深度学习去运动模糊----《DeblurGAN》
前言
现实生活中,大多数图片是模糊不清的,试想一下,追剧时视频不清晰,看着都很捉急,何况现实中好端端的一幅美景(美女也可以)被抓拍得不忍直视,瞬间暴躁!!拍照时手抖,或者画面中的物体运动都会让画面模糊,女友辛辛苦苦摆好的各种Pose也将淹没在各种模糊的线条中,是时候要有一种新的算法解救水深火热中的你了。
这不,去年(2017)乌克兰天主教大学、布拉格捷克理工大学和解决方案提供商Eleks联手公布了一篇论文,文章标题为《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》。目前文章已更新,2018。
这篇文章中,研究人员提出一种基于条件对抗式生成网络和内容损失(content loss)的端对端学习法DeblurGAN,去除图像上因为物体运动而产生的模糊。今天我们不看美图,且之论学术。大致聊一聊这个去模糊的过程。
Introduction
在没有提供任何关于核(kernel)或相机的运动信息的情况下,怎样去除单张照片中的运动模糊(Motion Blur)呢?
这不禁让人联想起生成对抗网络(GAN),因为它能够保存高纹理细节,创建的图案又接近真实图像,所以是图像超分辨率和图像修复中的主力军。
能否将这种方法应用到消除运动模糊的工艺中呢?
可以。模糊处理可以看作是图像转化中的一个特例,研究人员提出基于条件生成式对抗网络和多元内容损失的DeblurGAN法。
最近,生成式对抗网络(GAN)在图像超分辨率重建、in-painting等问题上取得了很好的效果。GAN能够保留图像中丰富的细节、创造出和真实图像十分相近的图像。而在CVPR2017上,一篇由Isola等人提出的《Image-to-Image Translation with Conditional Adversarial Networks》的论文更是使用条件生成式对抗网络(cGAN)开启了“image-to-image translation”任务的大门。
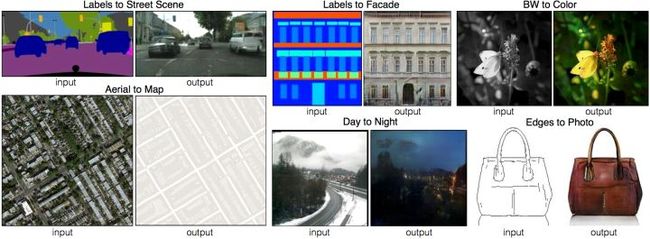 Example results on several image-to-image translation problems.
Example results on several image-to-image translation problems.
本文的思想主要受近期图像超分辨率重建和“image-to-image translation”的启发,把去模糊问题当做“image-to-image translation”的一个特例。使用的网络是 image-to-image translation 论文中使用的cGAN(pix2pix)。
Proposed method:DeblurGAN的实现原理
给出一张模糊的图像 ,我们希望重建出清晰的图像 。为此,作者构建了一个生成式对抗网络,训练了一个CNN作为生成器 和一个判别网络 。
网络结构
生成器CNN的结构如下图:

从上图的架构中可以看出,DeblurGAN包含两个1/2间隔的卷积单元、9个剩余residual单元和两个反卷积单元。每个ResBlock由一个卷积层、实例归一化层和ReLU激活组成。
去除运动模糊的整个流程(网络结构),如下图所示:
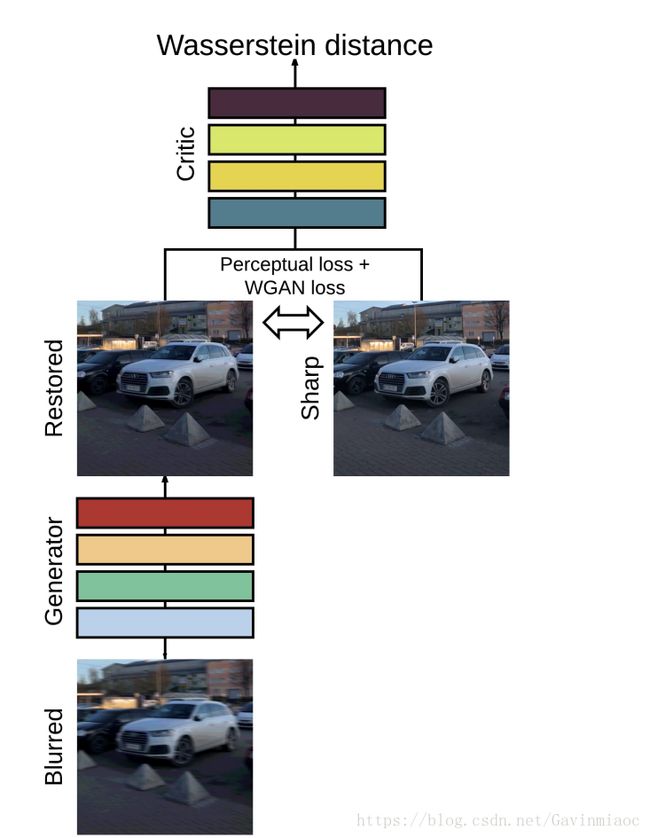
网络结构类似Johnson在风格迁移任务中提出的网络。作者添加了“ResOut”,即“global skip connection”。CNN学习的是残差,即 ,这种方式使得训练更快、模型泛化能力更强。
判别器的网络结构与PatchGAN相同(即 image-to-image translation 论文中采用的判别网络)。
损失函数
损失函数使用的是“content loss”和“adversarial loss”之和:
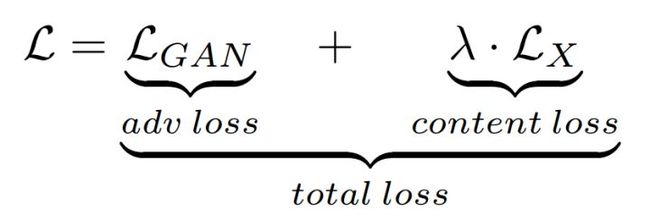
在文章实验中, 。
Adversarial loss
训练原始的GAN(vanilla GAN)很容易遇到梯度消失、mode collapse等问题,训练起来十分棘手。后来提出的“Wassertein GAN”(WGAN)使用“Wassertein-1”距离,使训练不那么困难。之后Gulrajani等提出的添加“gradient penalty”项,又进一步提高了训练的稳定性。WGAN-GP实现了在多种GAN结构上稳定训练,且几乎不需要调整超参数。本文使用的就是WGAN-GP,adversarial loss的计算式为:
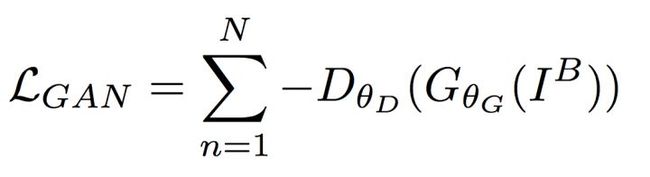
Content loss
内容损失,也就是评估生成的清晰图像和ground truth之间的差距。两个常用的选择是L1(也称为MAE,mean absolute error)损失,和L2(也称为MSE)损失。最近提出了“perceptual loss”,它本质上就是一个L2 loss,但它计算的是CNN生成的feature map和ground truth的feature map之间的距离。定义如下:
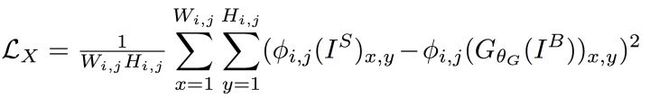
其中, 表示将图像输入VGG19(在ImageNet上预训练的)后在第i个max pooling层前,第j个卷积层(after activation)输出的feature map。 表示feature map的维度。
Motion blur generation
想去糊,先得知道怎样将清晰图像转换成运动模糊图像,这个准备阶段也学问多多。
与超分辨率和黑白照片上色等流行的图像到图像(image-to-image)的转换问题相比,用于训练算法的清晰和模糊的图像对(image pairs)难以获取,一种典型的获取方法是用高帧频相机捕捉视频中清晰的帧模拟模糊图像。
用这种方法创建真实图片的模糊图像,会将图像空间(image space)局限在拍摄的视频中出现的场景,并将数据集变得更复杂。另一种方法就是用清晰图像卷积上各式各样的“blur kernel”,获得合成的模糊图像。作者在现有第二种方法的基础上进一步拓展,提出的方法能够模拟更复杂的“blur kernel”。
根据前人的实验,研究人员提出的方法更真实地模拟了复杂的模糊核(blur kernel)。这种方法遵循了Boracchi和Foi 2012年在论文Modeling the performance of image restoration from motion blur中所描述的随机轨迹生成的概念,对轨迹矢量应用亚像素插值法生成核。每个轨迹矢量都是一个复杂矢量,对应着一个连续域中的二维随机运动物体的离散位置。

首先,作者采用了Boracchi和Foi[1]提出的运动轨迹随机生成方法(用马尔科夫随机过程生成);然后对轨迹进行“sub-pixel interpolation”生成blur kernel。当然,这种方法也只能在二维平面空间中生成轨迹,并不能模拟真实空间中6D相机的运动。
轨迹生成由马尔可夫过程完成、由算法总结。根据前一个点速度和位置、高斯摄动方程和脉冲摄动,随机生成下一个点的位置。
Training Details
DeblurGAN的代码在很大程度上借鉴了pix2pix的代码,使用的框架是pyTorch。作者一共在不同数据集上训练了三个model,分别是:
- :训练数据是GOPRO数据集,将其中的图像随机裁剪成256×256的patches输入网络训练
- :训练数据集是MS COCO生成的模糊图像(根据上面提到的方法),同样随机裁剪成256×256的patches
- :在以上两个数据集的混合数据集上训练,合成图像:GOPRO=2:1
所有模型训练时的batch size都为1。作者在单张Titan-X GPU上训练,每个模型需要6天的训练时间。
为了进行优化,研究人员在DθD上执行了5次梯度下降,在GθG上执行了1次。最初生成器和判别器设置的学习速率为10-4,经过150次迭代后,在接下来的有一轮150次迭代中将这个比率线性衰减。
实验结果对比
GoPro数据集
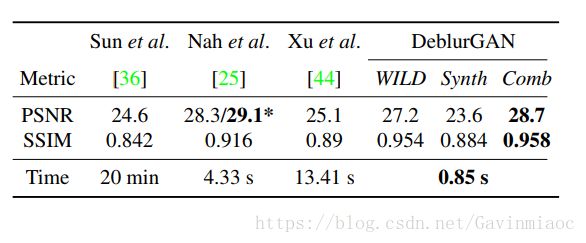
GoPro数据集包含了2103对从不同的场景拍摄的720p的模糊-清晰的图像对。研究人员将模型的结果与标准指标的模型状态进行比较,并在单个GPU上显示每个算法的运行时间,结果如下:
上图是DeblurGAN和Nah等人提出的 Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring 方法的结果对比。左侧一列是输入的模糊图像,中间是Nah等人的结果,右侧是DeblurGAN的结果。
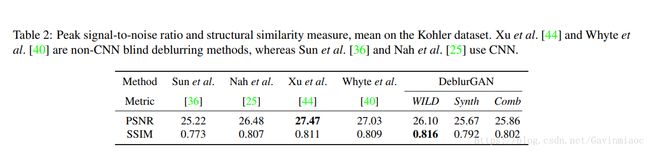
Kohler标准数据集
Kohler数据集由4张图像组成,每张用12个不同的核模糊图像。这是一个标准的基准数据集,用于评价去模糊算法。数据集通过记录和分析真实的相机运动产生,并在机器人载体上回放,这样在6D相机运动轨迹上会留下一系列清晰的图像。

YOLO上的目标检测基准
这项研究中还有一个小彩蛋。
研究人员探索了动态模糊对目标检测的影响,基于在预训练的YOLO网络上目标检测的结果,提出一种评估质量的去模糊算法的新方式。
通过用高帧率摄像机模拟相机抖动,研究人员构建了一个清晰-模糊的街景数据集。之后,对240fps(每秒显示帧数-帧率)相机拍摄的5到25帧进行随机抽样,并计算中间帧的模糊版作为这些帧的平均值。
总体来说,数据集包括410对模糊-清晰图像,这些图像是从不同街道和停车场拍摄的,包含不同数量和类型的汽车。


论文主要贡献:
- 提出使用DeblurGAN对模糊图像去模糊,网络结构基于cGAN和“content loss”。获得了目前最佳的去模糊效果
- 将去模糊算法运用到了目标检测上,当待检测图像是模糊的的时候,先对图像去模糊能提高目标检测的准确率
- 提出了一个新的合成模糊图像的方法
论文来源:arXiv2017
论文作者:Orest Kupyn,Volodymyr Budzan等
下载链接:PDF | github
参考链接:
1.https://blog.csdn.net/yh0vlde8vg8ep9vge/article/details/78641844
2.https://zhuanlan.zhihu.com/p/32260634
**个人感言:**个人认为DeblurGAN文章不论从题材还是创新这篇文章都足够,但是可能目前个人能力也有限,还没有达到论文中作者的实验结果,后续继续就自己实现的继续更新!