Hive中ObjectInspector的作用
Serde是什么:Serde实现数据序列化和反序列化以及提供一个辅助类ObjectInspector帮助使用者访问需要序列化或者反序列化的对象。
Serde层构建在数据存储和执行引擎之间,实现数据存储+中间数据存储和执行引擎的解耦。
//主要实现数据的序列化和反序列化。
publicabstractclass AbstractSerDe implements SerDe
{
publicabstract Writable serialize(Object obj, ObjectInspector objInspector)
throws SerDeException;
publicabstract Object deserialize(Writable blob) throws SerDeException;
publicabstract ObjectInspector getObjectInspector() throws SerDeException;
}
这里为什么提到数据存储和中间数据存储两个概念,因为数据序列化和反序列化不仅仅用在对目标文件的读取和结果数据写入,还需要实现中间结果保存和传输,hive最终会将SQL转化为mapreduce程序,而mapreduce程序需要读取原始数据,并将最终的结果数据写入存储介质,Serde一方面用在针对inputformat中RecordReader读取数据的解析和最终结果的保存,另一方面,在map和reduce之间有一层shuffle,中间结果由hadoop完成shuffle后也需要读取并反序列化成内部的object,这个object实际上通常是一个Array或者list,但hive会提供一个StandardStructObjectInspector给用户进行该Object的访问。
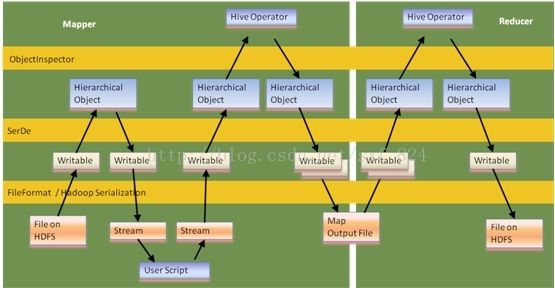
Hive翻译SQL之后会产生很多operator,一个Operator产生的数据需要由下一个operator继续处理。
我们先看一个具体案例:select SUM(show),SUM(click) FROM TableA GROUY BY province,其最终被翻译成operator执行树结果如下图。

上一个Operator的输出是下一个Operator的输入,每一个Operator处理后,数据已经发生变化,比如SelectOperator会将用户没有选择的列去掉(如果数据读取端没有按列存储,一般将读取所有列数据上来),再比如经过groupby算子(map阶段被下推的group by)的数据,key已经变为聚类的列,value已经变成局部聚类的结果,所以每一个operator必须知道上一个operator结果数据的格式,我们先看下operator对象的一个重要方法:
void forward(Object row, ObjectInspector rowInspector);其实rowInspector这个参数已经没用了。
每一个operator处理完数据后就通过该方法将结果推给下一个operator,但是针对ReduceSinkOperator是个例外,它需要把中间结果序列化交给hadoop框架进行数据shuffle,在reduce时,再反序列化回来(通过上文提到的Serde),继续遍历Operator树进行处理。
为什么说这里的rowInspector参数已经没用了呢,我们先看ExecMapper的configure方法,ExecMapper是唯一一个map实现类,针对reducer还有一个ExecReducer:这里只列出了相关内容的代码。
public void configure(JobConf job)
{
//实例化一个MapOperator作为map执行的起点,保存一些上下文对象
mo = new MapOperator();
//这里的初始化方法其实调用的是Operator的初始化方法,最终调用到了Operator的initializeOp方法。
mo.initialize(jc, null);
}
每个Operator在initializeOp方法中实例化自己的outputObjInspector对象,因为只有自己知道自己需要产生的数据是什么结构,并将该outputObjInspector最为参数调用自己childOperator的initialize(Configuration hconf, ObjectInspector inputOI, int parentId)方法,这样自己的childOperator就拿到了上一个Operator生成结果对象的ObjectOperator,也就是说,上一个Operator把数据对象推下来后,自己已经知道这个对象是什么结构了,至此完成了整个operator树的初始化。
那究竟这个ObjectInpector长什么样子,它如何帮助我们访问实际数据对象呢:
publicinterface ObjectInspector
{
publicstaticenum Category {
PRIMITIVE, LIST, MAP, STRUCT, UNION
};
String getTypeName();
Category getCategory();
}

这里面应用最多的应该就是StandardStructObjectInspector。
通过getCategory方法可以知道该ObjectInspector是什么类型,我们通过一个实例了解该对象的使用,通过ObjectInspector帮助我们序列化对象:
staticvoid serialize(OutputByteBuffer buffer, Object o, ObjectInspector oi,
boolean invert) {
switch (oi.getCategory()) {
casePRIMITIVE: {
PrimitiveObjectInspector poi = (PrimitiveObjectInspector) oi;
switch (poi.getPrimitiveCategory()) {
caseVOID: {
return;
}
//如果该对象为布尔类型,直接通过BooleanObjectInspector对象的get方法读取布尔值,保存到buffer中。
caseBOOLEAN: {
boolean v = ((BooleanObjectInspector) poi).get(o);
buffer.write((byte) (v ? 2 : 1), invert);
return;
}
//如果该对象为byte类型,直接通过ByteObjectInspector对象的get方法读取byte值,保存到buffer中。
caseBYTE: {
ByteObjectInspector boi = (ByteObjectInspector) poi;
byte v = boi.get(o);
buffer.write((byte) (v ^ 0x80), invert);
return;
}
//Struct对象较为麻烦一些,如果是Struct对象,获取struct的所有属性和属性对应的ObjectInspector,逐个将每个属性序列化到buffer中。
caseSTRUCT: {
StructObjectInspector soi = (StructObjectInspector) oi;
Listextends StructField> fields = soi.getAllStructFieldRefs();
for (int i = 0; i < fields.size(); i++) {
serialize(buffer, soi.getStructFieldData(o, fields.get(i)), fields.get(
i).getFieldObjectInspector(), invert);
}
return;
}
}
Hive 中operator处理的数据都是Object加上一个ObjectInspector对象,我们可以非常方便的通过该ObjectInspector对象了解到上游传过来的值是什么,如果是Struct对象,可以进一步了解到有多少了Filed,进而获取每个Filed的值,而且通过Serde可以方便的完成数据的序列化操作。