挑战王者荣耀“绝悟” AI,会进化的职业选手太恐怖了!


作者 | 马超
责编 | 伍杏玲
出品 | CSDN(ID:CSDNnews)
腾讯 AI Lab 与王者荣耀联合研发的策略协作型AI,“绝悟”首次开放大规模开放:5月1日至4日,玩家从王者荣耀大厅入口,进入“挑战绝悟”测试,“绝悟”在六个关卡中的能力将不断提升,用户可组队挑战“绝悟”。这不是腾讯 AI Lab首次大展伸手了,例如去年“中信证券怀”世界智能围棋公开赛的冠军就是来自于腾讯AI Lab的“绝艺”。

本次在王者荣耀上线的“绝悟”真的是令人觉悟,笔者做为老的DOTATER,MOBA类游戏的水平,自认还是相当不错的,不过亲测了几局,始络不能在路人匹配的情况下通过第三关。“绝悟”的1v1版本曾在2019年的China Joy上开放,在与顶级业余玩家的 2100多场,AI胜率为 99.8%,此次是“绝悟” 5v5 版本首次公开。如果以后挂机队友都能用“绝悟”托管,那估计今后匹配到掉线玩家的队伍,是做梦都要笑醒吧。

“绝悟”如何“开悟”?
在柯洁等人类顶尖棋手纷纷败于AlphaGo后,AI已经破解了围棋的难题,大面积目前多人在线战术竞技类游戏(MOBA)成为测试和检验前沿人工智能的复杂决策、行动、协作与预测能力的重要平台。
比如在去年的DOTA顶级赛事TI8上,在OpenAI与世界冠军OG战队之间的一场DOTA2比赛上,AI战队以2:0完胜了人类冠军。虽然笔者认为OG在TI8上夺冠不太有说服力,去年的LGD和Liquid比OG厉害,不过AI在两场比赛中,尤其在第二场15分钟就完成战斗,展现的强大到碾压的能力令人惊叹。
但是到OpenAI的MOBA游戏的AI模型是有限定条件的,不允许人类选手选择幻影长矛手及分身斧等幻象、分身类道具,虽然王者荣耀游戏中不涉及此类情况,但是与棋类游戏相比,MOBA类游戏的AI模型至少在以下几个方面是完全不同的。
一、复杂度:
王者荣耀的正常游戏时间大约是20分钟,一局中大约有20,000帧。在每一帧,玩家有几十个选项来做决定,包括有24个方向的移动按钮,和一些相应的释放位置/方向的技能按钮。王者峡谷地图分辨率为130,000×130,000像素,每个单元的直径为1,000。在每一帧,每个单位可能有不同的状态,如生命值,级别,黄金。同样,状态空间的大小为10^20,000,其决策点要玩大于棋类游戏。
二、信息不对称:
MOBA类游戏中一般都有视野的范围,这造成了信息的对称,也就是说AI无法像棋类游戏一样获得全部的对局信息。
三、团队配合:一般如王者荣耀等MOBA类游戏都是5V5的集体类游戏,那么整个团队需要有宏观的策略,也需要微观的精细执行。
在游戏的各个阶段,玩家对于决策的分配权重是不同的。例如在对线阶段,玩家往往更关注自己的兵线而不是支持盟友,在中后期阶段,玩家应关注团战的动态。每个AI玩家对队友的配合操作纳入计算范围,这将提高计算量。
四、奖励函数难以制订:
MOBA类游戏到比赛的最后时刻存在悬念,不像棋类游戏中吃子或者提子等奖励来得那么直接。这让MOBA类的AI的奖励函数非常难以制订。

走近强化学习
“绝悟”背后是一种名为“强化学习”(reinforcement learning,RL)的AI技术,其思想源自心理学中的行为主义理论,因此该学习方法与人类学习新知识的方式存在一些共通之处。
游戏作为真实世界的模拟与仿真,一直是检验和提升 AI 能力的试金石,复杂游戏更被业界认为是攻克 AI 终极难题——通用人工智能(AGI)的关键一步。如果在模拟真实世界的虚拟游戏中,AI 学会跟人一样快速分析、决策与行动,就能执行更困难复杂的任务并发挥更大作用。
强化学习做一系列基于时间序列的决策。它先假定每个问题都对应一个Environment,这时每一个Agent在Environment中采取的每一步动作都是一个Action,做出Action之后,Agent从Environment中得到observation与reward,再不断循环这个过程,以达到总体reward最大化。
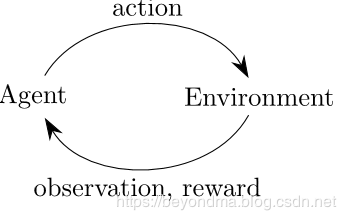
从RL的原理中能看出,RL是一种在不确定且复杂的环境中通过不断试错,并根据反馈不断调整策略,最终完成目标的AI,这和游戏的实践场景可谓非常的契合。
虽然目前RL在一些具体的场景中,如控制步进马达、电子竞技方面取得了很多突破性的进展。截止目前“绝悟”的RL框架还没有开源,不过好在Open AI的gym框架是开源,并提供了RL完整的接口。可以让我们通过玩游戏,来了解深度学习的原理。安装gym十分简单,只是记得要执行这个命令pip install gym[atari]即可。
其示例代码如下:
import gym
env = gym.make('UpNDown-ramDeterministic-v4')#初始化环境
for i_episode in range(900000):
observation = env.reset()#重置观察
for t in range(100):
env.render()#渲染环境
print(observation)#将观察值打印出来
action = env.action_space.sample()#按照sample进行动化,当然也可以自行实现
observation, reward, done, info = env.step(action)
print(reward)#将奖励值打印出来
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
其运行效果如下:

通关小贴士
如何打败AI这点上,我们可以参考而三年前李世石战胜AlphaGo的第四局对弈,其中第78手这一挖,此招一出当时技惊四座,甚至被围棋界认为是“捍卫了人类智慧文明的瑰宝”。

随后AlphaGo被李世石的“神之一手”下得陷入混乱,走出了黑93一步常理上的废棋,导致棋盘右侧一大片黑子“全死”。
此后,“阿尔法围棋”判断局面对自己不利,每步耗时明显增长,更首次被李世石拖入读秒。最终,李世石冷静收官锁定胜局。后来通过仔细复盘人们发现这78手并非无解,只是骗到了当时的AlphaGo引发了AI的Bug才使人类能够赢下一盘。
可以说打败AI最关键的决窍就是,千万不要在AI的空间和AI斗,一定不能按照常理出牌。“绝悟”虽强,但目前肯定还不是完全体,正如我们前文所说,MOBA类AI模型的奖励函数是非常难以制订的,很可能是因为在开局战争迷雾未解开的情况下,入侵野区的收益值不如抱团清线来得高,因此“绝悟”开局大励套路比较单一。那么笔者做为一个菜鸡玩家,通过上述分析给大家一些建议。
一、 选择强势入侵阵容,不断蚕食AI经济。因为AI一般在明确打不过的情况下就会直接放弃,亲测如果人类玩家强势入侵,那么AI一般会选择放弃,不过这个策略对于普通玩家也没有太大用处,因为即使本方经济领先,一般的玩家也依然没法打过AI。
二、 偷塔。由于王者荣耀等MOBA类游戏归底结底还是推塔的游戏,从“绝悟”学习成果结果来看,其对于击杀和远古生物的给予的奖励权重明显更高,这也不难理解,因为在普通的比赛中这两点的确是胜负的关键。
正如上文所说,打败AI的关键点就在于不要按照常理出牌,使用李元芳、米莱迪、周渝这种强势推塔阵容,趁对面在打暴君、主宰等远谷生物时赶快偷塔,实测发现尤其在前4分钟防御塔有隔挡机制时,“绝悟”对于守塔不太感冒。趁这时赶快偷塔,往往是记得比赛的关键。
三、 反杀关键韧性鞋。王者荣耀中有一个非常特殊的道具韧性鞋,能减少被控制的时间,“绝悟”在进行越塔击杀,往往借助于连续的控制。笔者在实测中看到人类玩家反杀“绝悟”的情况,基本都是留好韧性鞋的金钱,等待“绝悟”控制技能施法前摇时,瞬间购买,从而避免被控制至死,进而实现反杀大业,最差也能拖慢AI的节奏,为队友争取偷塔时间。

后记
我们知道现实生活中的许多真实的问题(如股票)没有明确的规则,或者规则会变动,需要具体决策需要AI自行摸索,这是强化学习的优势所在。
长远来看,AI+游戏研究将是攻克 AI 终极研究难题——通用人工智能(AGI)的关键一步。不断让 AI 从0到1去学习进化,并发展出一套合理的行为模式,这中间的经验、方法与结论,有望在大范围内,如医疗、制造、无人驾驶、农业到智慧城市管理等领域带来更深远影响。
未来我们还有哪些“绝悟”AI式的惊喜,让我们拭目以待。

更多精彩推荐
☞新生代的他们,正在续写“黑客”传奇
☞2020 年必备的 IT 技能是什么?
☞视频 | 你不知道的"开源"60年秘史
☞GitHub标星10,000+,Apache项目ShardingSphere的开源之路
☞阿里技术专家告诉你,如何画出优秀的架构图?
☞加拿大API平台如何做到30%为中国明星项目?创业老兵这样说……
你点的每个“在看”,我都认真当成了喜欢