Kubernetes 调度器实现初探

作者| 阿里云智能事业群高级开发工程师 萧元
Kubernetes作为一个分布式容器编排调度引擎,资源调度是它的最重要的功能。在 Kubernetes集群中,调度器作为一个独立模块运行。本文将介绍 Kubernetes 调度器的实现原理,工作流程, 以及未来发展。
Kubernetes 调度工作方式
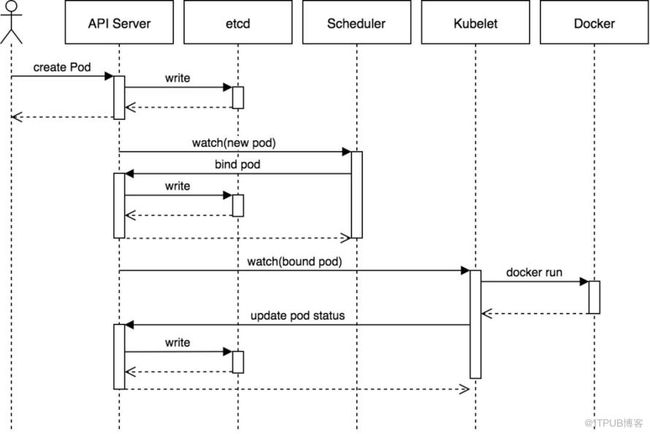
Kubernetes 中的调度器,是作为单独组件运行,一般运行在 Master 中,和 Master 数量保持一致。通过 Raft 协议选出一个实例作为 Leader 工作,其他实例 Backup。 当 Master 故障,其他实例之间继续通过 Raft 协议选出新的 Master 工作。
其工作模式如下:
调度器内部维护一个调度的 pods 队列 podQueue, 并监听 APIServer;
当我们创建 Pod 时,首先通过 APIServer 往 ETCD 写入 Pod 元数据;
调度器通过 Informer 监听 Pods 状态,当有新增 Pod 时,将 Pod 加入到 podQueue 中;
调度器中的主进程,会不断的从 podQueue 取出的 Pod,并将 Pod 进入调度分配节点环节;
调度环节分为两个步奏, Filter 过滤满足条件的节点 、 Prioritize 根据 Pod 配置,例如资源使用率,亲和性等指标,给这些节点打分,最终选出分数最高的节点;
分配节点成功, 调用 apiServer 的 binding pod 接口, 将
pod.Spec.NodeName设置为所分配的那个节点;节点上的 kubelet 同样监听 ApiServer,如果发现有新的 pod 被调度到所在节点,在节点上拉起对应的容器
假如调度器尝试调度 Pod 不成功,如果开启了优先级和抢占功能,会尝试做一次抢占,将节点中优先级较低的 pod 删掉,并将待调度的 pod 调度到节点上。 如果未开启,或者抢占失败,会记录日志,并将 pod 加入 podQueue 队尾。
实现细节
kube-scheduling 是一个独立运行的组件,主要工作内容在 Run 函数 。 这里面主要做几件事情:
初始化一个 Scheduler 实例
sched,传入各种 Informer,为关心的资源变化建立监听并注册 handler,例如维护 podQuene;注册 events 组件,设置日志;
注册 http/https 监听,提供健康检查和 metrics 请求;
运行主要的调度内容入口
sched.run()。 如果设置--leader-elect=true,代表启动多个实例,通过Raft选主,实例只有当被选为master后运行主要工作函数sched.run。
调度核心内容在 sched.run() 函数,它会启动一个 go routine 不断运行sched.scheduleOne, 每次运行代表一个调度周期。
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
}
我们看下 sched.scheduleOne 主要做什么:
func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
.... // do some pre check
scheduleResult, err := sched.schedule(pod)
if err != nil {
if fitError, ok := err.(*core.FitError); ok {
if !util.PodPriorityEnabled() || sched.config.DisablePreemption {
..... // do some log
} else {
sched.preempt(pod, fitError)
}
}
}
...
// Assume volumes first before assuming the pod.
allBound, err := sched.assumeVolumes(assumedPod, scheduleResult.SuggestedHost)
...
fo func() {
// Bind volumes first before Pod
if !allBound {
err := sched.bindVolumes(assumedPod)
if err != nil {
klog.Errorf("error binding volumes: %v", err)
metrics.PodScheduleErrors.Inc()
return
}
}
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: scheduleResult.SuggestedHost,
},
})
}
}
在sched.scheduleOne 中,主要会做几件事情:
通过
sched.config.NextPod(), 从 podQuene 中取出 pod;运行
sched.schedule,尝试进行一次调度;假如调度失败,如果开启了抢占功能,会调用
sched.preempt尝试进行抢占,驱逐一些 pod,为被调度的 pod 预留空间,在下一次调度中生效;如果调度成功,执行 bind 接口。在执行 bind 之前会为 pod volume 中声明的的 PVC 做 provision。
sched.schedule 是主要的 pod 调度逻辑:
func (g *genericScheduler) Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister) (result ScheduleResult, err error) {
// Get node list
nodes, err := nodeLister.List()
// Filter
filteredNodes, failedPredicateMap, err := g.findNodesThatFit(pod, nodes)
if err != nil {
return result, err
}
// Priority
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return result, err
}
// SelectHost
host, err := g.selectHost(priorityList)
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(filteredNodes) + len(failedPredicateMap),
FeasibleNodes: len(filteredNodes),
}, err
}
调度主要分为三个步奏:
Filters: 过滤条件不满足的节点;
PrioritizeNodes: 在条件满足的节点中做 Scoring,获取一个最终打分列表 priorityList;
selectHost: 在 priorityList 中选取分数最高的一组节点,从中根据 round-robin 方式选取一个节点。
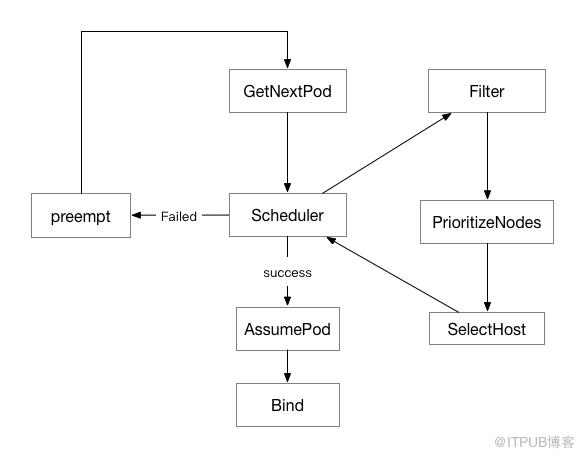
接下来我们继续拆解, 分别看下这三个步奏会怎么做
Filters
Filters 相对比较容易,调度器默认注册了一系列的 predicates 方法, 调度过程为并发调用每个节点的 predicates 方法。最终得到一个 node list,包含符合条件的节点对象。
func (g *genericScheduler) findNodesThatFit(pod *v1.Pod, nodes []*v1.Node) ([]*v1.Node, FailedPredicateMap, error) {
if len(g.predicates) == 0 {
filtered = nodes
} else {
allNodes := int32(g.cache.NodeTree().NumNodes())
numNodesToFind := g.numFeasibleNodesToFind(allNodes)
checkNode := func(i int) {
nodeName := g.cache.NodeTree().Next()
// 此处会调用这个节点的所有predicates 方法
fits, failedPredicates, err := podFitsOnNode(
pod,
meta,
g.cachedNodeInfoMap[nodeName],
g.predicates,
g.schedulingQueue,
g.alwaysCheckAllPredicates,
)
if fits {
length := atomic.AddInt32(&filteredLen, 1)
if length > numNodesToFind {
// 如果当前符合条件的节点数已经足够,会停止计算。
cancel()
atomic.AddInt32(&filteredLen, -1)
} else {
filtered[length-1] = g.cachedNodeInfoMap[nodeName].Node()
}
}
}
// 并发调用checkNode 方法
workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)
filtered = filtered[:filteredLen]
}
return filtered, failedPredicateMap, nil
}值得注意的是, 1.13 中引入了 FeasibleNodes 机制,为了提高大规模集群的调度性能。允许我们通过 bad-percentage-of-nodes-to-score 参数, 设置 filter 的计算比例(默认 50%), 当节点数大于 100 个, 在 filters的过程,只要满足条件的节点数超过这个比例,就会停止 filter 过程,而不是计算全部节点。
举个例子,当节点数为 1000, 我们设置的计算比例为 30%,那么调度器认为 filter 过程只需要找到满足条件的 300 个节点,filter 过程中当满足条件的节点数达到 300 个,filter 过程结束。 这样 filter 不用计算全部的节点,同样也会降低 Prioritize 的计算数量。 但是带来的影响是 pod 有可能没有被调度到最合适的节点。
Prioritize
Prioritize 的目的是帮助 pod,为每个符合条件的节点打分,帮助 pod 找到最合适的节点。同样调度器默认注册了一系列 Prioritize 方法。这是 Prioritize 对象的数据结构:
// PriorityConfig is a config used for a priority function.
type PriorityConfig struct {
Name string
Map PriorityMapFunction
Reduce PriorityReduceFunction
// TODO: Remove it after migrating all functions to
// Map-Reduce pattern.
Function PriorityFunction
Weight int
}
每个 PriorityConfig 代表一个评分的指标,会考虑服务的均衡性,节点的资源分配等因素。 一个 PriorityConfig 的主要 Scoring 过程分为 Map 和 Reduce:
Map 过程计算每个节点的分数值
Reduce 过程会将当前 PriorityConfig 的所有节点的打分结果再做一次处理。
所有 PriorityConfig 计算完毕后,将每个 PriorityConfig 的数值乘以对应的权重,并按照节点再做一次聚合。
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
for i := range priorityConfigs {
var err error
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
}
})
for i := range priorityConfigs {
wg.Add(1)
go func(index int) {
defer wg.Done()
if err := priorityConfigs[index].Reduce(pod, meta, nodeNameToInfo, results[index]);
}(i)
}
wg.Wait()
// Summarize all scores.
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
此外 Filter 和 Prioritize 都支持 extener scheduler 的调用,本文不做过多阐述。
现状
目前 Kubernetes 调度器的调度方式是 Pod-by-Pod,也是当前调度器不足的地方。主要瓶颈如下:
Kubernetes 目前调度的方式,每个 pod 会对所有节点都计算一遍,当集群规模非常大,节点数很多时,pod 的调度时间会非常慢。 这也是 percentage-of-nodes-to-score 尝试要解决的问题;
pod-by-pod 的调度方式不适合一些机器学习场景。 Kubernetes 早期设计主要为在线任务服务,在一些离线任务场景,比如分布式机器学习中,我们需要一种新的算法 gang scheduler,pod 也许对调度的即时性要求没有那么高,但是提交任务后,只有当一个批量计算任务的所有 workers 都运行起来时,才会开始计算任务。 pod-by-pod 方式在这个场景下,当资源不足时非常容易引起资源死锁;
当前调度器的扩展性不是十分好,特定场景的调度流程都需要通过硬编码实现在主流程中,比如我们看到的 bindVolume 部分, 同样也导致 Gang Scheduler 无法在当前调度器框架下通过原生方式实现。
Kubernetes 调度期的发展
社区调度器的发展,也是为了解决这些问题:
调度器 V2 框架,增强了扩展性,也为在原生调度器中实现 Gang schedule 做准备;
Kube-batch: 一种 Gang schedule 的实现 https://github.com/kubernetes-sigs/kube-batch;
poseidon: Firmament 一种基于网络图调度算法的调度器,poseidon 是将 Firmament 接入 Kubernetes 调度器的实现 https://github.com/kubernetes-sigs/poseidon。
参考文献
[1]https://medium.com/jorgeacetozi/kubernetes-master-components-etcd-api-server-controller-manager-and-scheduler-3a0179fc8186
[2] https://jvns.ca/blog/2017/07/27/how-does-the-kubernetes-scheduler-work/
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31555606/viewspace-2637852/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31555606/viewspace-2637852/