代替Mask R-CNN,BlendMask欲做实例预测任务的新基准?

「免费学习 60+ 节公开课:投票页面,点击讲师头像」
作者 | Hao Chen、Kunyang Sun、Zhi Tian、Chunhua Shen、Yongming Huang、Youliang Yan
译者 | 刘畅
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】实例分割是一种基础视觉任务。在今天要为大家介绍的工作中,作者通过有效地将实例级信息与具有较低级细粒度的语义信息结合起来,提升了掩码预测精度。本文的主要贡献是提出了一个Blender模块,该模块从自上而下和自下而上的实例分割方法中汲取了灵感。由于该方法简单且有效,作者希望本文的BlendMask可以作为各种实例预测任务的基准。

论文地址:
https://arxiv.org/abs/2001.00309
最近,全卷积实例分割方法引起了众多研究者的关注,因为它们通常比Mask R-CNN这样的两阶段方法更简单,更有效。迄今为止,当模型具有相似的计算复杂度时,这些方法几乎都在Mask精度上落后于两阶段Mask R-CNN方法,但这也侧面证明该类方法有很大的提升空间。
本文提出的BlendMask可以通过很少的通道有效地预测密集的像素位置敏感实例特征,并且仅使用一个卷积层就可以为每个实例学习注意力图,从而进行快速推理。BlendMask可以轻松地与最新的一阶段检测框架结合使用,并且在相同的训练策略下,其性能优于Mask R-CNN,且速度提高了20%。轻量级的BlendMask版本在单张1080Ti GPU卡上可以达到25 FPS,34.2%的mAP。
引言
性能最好的目标检测器和分割器通常都遵循两阶段模式。它们由全卷积网络,区域提升网络(RPN)组成,用于对最可能的感兴趣区域(RoI)进行密集的预测。Mask生成的质量和速度与Mask的头结构紧密相关。另外,独立的头部网络很难与诸如语义分割的相关任务共享特征,这给网络架构优化带来麻烦。
One-stage目标检测的最新进展证明,诸如FCOS之类的方法可以在精度上胜过two-stage方法。采用这样的one-stage检测框架执行实例分割任务是非常必要的,因为1)仅由常规操作组成的模型对于跨平台部署而言更简单,更容易;2)统一的框架为多任务网络架构优化提供了便利和灵活性。
密集的实例分割方法可以追溯到DeepMask,这是一种自顶向下的方法,可以使用滑动窗口生成密集的实例mask。Mask的表示在每个空间位置被编码为一维向量。尽管结构简单,但是在训练中有几个问题会阻碍它获得出色的性能:1)失去了特征和mask之间的局部一致性;2)特征表示是多余的,因为在每个前景特征处会重复地对掩模进行编码;3)在使用大步卷积进行下采样后,位置信息会消减。
在本文这项工作中,作者考虑将自上而下和自下而上的方法进行混合。这里不得不提两个重要的工作,即FCIS和YOLACT。他们预测实例级别的信息(例如边界框位置),并将其与分别使用裁剪(FCIS)和加权求和(YOLACT)的单像素预测结合起来。作者认为这些过度简化的组装设计可能无法在顶层和底层特征的表示能力之间取得良好的平衡。
较高层语义的特征对应于较大的感受野,并且可以更好地捕获有关实例(如姿势)的整体信息,而较低级别的特征则会保留更好的位置信息并可以提供更好的细节。本文工作的重点之一是研究在全卷积实例分割中更好地合并这两种方法。更具体地说,本文通过丰富实例级信息与更细粒度的掩码预测来泛化了基于建议(proposal-based)的掩码组合。本文进行了广泛的消融研究,以发现最佳尺寸,分辨率,对齐方法和特征位置。具体而言,本文实现了以下目标:
本文为基于建议(proposal-based)的实例mask生成设计了一种灵活的方法,称为Blender,该方法将丰富的实例级信息与准确的密集像素特征结合在一起。在头部处理器的比较中,本文的混合器在COCO数据集上的mAP分别比YOLACT和FCIS中的相应技术高1.9和1.3点。
本文提出了一种简单的架构BlendMask,该架构将大的计算开销添加到已经很简单的FCOS框架中。
BlendMask的一个明显优势是,其推理时间不会像传统的two-stage方法那样随着预测次数的增加而增加,这使其在实时场景中更加稳健。
在COCO数据集上,使用ResNet-50作为backbone网络,BlendMask的性能可达到37.0%mAP,使用ResNet-101的性能达到38.4%的mAP,在准确性上优于Mask R-CNN,而速度提高了约20%。本文创造了全卷积实例分割的新记录,在mask mAP中仅以一半的训练次数和1/5的推理时间就超过TensorMask 1.1个点。
据本文介绍,BlendMask可能是第一个在mask AP和推理效率方面均能胜过Mask R-CNN的算法。
BlendMask可以自然地解决全景分割,因为BlendMask的底部模块可以同时分割“things and stuff”。
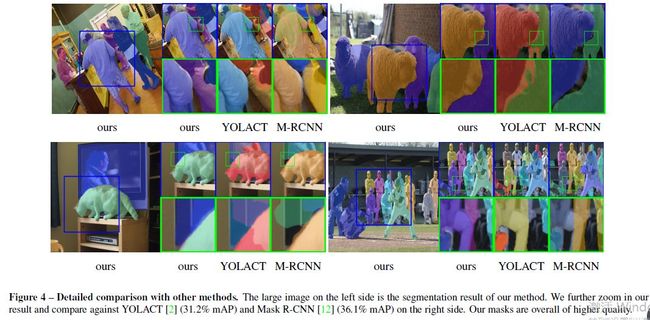
与Mask R-CNN的mask头部(通常为28×28分辨率)相比,BlendMask的底部模块能够输出分辨率更高的mask,这是因为其灵活性强,并且底部模块不受FPN的束缚。因此,BlendMask能够产生具有更精确边缘的mask,如图4所示。对于图形等应用程序,这可能非常重要。
提出的BlendMask是一种通用且灵活的算法。仅使用少量的修改,就可以应用BlendMask解决其他实例级别的识别任务,例如关键点检测。
方法
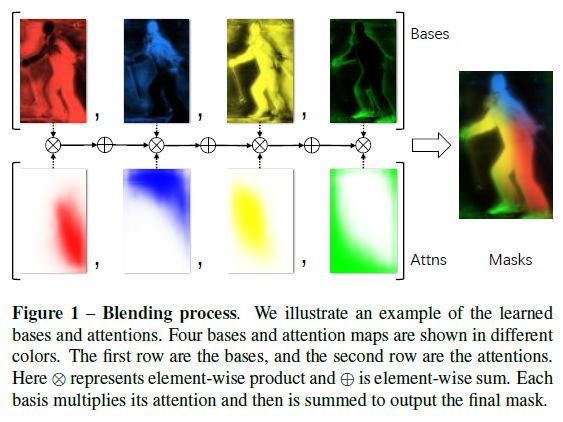
BlendMask由一个检测器网络和一个mask分支组成。Mask分支包括了三个部分,一个是用于预测分数图的底部模块;一个是用于预测实例注意力的顶层,以及一个用于将分数图与注意力合并的混合(Blender)模块。整个网络如图2所示。
底部模块 与其它基于proposal的全卷积方法类似,本文添加了一个称为base(B)的底部模块去预测分数图。这个模块的输入可以是分割网络的主干特征图,也可以是像YOLACT之类的特征金字塔。
顶层(Top layer)本文在每个检测塔的顶端单独添加了一个卷积层去预测顶层的注意力信息A。其相较于YOLACT,多了一个注意力图。

Blender模块是BlendMask的核心部分,它结合了位置相关的注意力信息去生成最终的预测结果。该模块的输入就是底层模块B,顶层注意力信息A和bounding box的回归P。
首先是使用ROIPooler以p_d的大小去剪切base,然后resize到一个固定的RxR大小。
![]()
接下来将注意力信息图从M插值到R。
![]()
然后使用softmax把它归一化到K维。
![]()
最后点乘区域R和分数S,得到最后的mask logit。k是base的索引,图1是K=4时的blending过程。
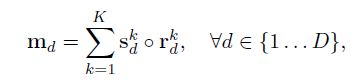
这里面有几个超参,作者在实验部分做了相应的消融实验来确定这类参数。
R,底层ROI的分辨率
M,顶层预测图的分辨率
K,base的数量
实验
实验细节
训练方面,采用了基于ImageNet预训练的ResNet-50模型。通道数为128的DeepLabv3+作为底部模型。训练里面的超参数与FCOS设置的差不多。在测试时间时,是在1080Ti单卡上,batch为1来测试模型的时间。
作者做了详细的消融实现,来说明本文算法的有效性,其中包括融合方法(Blender vs YOLACT vs FCIS)、Top- bottom- 分辨率、base的数量、底部特征的位置(backbone vs FPN)、插值方式(最近邻和双线性)等等。
实验结果
作者主要与Mask RCNN, Tensor Mask等方法做了相应的对比,如表格8所示,在仅使用一半训练次数的情况下,BlendMask的结果优于修改过的Mask RCNN和TensorMask。

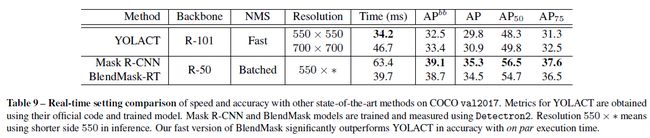
作者还设计了一个实时版本的BlendMask,并与YOLACT相比较。结果如表格9所示。下图展示的是基于ResNet101骨干网络的YOLACT、Mask RCNN几种算法间的可视化比较。
结论
本文为实例级密集预测任务设计了一种新的混合器模块,该模块同时使用高级实例和低级语义信息。与不同的主流检测网络集成起来既高效又容易。
本文的框架BlendMask是优于精心设计的Mask R-CNN,没有花里胡哨的东西,将速度提高了20%。此外,实时版本的BlendMask-RT在单个1080Ti GPU卡上,可达到25 FPS,34.2%的mAP。作者认为本文的BlendMask可以代替Mask R-CNN进行许多其他实例级识别任务。
(*本文为AI科技大本营编译文章,转载请微信联系1092722531)
◆
精彩推荐
◆
点击阅读原文,或扫描文首贴片二维码
所有CSDN 用户都可参与投票和抽奖活动
加入福利群,每周还有精选学习资料、技术图书等福利发送

推荐阅读
2019,不可错过的NLP“高光时刻”
4万程序员学了10万次的课程,今天,曝光背后的讲师!
机器学习模型五花八门不知道怎么选?这份指南告诉你
300多局点,数据接入量超过2TB/S,华为用AI优化数据中台 | BDTC 2019
“一百万行Python代码对任何人都足够了”
达摩院 2020 预测:感知智能的“天花板”和认知智能的“野望”
详解CPU几个重点基础知识
在以太坊上开发 Dapp 的瓶颈和门槛有哪些? | 博文精选

你点的每个“在看”,我都认真当成了AI