CSV 文件
df = pandas.read_csv('music.csv')
其中变量 DF 是 Pandas 的 DataFrame 类型。
Pandas 同样支持操作 Excel 文件,使用 pd.read_excel() 接口能从 EXCEL 文件中读取数据。
df = pandas.read_csv('music.xls')
2.选择数据
我们能使用列标签来选择列数据。比如,我们想获取 Artist 所在的整列数据, 可以将 artists 当做下标来获取。

同样,我们可以使用行标签来获取一列或者多列数据。表格中的下标是数字,比如我们想获取第 1、2 行数据,可以使用 df[1:3] 来拿到数据。
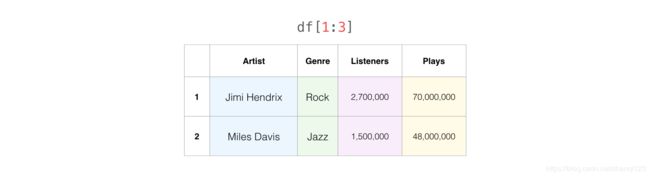
Pandas 的利器之一是索引和数据选择器。我们可以随意搭配列标签和行标签来进行切片,从而得到我们所需要的数据。比如,我们想得到第 1, 2, 3 行的 Artist 列数据。
import pandas as pd
df.loc[1:3, ['Artist']]
# loc(这里会包含两个边界的行号所在的值)

3.过滤数据
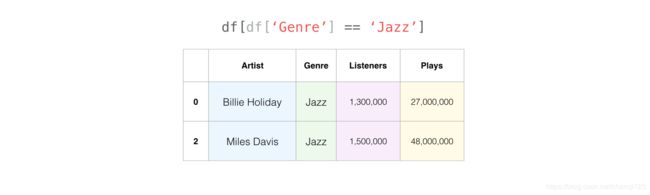
过滤数据是最有趣的操作。我们可以通过使用特定行的值轻松筛选出行。比如我们想获取音乐类型(Genre)为值为 Jazz 行。
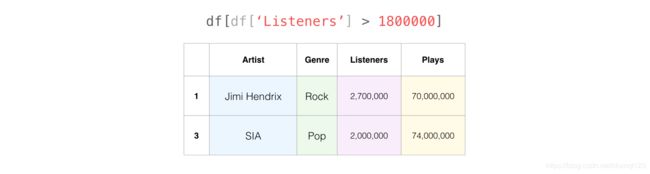
再比如获取超过 180万听众的 艺术家。
4.处理空值
数据集来源渠道不同,可能会出现空值的情况。我们需要数据集进行预处理时。
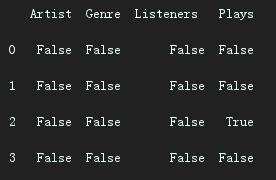
如果想看下数据集有哪些值是空值,可以使用 isnull() 函数来判断
import pandas as pd
df = pd.read_csv('music.csv')
print(df.isnull())
假设我们之前的音乐数据集中 有空值(NaN)的行。
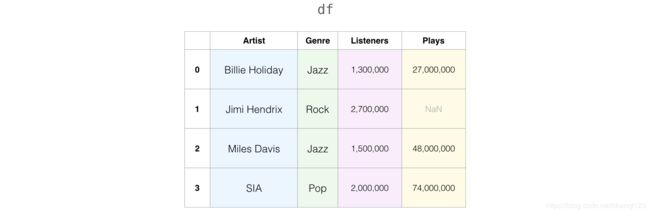
我们对之前的音乐.csv 文件进行判断,得到结果如下:
如果我想知道哪列存在空值,可以使用 df.isnull().any()
import pandas as pd
df = pd.read_csv('music.csv')
print(df.isnull().any())
结果如下:

处理空值,Pandas 库提供很多方式。最简单的办法就是删除空值的行。
除此之外,还可以使用取其他数值的平均值,使用出现频率高的值进行填充缺失值。
import pandas as pd
# 将值填充为 0
pd.fillna(0)
5.分组
我们使用特定条件进行分组并聚它们的数据,也是很有意思的操作。比如,我们需要将数据集以音乐类型进行分组,以便我们能更加方便、清晰了解每个音乐类型有多少听众和播放量。
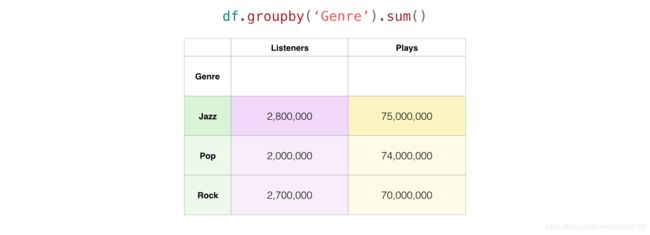
上述代码的的执行过程是:Pandas 会将 Jazz 音乐类型的两行数据聚合一组;我们调用了 sum() 函数,Pandas 还会将这两行数据端的 Listeners(听众)和 Plays (播放量) 相加在一起,然后组合在 Jazz 列中显示总和。
这也是 Pandas 库强大之处,能将多个操作进行组合,然后显示最终结果。
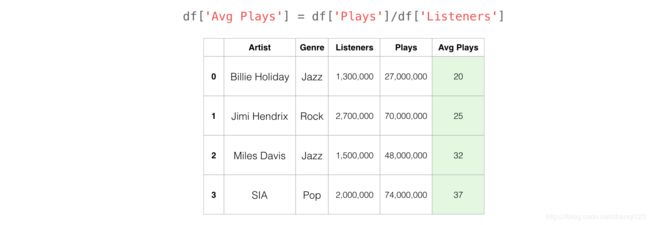
6.从现有列中创建新列
通常在数据分析过程中,我们发现自己需要从现有列中创建新列,使用 Pandas 也是能轻而易举搞定。
作者:Jay Alammar
翻译:极客猴
润色:极客猴
