概述
为了方便对多个对象的操作,对对象进行存储的操作。集合类中提供很多方便操作对象存储的方法,比数组更容易操作对象。集合只用于存储对象,长度可变,可存储不同类型的对象
Iterator
集合的一个迭代器接口集成,Collection集合中定义专门的生成Iterator实例的方法来方便随时操作集合 Iterator
特点:
①迭代器其实就是集合元素的取出方式。
②每个集合的取出方式都不一样,所以对它们取出方式进行了抽取,抽取为一个接口Iterator,并抽取了3个共性方法hasnext(),next(),remove();
③迭代器降低了取出方式和数据结构之间的耦合性。
④集合的元素取出方式是集合内部的事,所以被定义为内部类,只提供了一个方法来获得取出方式,这个方法为iterator()。
⑤Iterator迭代器只能对集合进行判断,取出删除的操作,当用Iterator迭代时,不可以通过集合对象的方法操作集合中的元素不然会发生并发操作异常ConcurrentModificationException。
Iterator源码:
package java.util;
/*
* Iterator和enumerations的不同点有两处:
* 1.Iterator运行调用者在迭代过程中删除集合元素
* 2.Iterator 改变了函数名
* */
public interface Iterator {
// 如果仍有元素可以迭代,则返回 true。
boolean hasNext();
//返回迭代的下一个元素
E next();
//从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。每次next的过程中只能调用一次
void remove();
}
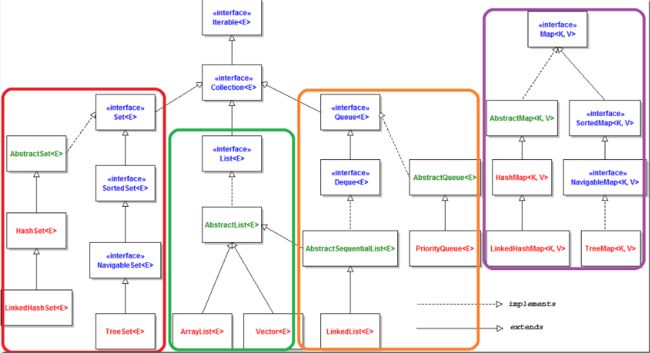
Collection接口
Collection继承自Iterable借口, 是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作。
Collection源码:
/* * Copyright (c) 1997, 2010, Oracle and/or its affiliates. All rights reserved.
* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. */
package java.util;
/*
* 1.Collection接口是集合继承关系中的根接口(root interface),有些集合允许重复元素,有些集合有序,JDK不提供本接口的实现,只提供子接口的实现(例如Set,List)
* 2.所有实现Collection(或者其子接口)的类都必须包含两个构造函数:无参的构造函数,以及参数为Collection的拷贝构造函数
*/
public interface Collection extends Iterable {
//返回集合中存在的元素。如果元素的数目超过Integer.MAX_VALUE,返回Integer.MAX_VALUE
int size();
//当集合不包含任何元素时,返回true
boolean isEmpty();
//如果集合中包含至少一个指定对象,返回true
boolean contains(Object o);
//返回可以遍历集合元素的迭代器
Iterator iterator();
//返回集合中所有元素组成的数组,数组元素的返回顺序要和迭代器访问集合元素的返回顺序一样
Object[] toArray();
//返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同。
T[] toArray(T[] a);
//如果集合不允许重复元素,且集合中已经含有该元素,返回false
boolean add(E e);
//从此 collection 中移除指定元素的单个实例,如果集合中存在指定元素返回true。
boolean remove(Object o);
//如果此 collection 包含指定 collection 中的所有元素,则返回 true。
boolean containsAll(Collection c);
//将指定 collection 中的所有元素都添加到此 collection 中
boolean addAll(Collection c);
//移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。
boolean removeAll(Collection c);
//仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。
boolean retainAll(Collection c);
//移除此 collection 中的所有元素(可选操作)。
void clear();
//比较此 collection 与指定对象是否相等。通过覆盖,实现list与list相等,set与set相等
boolean equals(Object o);
//返回此 collection 的哈希码值。
int hashCode();
}
List列表
List接口通常表示一个列表(数组、队列、链表、栈等),元素是有序的(存入的顺序和取出的顺序一致), 其中的元素可以重复,实现Collection中所有方法。
Vector:底层是数组数据结构。线程同步,所以效率较低,被ArrayList替代了。
ArrayList:底层数据结构式数组,所以查询快,增删慢,线程不同步。
LinkedList:底层是链表数据结构,查询慢,增删快,线程不同步。
Set集合
Set接口通常表示一个集合,其中的元素不允许重复(通过hashcode和equals函数保证),常用实现类有HashSet和TreeSet,HashSet是通过Map中的HashMap实现的,而TreeSet是通过Map中的TreeMap实现的。另外,TreeSet还实现了SortedSet接口,因此是有序的集合。
HashSet:数据结构是哈希表。线程非同步,用hashcode值和equals方法保证元素唯一性。
TreeSet:底层数据结构是二叉树。默认取值顺序是从小到大。
Map映射
Map是一个映射接口,其中的每个元素都是一个key-value键值对,同样抽象类AbstractMap通过适配器模式实现了Map接口中的大部分函数,TreeMap、HashMap、WeakHashMap等实现类都通过继承AbstractMap来实现,另外,不常用的HashTable直接实现了Map接口,它和Vector都是JDK1.0就引入的集合类。
HashTable:底层是哈希表数据结构,不可以存入null键null值。该集合是线程同步的。jdk1.0出现,效率比较低。
HashMap:底层是哈希表数据结构,允许使用null值和null键,该集合是不同步的。jdk1.2效率高
TreeMap:底层是二叉树数据结构。线程不同步。可以用于给Map集合中的键进行排序。
Map集合和Set集合很像,其实Map集合底层就是用的Set集合.
public interface Map {
// Query Operations
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
// Modification Operations
V put(K key, V value);
V remove(Object key);
// Bulk Operations
/*
The behavior of this operation is undefined if the
specified map is modified while the operation is in progress.
*/
void putAll(Map extends K, ? extends V> m);
void clear();
// 由于Map集合的key不能重复,key之间无顺序,所以Map集合中的所有key就可以组成一个Set集合
Set keySet();
Collection values();
Set> entrySet();
interface Entry {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
// Comparison and hashing
boolean equals(Object o);
int hashCode();
}
Map的两种遍历方式:
1、Set keySet:将Map中所有的键存入到Set集合。因为Set具备迭代器。所有可以迭代方式取出所有的键,再根据get方法。获取每一个键对应的值。
2、Set> entrySet:将map集合中的映射关系存入到了 set集合中。
Map.Envy
interface Entry {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
public static , V> Comparator> comparingByKey() {
return (Comparator> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static > Comparator> comparingByValue() {
return (Comparator> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static Comparator> comparingByKey(Comparator cmp) {
Objects.requireNonNull(cmp);
return (Comparator> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static Comparator> comparingByValue(Comparator cmp) {
Objects.requireNonNull(cmp);
return (Comparator> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
总结
整个Java集合框架分为Collection集合和Map集合,实际它们都有个共同特性,它们的取出方式都最终依赖于Collection集合中的迭代器,Map集合实现将Map.Entry关系存入到Set集合,再用Set集合的迭代器取出。Collection接口延续的集合接口最常用的又分为List和Set,List又分为ArrayList、LinkedList和Vector集合,Vector集合是线程同步的,比较低效,所以Vector集合被ArrayList集合给替代了。ArrayList与LinkedList都各具自己的特点,当需要频繁的增删时选择用LinkedList集合,当需要频繁的查询时选用ArrayList集合,它们具有不同的数据结构才使得它们各有不同的特点。Set集合分为HashSet和TreeSet集合,它们的数据结构分别为哈希表和二叉树各具个的特色,不能存储相同的元素,通过hashCode()和equals()方法进行操作,让它们具有比较性。TreeSet集合中具有两种方式的比较性,第一种让元素就有表性,让元素类去实现Comparator接口,在Compare()方法中定义比较关系。第二种让集合具有比较性,给TreeSet集合传递一个Comparable接口实例,并在被覆盖CompareTo()方法中定义比较关系.Map集合中又分为HashTable、HashMap和TreeMap集合,HashTable集合数据结构为哈希表,但不可以存入null键null值,线程同步并且低效,所以不常用。HashMap集合也为哈希表结构,但可以存入null键null值,线程不同步,所以比较高效。TreeMap集合是二叉树结构,线程不同步,也是比较高效的。Map集合和Set很像,实际上Map集合的底层就是用Set集合,HashMap底层用的是HashSet集合,TreeSet集合底层用的是TreeMap集合。