诚邀:每日十万+提问,知乎精准推荐如何做得更好?

所有参与投票的 CSDN 用户都参加抽奖活动
群内公布奖项,还有更多福利赠送
整理 | Jane
出品 | AI科技大本营(ID:rgznai100)
1 月 10 日,北京智源人工智能研究院联合知乎、数据评测平台biendata举办的 “2019智源·知乎看山杯专家发现算法大赛”正式收官。该比赛从2019年9月正式启动,为期3个月,以问题路由推荐系统为赛题,开放近200万用户和1000万邀请数据的Link prediction大型数据集。
比赛一共吸引了 711 支来自全球各个院校以及工业界的算法挑战队伍参与,参赛者达到 1631人,最终 7 支队伍脱颖而出,获得大赛奖金。其中,腾讯“test团队”获得冠军,重庆邮电大学、华南理工大学、电子科技大学、广东工业大学组成的混合团队获得亚军,季军则由华南理工大学获得。

(获奖者现场合影)
比赛任务
知识分享服务已经成为目前全球互联网的重要、最受欢迎的应用类型之一。在知识分享或问答社区中,问题数远远超过有质量的回复数。知乎,每天有数以十万计的新问题以及 UGC 内容产生的网站,如何高效的将这些用户新提出的问题邀请其他用户进行解答,以及挖掘用户有能力且感兴趣的问题进行邀请下发,优化邀请回答的准确率,提高问题解答率以及回答生产数,成为知乎最重要的课题之一,而本次比赛也旨在解决这一问题。
自2016年引入机器学习技术以来,知乎已经将人工智能、算法技术应用到社区内容和产品体验的各个环节中。目前,知乎算法团队已经搭建了一套基础生态体系,通过算法实现了用户画像、内容分析、内容个性化推送等,其效率比过去的人工运营方式提高了数十倍。
为了让内容和用户更高效、精准地匹配,知乎专家推荐系统即问题路由系统应运而生。问题路由推荐系统每日对10万+的问题进行分发,并保证问题提问后3日内的解答率达到70%以上;系统对千万级的创作群体进行精准推荐,经由系统智能分发推荐下每日产生的回答数超过20万。
问题路由同时也是本次看山杯的题目来源,比赛旨在从选手中征集高效精准的推荐算法,挖掘有能力且感兴趣的用户进行问题的精准推荐。比赛将提供知乎的问题信息、用户画像、用户回答记录,以及用户接受邀请的记录,要求选手预测这个用户是否会接受某个新问题的邀请。
数据
相比国外的ImageNet、Gigaword等高质量数据集,中文互联网相关的高质量数据集是相对缺乏的,而知乎累积了非常多的高质量文本语料和其他各种各样的数据。此次比赛,知乎选出了一个月的邀请数据作为训练数据,开放近 200 万用户和 1000 万邀请数据的Link prediction大型数据集。
数据特征包括:
1、问题信息。包括<问题id、问题创建时间、问题的话题、问题的文本、问题的描述>等。
2、用户的回答。包括<回答id、问题id、作者id、回答的文本、回答时间、点赞数、收藏数、感谢数、评论数>等。
3、用户人画像数据。包括<用户id、性别、活跃频次、关注话题、长期兴趣、盐值>等。
4、
5、最近一月的邀请数据包括<问题id、用户id、邀请时间、是否回答>。
在现场听了各位获奖团队的分享后,营长决定把这些优秀的方案整理分享给大家。接下来,我们带领大家先一睹本次竞赛 Top3 团队与他们的解决方案,看看他们都是如何做赛题分析、特征工程与模型设计的。
Top 1:特征工程在知乎推荐中的应用
(一)团队:test团队(曹雄,腾讯)
(二)在这次竞赛中,test团队取得了 auc 排名第一的成绩。通过抽取用户特征、问题特征、用户兴趣命中特征、问题统计特征、用户行为特征,融合 LightGBM 模型和 DeepFM 模型进行训练,得到最终的预测结果。

(现场颁奖:一等奖)
(三)特征工程
test团队使用的特征包含:用户特征、问题特征、用户兴趣命中特征、问题统计特征、用户行为特征。
1、使用的用户特征如下:
(1)用户ID, 格式为 Mxxx。
(2)性别。
(3)创作关键词的编码序列,格式为 W1,W2,W3,...,Wn , 表示创作关键词的编码序号,如果创作关键词为空,则用 -1 进行占位。
(4)创作数量等级。
(5)创作热度等级。
(6)注册类型。
(7)注册平台。
(8)访问频率,有五种取值 [new | daily | weekly | monthly | unknow] , 分别对应为 [新用户 | 日活用户 | 周活用户 | 月活用户 | 未知]。
(9)用户二分类特征A,两种取值 0 或 1。
(10)用户二分类特征B,两种取值 0 或 1。
(11)用户二分类特征C,两种取值 0 或 1。
(12)用户二分类特征D, 两种取值 0 或 1。
(13)用户二分类特征E, 两种取值 0 或 1。
(14)用户分类特征A, 格式为 MDxxx。
(15)用户分类特征B, 格式为 BRxxx。
(16)用户分类特征C, 格式为 PVxxx。
(17)用户分类特征D, 格式为 CTxxx。
(18)用户分类特征E, 格式为 PFxxx 。
(19)用户的盐值分数。
(20)用户关注的话题,格式为 T1,T2,T3,...,Tn , 表示用户关注话题的序列编号 (最多 100 个),如果关注话题为空,则用 -1 进行占位。
(21)用户感兴趣的话题,格式为 T1:0.2,T2:0.5:T3,-0.3,...,Tn:0.42 , 表示用户感兴趣的话题序列编号及喜好程度分数 (最多 10 个),如果感兴趣话题为空,则用 -1 进行占位。
其中很多特征是文本特征,需要进行离散到数值空间
2、使用的问题特征如下:
(1)问题创建时间, 格式为 D3-H4。
(2)问题标题的单字编码序列, 格式为 SW1,SW2,SW3,...,SWn , 表示问题标题的单字编码序号。
(3)问题标题的切词编码序列, 格式为 W1,W2,W3,...,Wn , 表示问题标题的切词编码序号, 如果问题标题切词后为空, 则用 -1 进行占位。
(4)问题描述的单字编码序列, 格式为 SW1,SW2,SW3,...,SWn , 表示问题描述的单字编码序号, 如果问题没有描述, 则用 -1 进行占位。
(5)问题描述的切词编码序列, 格式为 W1,W2,W3,...,Wn , 表示问题描述的切词编码序号, 如果问题没有描述或者描述切词后为空, 则用 -1 进行占位。
(6)问题绑定的话题 ID, 格式为 T1,T2,T3,...,Tn , 表示问题绑定的话题 ID 的编码序号, 如果问题没有绑定的话题,则用 -1 进行占位。
其中很多特征是文本特征,需要进行离散到数值空间;问题id特征没有使用,因为在测试中发现该特征的作用是负向的,负向的原因可能是问题推送给用户回答的时间比较短(只有几天时间)。
3、使用的用户兴趣命中特征如下:
(1)用户topic命中问题topic的Id
(2)用户topic命中问题topic个数
4、使用的问题统计特征如下:
(1)问题点击率统计
(2)问题标题点击率统计
(3)问题描述点击率统计
(4)问题ID点击率统计
以上特征按照天区间进行统计,分为1天、7天、14天、30天;同时以上特征可以按照小时统计,统计最近12小时的数据
5、用户行为特征分为:用户行为统计特征、用户行为相似特征、用户展示特征
其中,使用的用户行为统计特征如下:
(1)问题标题点击率统计
(2)问题描述点击率统计
(3)用户点击率统计
以上特征按照天区间进行统计,分为1天、7天、14天、30天;
使用的用户行为相似特征如下:
(1)问题标题点击相似
(2)问题描述点击相似
以上特征按照天区间计算相似度,分为1天、7天、14天、30天;相似的计算过程是;利用数据中的embeding,将标题embeding相加得到问题标题的embeding,将用户点击标题的embeding相加得到用户embeding,计算用户embeding和标题embeding的cos距离。
使用的用户展示特征如下:
(1)当前展示位置
(2)当前小时展示数量
(四)模型简介:本文使用deepfm和LightGBM训练数据,其中deepfm的特征需要进行离散化
1、LightGBM:是一个梯度 boosting 框架,使用基于学习算法的决策树与传统算法相比具有的优点:
更快的训练效率
低内存使用
更高的准确率
支持并行化学习
可处理大规模数据
原生支持类别特征,不需要对类别特征再进行0-1编码这类的
使用的参数如下:
num_leaves=800
learning_rate=0.035
min_data_in_leaf=100
max_bin=2047
2、DeepFM:和Wide & Deep的模型类似,DeepFM模型同样由浅层模型和深层模型联合训练得到。不同点主要有以下两点:
wide模型部分由LR替换为FM。FM模型具有自动学习交叉特征的能力,避免了原始Wide & Deep模型中浅层部分人工特征工程的工作。
共享原始输入特征。DeepFM模型的原始特征将作为FM和Deep模型部分的共同输入,保证模型特征的准确与一致。
3、模型融合:LightGBM取得AUC为0.895,DeepFM取得的AUC为0.88,融合权重0,7:0.3,最终auc为0.8969
Top 2:多模式专家发现算法
(一)团队 Conquer:章凡(电子科技大学)、刘岱远(广东工业大学)、叶青照(华南理工大学)、林智敏(重庆邮电大学)
(二)Conquer 团队对问题寻找最佳匹配的专家回答任务,提供了一个多模式的解决方案。其中,对于特征工程,本文考虑了全局特征,时间滑窗特征,匹配特征,句嵌入特征,图特征,排序特征,Word2vec等;对于模型,针对赛题的设计并修改了多种模型,最后进行融合,其中包括:LightGBM,CatBoost,Multi-ESIM,DSSM,LSTUR。每种模型考虑不同的特征,融合取得了非常显著的结果。

(现场颁奖:二等奖)
(三)特征工程
1、全局统计特征:针对Train和Test,对于样本用所有邀请时间之前的数据做为特征。
(1)answer_info统计:针对answer_info,提取每个样本在该邀请时间之前的用户的回答次数,问题的回答次数,用户在该邀请时间之前回答问题的点赞数、回答词数、收藏数等(去掉方差为0的特征)的(sum、mean、max、min、std、median)
(2)时间统计:用户邀请时间、天、小时、星期,问题创建时间、天、小时、星期。邀请时间减去创建时间,上一次邀请时间(天数),用户受到邀请的rank(根据时间、天数),问题受到邀请的rank(根据时间、天数),邀请时间减去上一次回答的时间、天数)等
用户回答时间,当前邀请时间之前该用户回答问题时间的(时间、天数、小时、星期),回答时间减去问题创建时间(时间、天数、小时、星期)的统计特征(sum、mean、max、min、std、median)。
(3)当天邀请统计:用户同一时间收到邀请的时间,当天收到邀请的rank,用户收到邀请总共有多少种独特的天数。用户同一时间最多收到多少次邀请。
(4)前七天、前一天用户收到的邀请的时间统计,问题前七天、前一天发出邀请的时间 统计。
(5)时间diff:用户邀请时间间隔,回答时间间隔的统计特征(mean,max,min,std)
(6)用户关注主题下有多少个问题,问题主题下有多少个用户关注。
2、时间滑窗统计:划分train test提取的特征区间(其中3809等为天数的脱敏值)
train1 3809-3839预测3840-3846
train2 3816-3846预测3847-3853
train3 3823-3853预测3854-3860
train4 3830-3860预测3861-3867
test 3837-3867预测3868-3874
构造的特征除了全局特征中的处理方式,还包括:1)一天里最多回答次数2)用户最高赞的回答3)用户最高赞的回答的话题4)用户最高赞回答的问题5)优秀回答的次数/优秀回答
3、匹配特征
(1)对用户关注的主题以及问题的主题的topic embedding分别平均构成句向量,计算向量时间的相似度(cosine, cityblock, jaccard, canberra, euclidean, minkowski, braycurtis),对相似度按天进行rank。
(2)对用户邀请时间之前的回答的问题的标题,与当前问题的标题计算BM25相似度打分,统计当前问题与过去回答过的问题的相似度打分的均值
4、文本特征、主题特征
(1)除了使用nn外,使用平均词向量得到的句向量直接入模,使用加权词向量获得的句向量直接入模。
(2)使用tfidf,分别对用户关注主题-问题主题做tfidf(用弱分类器提取oof特征,包括LR,SGD,Ridge)
(3)对用户感兴趣主题的兴趣值构建csr矩阵,与问题主题的tfdif-count构架的csr矩阵进行拼接提取oof特征(模型包括SGD、LR、Ridge)
5、基本统计
(1)对member_info做频率编码。
(2)对用户ID,问题ID做频率编码。
(3)提取关注话题个数,问题话题个数等。
6、图特征
(1)使用IJCAI2019的工作ProNE[3]算法,使用用户当节点,受邀问题作为边,提取用户ID的图Embedding。该算法计算图Embedding速度较快。
(2)使用pagerank算法提取用户ID和问题ID的打分。
7、点击率特征:使用划分时间窗的方法(划分方法与2.2相同)提取用户ID和问题ID 的点击率特征,并使用贝叶斯平滑,填充新用户和新问题。
(四)模型简介
1、CatBoost:由于对GPU友好,且用本比赛中相同数据特征做实验,最后线上结果和LightGBM相差无几,故选用CatBoost作为训练分类器。CatBoost 算法有以下三个的优点:它自动采用特殊的方式处理类别型特征(categorical features)。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。这也是我在这里介绍这个算法最大的motivtion,有了catboost,再也不用手动处理类别型特征了。 catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
2、LightGBM:在特征分配方面,所有全局特征使用LightGBM训练,所有滑窗特征使用CatBoost训练。增加了模型之间的差异性。
3、 DSSM

4、Multi-ESIM

模型说明:ESIM是IJCAI2017年的工作,具体结构为:使用Bi-LSTM对文本编码,并加入了软对齐,最后使用Bi-LSTM增强表示,是文本匹配任务中的经典模型,具体模型结构请见[1]。本方案构造多种匹配对,对当前问题以及过去回答过的问题,主题等进行匹配,针对字Embedding和词Embedding训练了两个模型,效果吊打下方所述LSTUR模型,也可能是由于特征比较多一些。
5、LSTUR
模型说明:ACL2019[2]的工作,原模型主要针对新闻推荐任务,用GRU提取用户长期的兴趣表示,并与当前新闻做相似度打分。没有开源源码,所以仅凭个人理解复现。由于上述Multi-ESIM没有使用更多的用户更长时间之前的回答过的问题,所以针对长期兴趣使用该模型。这里没有完全按照原本的设计,部分结构根据效果好坏进行了微改,效果略差于ESIM。
Top 3:基于用户画像和文本信息的问题推荐策略
(一)团队:MemoryError;陈雄君 陈垂泽 黎潇潇(华南理工大学)
(二)MemoryError团队基于用户画像和文本信息对新问题进行用户推荐,旨在高效地将用户新提出的问题邀请其他用户进行解答,以及挖掘用户有能力且感兴趣的问题进行邀请下发,优化邀请回答的准确率,提高问题解答率以及回答生产数。

(现场颁奖:三等奖)
(三)特征工程
针对本次数据集所构建的特征主要可归类为:横向特征、统计特征、相似度特征和深度提取特征。各类特征说明如下:
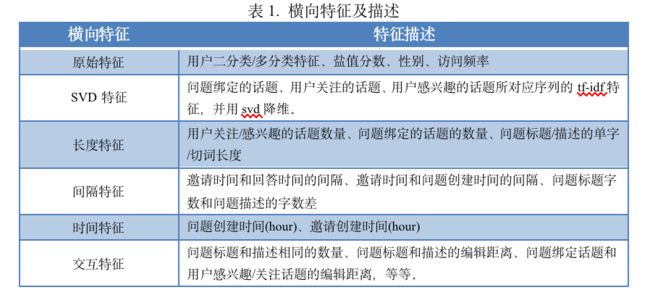
1、横向特征:本类特征均为对单行数据进行构建,主要集中对member info、invite info以及question info三个数据集进行特征构建,横向特征可概述为原始特征、SVD特征、长度(计数)特征、间隔特征、时间特征和交互特征,如表1所示。
2、统计特征:本类特征为对合并后的数据集进行的全局/局部统计,统计特征可概述为:盐值分数统计、用户/问题的全局统计、用户/问题的SVD、用户/问题曝光局部统计、时间统计、曾回答问题的状态统计、长度统计。统计特征详情见表2。

3、相似度特征:本类特征为对各序列进行求取余弦相似度,主要分为对各序列所对应的id的embedding序列求average后求余弦相似度,以及对各序列的每个id的embedding求余弦相似度后再求max/min/mean的统计特征,如表3所示。

4、神经网络提取特征:本类特征为通过不同网络提取序列特征,对各编码序列作不同预处理后分别输入不同的网络,根据五折所得的out-of-fold预测作为新特征。深度提取特征详情见表4。

(四)模型介绍
1、基于神经网络的序列特征提取
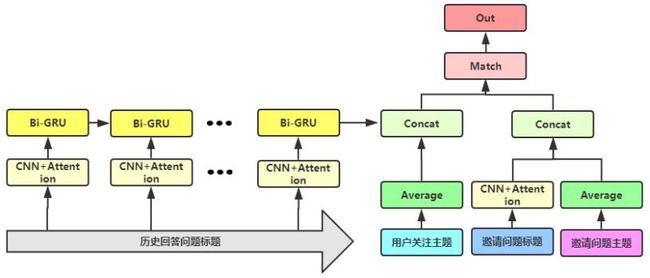
在本次比赛中,我们进一步使用神经网络来对序列数据进行建模,并用于提取序列特征。我们使用序列数据包括:用户关注话题、问题所属话题、用户历史回答问题的标题和描述、问题的标题和描述。对应不同序列的网络结构如下:
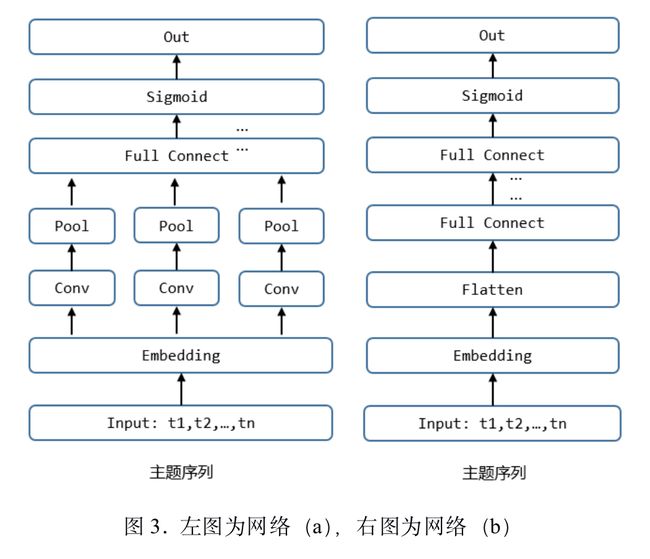
(1)用户关注话题、问题所属话题:我们尝试了两种不同结构的网络。首先序列特征经过Embedding层,中间(a)使用卷积层+池化层(Average/Max)、(b)使用Flatten直接拉伸Embedding向量,最后再经过若干层全连接。网络结构如下:
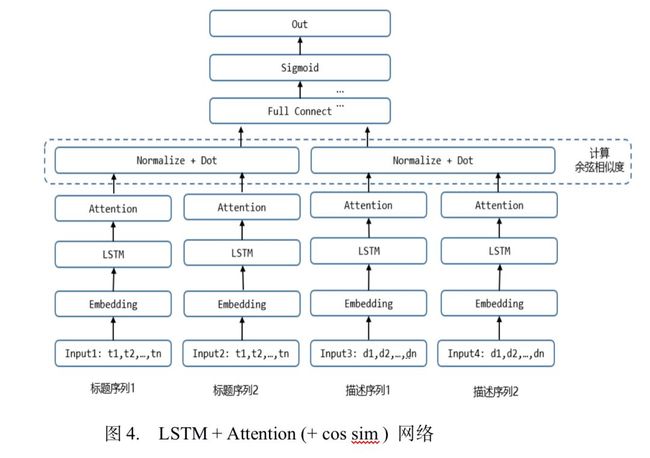
(2)用户历史回答问题的标题和描述、问题的标题和描述:这里我们同样也尝试了不同结构的网络。上述四组序列经过Embedding层后,再使用(a)卷积层+池化层、(b)LSTM+Attention进行特征提取,最后再接全连接层。(c)我们还尝试先对两组标题向量、两组描述向量先分别计算余弦相似度,再接全连接层。网络结构如下:
通过上述的特征构建后,全量特征被使用在树模型以及神经网络模型中,在模型选择方面,因数据较大,选择了可使用并行GPU的Catboost、Xgboost以及Wide& Deep网络,并最终将三个模型作简单的blending,最后再把两个模型组所得结果加权平均。
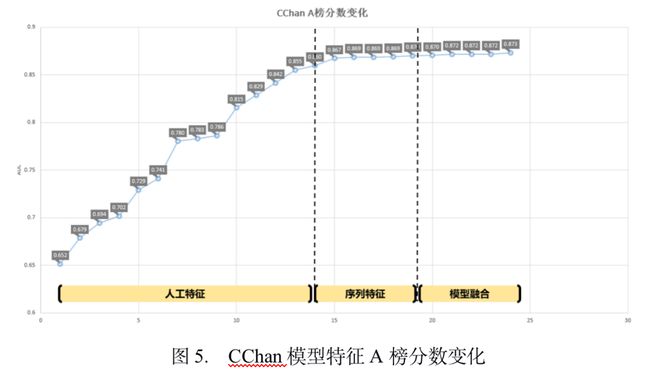
以CChan的特征和模型在A榜数据为例,仅使用人工构造的特征可达到0.86+的分数,加入神经网络提取的序列特征后,分数达到0.870。对Catboost,Xgboost和Wide & Deep的预测结果进行融合,分数可达到0.873。A榜采用上述特征, Travis的Catboost模型的AUC最高分为0.87559,相同特征通过三个不同模型融合可得0.878左右的分数,与CChan模型所得结果加权融合后可得0.88013左右的分数。B榜根据特征分布情况剔除部分特征并加入在A榜丢弃的特征,我们在B榜得到0.89449的分数。比赛过程的大致得分曲线如下:
其他获奖选手的解决方案,我们将在后续的文章中为大家继续做报导,感兴趣的小伙伴可持续关注 AI科技大本营(ID:rgznai100)
(*本文为AI科技大本营整理文章,转载请微信联系1092722531)
◆
精彩推荐
◆
点击阅读原文,或扫描文首贴片二维码
所有CSDN 用户都可参与投票活动
加入福利群,每周还有精选学习资料、技术图书等福利发送
点击投票页面「讲师头像」,60+公开课免费学习

推荐阅读
只需3行代码自动生成高性能模型,支持4项任务,亚马逊发布开源库AutoGluon
AbutionGraph:构建以知识图谱为核心的下一代数据中台
微信9年:张小龙指明方向,微信AI全面开放NLP能力
想知道与你最般配的伴侣长什么样?这个“夫妻相”生成器要火
2020年趋势一览:AutoML、联邦学习、云寡头时代的终结
达摩院 2020 预测:感知智能的“天花板”和认知智能的“野望”
十大新兴前端框架大盘点
联盟链走向何方
拿下微软、Google、Adobe,印度为何盛产科技圈 CEO?

你点的每个“在看”,我都认真当成了AI