异类框架BigDL,TensorFlow的潜在杀器!

作者 | Nandita Dwivedi
译者 | 风车云马
责编 | Jane
出品 | AI 科技大本营(id:rgznai100)
【导读】你能利用现有的 Spark 集群构建深度学习模型吗?如何分析存储在 HDFS、Hive 和 HBase 中 tb 级的数据吗?企业想用深度学习模型,可是要考虑的问题又很多,怎么破?这篇文章中,我们将给大家讲讲大数据+深度学习下,BigDL 框架的利弊与应用教程,为什么有了 TF、PyTorch,还是会考虑用 BigDL?
为什么要讲 BigDL?
这几年,曾被称为 “3S”,因其简单、快速并支持深度学习的 Apache Spark 非常流行。许多公司利用 Hadoop 和 Spark 环境来构建强大的数据处理 pipeline,对分布式集群上的大量数据进行预处理,并从中挖掘出业务提升的新观点。现在许多公司都希望能利用深度学习的模型帮助自己进一步改善业务。虽然深度学习模型的性能在不断提高,但是想要在现有的平台上部署新技术也还有很多问题需要权衡,比如:
(1)如果用深度学习的方法,还可以利用原有的 pipeline 吗?
(2)当深度学习遇到大规模数据集时,“大规模深度学习”如何能保证其有效性?
(3)基于现有的 Spark / Hadoop 集群是否可以用?
为什么要权衡这些问题其实不难理解,我们需要保持一致的环境,避免大型数据集跨不同集群之间的传递。此外,从现有的基础设施中移动专有数据集也有安全风险与隐患。早期时解决这些问题的方法是在 Spark 上直接加入深度学习框架,但并不能保证保持它们之间的一致性,因此,后来产生了基于 Spark 的 BigDL 平台,其继承了 3S 的主要特点:简单、快速、支持深度学学习。

提到 BigDL 框架,也许大家对他的熟悉度不高,下面我们就先为大家简单的介绍一下什么是 BigDL 框架。
BigDL 是一个分布式的深度学习框架,在大数据分析领域发展迅速,并且也是一个开源的框架。BigDL 有很多特点,比如:与 Spark 和 Hadoop 生态系统进行了完整集成,具有可拓展性等很多重要的功能。可根据数据大小在任意集群中训练模型、支持构建端到端的大数据分析与深度学习等 pipeline、可执行数据并行分布式训练,实现高可扩展性。BigDL 用户可在 Spark 和大数据平台上构建了大量数据分析与深度学习的应用,如视觉相似性、参数同步、比例缩放等。
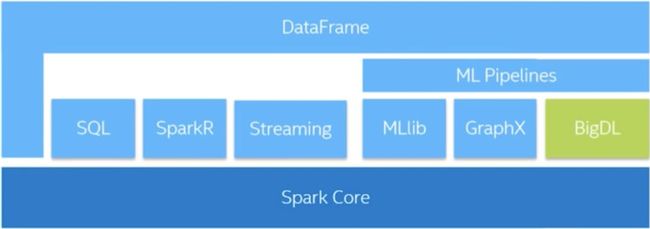
深度学习应用程序可以编写为标准的 spark 库。这些 Spark 框架中统一的库可以读取大量数据。此外,它还支持 Numpy、Scipy、NLTK、Pandas 等 Python 库;与 TensorBoard 集成用于可视化分析;支持加载现有的 Torch 模型。企业客户使用 BigDL 和Spark 还有一个重要的原因,相比 TensorFlow,BigDL 不仅更快,通过并行计算它能够更快地重新训练模型。
分享一位网友对 BigDL 的总结:
BigDL相对于其他主流的深度学习框架(TensorFlow/Caffe/PyTorch),算是一个异类。其异有二:(1)CPU、(2)纯分布式(Spark)
虽然业界普遍不看好CPU跑深度学习,但实际上还是有需求的。比如,现有Hadoop集群的公司,复用现有集群来跑深度学习是最经济的方案。
并且,充分优化后的CPU集群的性能还是挺可观的。拿BigDL来说,MKL + 多线程 + Spark,充分发挥了分布式集群的优势 。尤其是在Inference方面,堆CPU的方案在性价比上很可能是优于GPU的,毕竟Nivdia的计算卡是很昂贵的。
另外,数据挖掘以及Information Retrieval等领域中常用的神经网络结构一般都比较浅,多为稀疏网络,也很少用到卷积层。GPU并不十分擅长处理这样的网络结构。
考虑到实际的生产环境,跑在Spark上的BigDL背后有整个Spark/Hadoop大生态的支持。配合近期很火的SMACK技术栈,可以很轻松愉快的构建端到端的生产级别的分布式机器学习流水线。由于没有异构集群数据传输的开销,从端到端这个层面来看,CPU方案的性能反而可能占优。
最后,谈谈可用性,BigDL项目正在快速的迭代中。语言层面支持Scala/Python。API方面有torch.nn风格的Sequenial API,也有TensorFlow风格的Graph API,以及正在开发的keras API。Layer库也很齐全,自定义Layer也很方便。兼容性方面,BigDL兼容了Caffe/Torch/Keras,以及部分TensorFlow模型。换言之,你可以把用TF/Caffe训练的模型,导入BigDL做Inference。反之,亦可。这是一个非常有用的Feature。
综上,BigDL虽然并不主流,但在很多场景下是有成为"大杀器"潜质的,包括但不限于:
已有大规模分布式集群的(如: Hadoop集群)
需要大规模Inference的,比如:推荐系统、搜索系统、广告系统
(上下游)依赖Spark/Hadoop生态的
轻度深度学习使用者,如:数据研发工程师/数据挖掘工程师
Scala/JVM爱好者
作者:AlfredXXfiTTs
https://www.zhihu.com/question/54604301/answer/338630738
Analytics Zoo 分析库
和 Python 生态系统中庞大的标准或三方库相比,Spark 明显还处于起步阶段。Keras、TensorFlow 和 PyTorch 等大多数库都还不能与 Spark 兼容,因为它们不支持Spark 分布式计算的底层核心框架。那要如何弥补这一不足呢?这里为大家介绍一个英特尔开发的分析工具——Analytics Zoo,它提供了一组丰富的高级 API 可以将BigDL、Keras 和 TensorFlow 程序无缝集成到 Spark 的 pipeline 中;还有几个内置的深度学习模型,可用于对象检测、图像分类、文本分类等。该库还提供端到端的参考用例,如异常检测、欺诈检测和图像增强,以将机器学习应用于实际问题。
为了帮助大家能更具体、实际的理解这个工具的一些功能与用法,下面分享一个关于 BigDL 和 Analytics Zoo 的简短教程,向大家展示如何使用预先训练好的模型实现迁移学习,并在 Spark 集群上进行训练。
教程实践
数据集:ResNet-50,包含蚂蚁和蜜蜂图像的小数据集来实现迁移学习。
预训练模型:可以将给定的图像在 1000 个标签中进行分类;
模型训练与预测:特定用例通过迁移学习重新训练模型,对包含蚂蚁和蜜蜂的训练集进行预测。BigDL 和 Analytics Zoo 支持在 Spark 的分布式框架上进行训练。(注意,最初的 ResNet-50 标签中没有“蚂蚁”和“蜜蜂”。)

使用 pip 即可安装 BigDL 和 Analytics Zoo,如下所示:
#for Python3
pip3 install BigDL
pip3 install analytics-zoo
安装之后,在开始之前先下载 ResNet 50 的预训练模型、训练与测试数据集。数据包需要解压缩。使用 Analytics Zoo 中的 init_nncontext 函数导入并初始化 Spark,然后定义预训练模型、训练与测试数据集的路径。
import os
from bigdl.nn.criterion import *
from bigdl.nn.layer import *
from bigdl.optim.optimizer import Adam
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.sql.functions import col, udf
from pyspark.sql.types import DoubleType, StringType
from zoo.common.nncontext import *
from zoo.feature.image import *
from zoo.pipeline.nnframes import *
sc = init_nncontext("TransferLearningBlog")接下来,创建 Spark UDF 来提取文件名称。标签是通过检查文件名称是否包含关键字“ants”或“bees”来分配的。使用这两个 udf,构造训练和测试数据集。
# Define udfs to extract filename and generate labels in floats
getFileName = udf(lambda row: os.path.basename(row[0]), StringType())
getLabel = udf(lambda row: 1.0 if 'ants' in row[0] else 2.0, DoubleType())
# Construct training dataframe
trainingDF = NNImageReader.readImages(train_path, sc, resizeH=300, resizeW=300, image_codec=1)
trainingDF = trainingDF.withColumn('filename', getFileName('image')).withColumn('label', getLabel('image'))
# Construct validation dataframe
validationDF = NNImageReader.readImages(val_path, sc, resizeH=300, resizeW=300, image_codec=1)
validationDF = validationDF.withColumn('filename', getFileName('image')).withColumn('label', getLabel('image'))为了正确构建模型,需要对所有图像进行标准化。Analytics Zoo 有 API 来操作转换、链接等,使后面可以按顺序进行处理。
如下所示,加载预训练 ResNet-50 模型
# Create a chained transformer that resizes, crops and normalizes each image in the dataframe
transformer = ChainedPreprocessing(
[RowToImageFeature(), ImageResize(256, 256), ImageCenterCrop(224, 224),
ImageChannelNormalize(123.0, 117.0, 104.0), ImageMatToTensor(), ImageFeatureToTensor()])
# Load pre-trained Resnet-50 that was downloaded earlier and give the column to pick features from
preTrainedNNModel = NNModel(Model.loadModel(model_path), transformer) \
.setFeaturesCol("image") \
.setPredictionCol("embedding")
# Print all layers in Resnet-50
for layer in preTrainedNNModel.model.layers:
print(layer.name())ResNet-50 的最后 5 层是:
res5c_relu
pool5
Viewf42780f5
fc1000
prob模型的最后一层的输出是 2 个类(蚂蚁、蜜蜂),而不是ResNet-50训练的1000个类。该模型的输入维数为 1000,输出维数为 2。通过迁移学习,该模型可以在 25 步内完成这两个新类的训练!这一点也说明了迁移学习的实用性。
# Create a last layer with input dimension of 1000 that outputs 2 classes of ants and bees
# Epochs are set to 25 and the optimizer is SGD
lrModel = Sequential().add(Linear(1000, 2)).add(LogSoftMax())
classifier = NNClassifier(lrModel, ClassNLLCriterion(), SeqToTensor([1000])) \
.setOptimMethod(SGD(learningrate=0.001, momentum=0.9)) \
.setBatchSize(4) \
.setMaxEpoch(25) \
.setFeaturesCol("embedding") \
.setCachingSample(False)
# Change the last layer in the pipeline
pipeline = Pipeline(stages=[preTrainedNNModel, classifier])
现在,开始训练和测试模型。Spark 允许跨多个集群进行更快的训练。
# Train the model and get predictions on the validation set
antbeeModel = pipeline.fit(trainingDF)
predictionDF = antbeeModel.transform(validationDF).cache()
predictionDF.sample(False, 0.1).show()
# Evaluate predictions
evaluator = MulticlassClassificationEvaluator(
labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictionDF)
# expected error should be less than 10%
print("The Test Error is = %g " % (1.0 - accuracy))最后,对测试数据进行分类,显示图像。
# Test dataframe
testDF = NNImageReader.readImages(test_path, sc, resizeH=300, resizeW=300, image_codec=1)
testDF = testDF.withColumn('filename', getFileName('image')).withColumn('label', getLabel('image'))
testPredDF = antbeeModel.transform(testDF).cache()
row = testPredDF.first().asDict()
# showImage function
def showImage(row):
# Open file
plt.imshow(Image.open(row['image'][0][5:]))
# Map prediction to class
title = 'ants' if row['prediction'] == 1.0 else 'bees'
plt.title(title)
showImage(row)测试数据分类结果的图像显示:

如果数据集比较大,恰好存储在 HDFS 中,也可以使用相同的方法,将其扩展到更大的集群上。正是 BigDL让这些大数据集的数据分析更加快速和高效。除此之外,它还可与 Spark SQL 和结构化数据紧密耦合。例如,Kafka 数据可以直接传递给 BigDL UDF,进行实时预测和分类。
原文链接:
https://medium.com/sfu-big-data/when-deep-learning-got-big-a833a69be460
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
大会开幕倒计时6天!
2019以太坊技术及应用大会特邀以太坊创始人V神与众多海内外知名技术专家齐聚北京,聚焦区块链技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。即刻扫码,享优惠票价。

推荐阅读
华为最强自研NPU问世,麒麟810“抛弃”寒武纪
真正的博士是如何参加AAAI, ICML, ICLR等AI顶会的?
Python最抢手、Java最流行、Go最有前途,7000位程序员揭秘2019软件开发现状
程序员学Python编程或许不知的十大提升工具
不要让 Chrome 成为下一个 IE!
这位博士跑赢“地震波”:提前 10 秒预警宜宾地震!
一张图告诉你到底学Python还是Java!
鸿蒙将至,安卓安否?
25岁创立加密城堡, 曾经独角兽创始人社会名流天才黑客是这里的沙发客, 如今却无人问津……
352万帧标注图片,1400个视频,亮风台推最大单目标跟踪数据集
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢