避坑指南:如何选择适当的预测评价指标?| 程序员评测

作者 | Nicolas Vandeput
译者 | Tianyu
责编 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】因为不存在一个适用于所有情况的评价指标,所以评估预测精度(或误差)就变成了一件不是那么容易的事情。只有通过试验,才能知道哪个性能评估指标适用于当前情况。在这个过程中,你会发现每个指标都可以避开某些陷阱,但同时也容易掉进其他陷阱。今天,我们就把几大预测评价指标一一为大家分析对比,从而对它们的适用情况更了解。
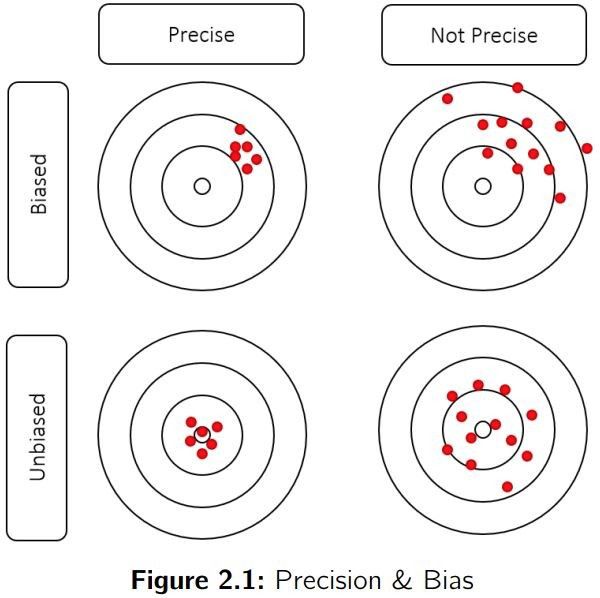
先了解一下预测的准确率和偏差:
偏差(Bias)指历史平均误差。你的预测结果对于平均值来说,过高还是过低?偏差展示了误差的整体趋势。
准确率(Precision)可以评估你的预测值与实际值之间的误差。预测结果的准确率可以揭示误差的大小幅度,但无法体现其整体趋势。
当然,如下图所示,我们想要的预测结果是既有高准确度,又没有偏差。
下面,会讲到五种指标,从它们的定义开始,然后再对比它们的适用与不足。
0、Error(误差)
首先对 error 进行定义,即预测值减去实际值。如果预测值高于实际值,那么误差为正,若低于实际值,则误差为负。
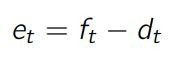
预测性能的评估指标有哪些?
1、Bias
Bias 的定义为误差的平均值。此处,n 为历史的时刻数,即预测值与实际值的个数。
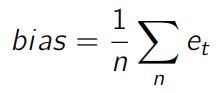
由于一个正误差可能会抵消掉另一个负的误差,因此预测模型可能会得到很低的 bias,而精度却很低。很明显,只使用 bias 不足以对预测精度进行评估。
2、MAPE
平均绝对百分误差(MAPE,Mean Absolute Percentage Error)是评估预测精度的最常用指标之一。MAPE 为每个绝对误差的和除以实际值。实际上,它是误差百分率的平均值。
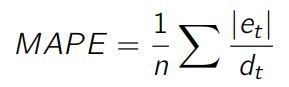
MAPE 是个很奇特的性能评估指标。由公式可以看出,MAPE 用每个误差值除以实际值,所以会产生倾斜:若某个时刻的实际值很低,而误差很大,就会对 MAPE 的值产生很大影响。因此,对 MAPE 的优化会导致奇怪的预测结果,很可能会使预测值低于实际值。
3、MAE
绝对平均误差(MAE,Mean Absolute Error)是一个很好的预测评估指标。如名字所描述的,它是绝对误差的平均值。

MAE 的第一个缺点是,它没有考虑到实际值的平均数。如果有人告诉你某个预测结果的 MAE 为 10,你无法知道这个结果是好是坏。如果实际值的平均数为 1000,当然这个预测精度是很不错的,但如果实际值平均为 1,这个预测的精度实在太低了。为了解决这个问题,可以用 MAE 除以实际值的平均数,得到一个百分率:
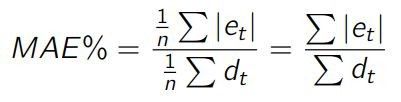
MAPE/MAE 混淆 —— 很多人会使用 MAE 的公式,却把它当成 MAPE。很多人会对此存在混淆。当我和别人讨论预测误差时,我会要求其明确解释预测误差是如何计算的,以免发生混淆。
4、RMSE
均方根误差(RMSE,Root Mean Squared Error)是一个看似不合理却很实用的指标,稍后我们会进行详细解释。它的定义为误差平方平均值的方根。
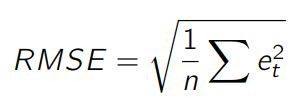
和 MAE 一样,RMSE 没有考虑到实际值的大小范围。我们同样可以定义一个 RMSE%,如下:
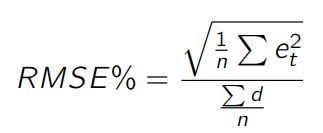
实际上,许多算法(特别是机器学习算法)都是基于均方误差的(MSE,Mean Squared Error):
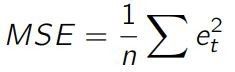
MSE 被许多算法使用,因为它计算速度快,且比 RMSE 更容易操作。但它没有考虑到原误差值(因为误差被做了平方计算),可能导致指标无法关联到原始误差值的大小范围。因此,我们不常用它作为评估预测模型精度的指标。
MAE vs RMSW:误差权重
与 MAE 相比,RMSE 对每个误差值不是平等对待的,它会给大的误差更大的权重。这意味着一个过大的误差值会让 RMSE 值很差。
我们来看一个虚构的时间序列:

现在我们对比两个预测结果,这两个结果存在的唯一差别是最后一个预测值:预测 #1 比实际值低 7 个单位,预测 #2 低了 6 个单位。

两次预测结果的性能评估指标如下:
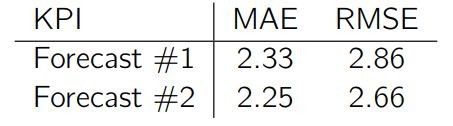
有趣的是,只把最后一次预测的值改变了 1 个单位,就导致整体的 RMSE 值降低了 6.9%(从 2.86 到 2.66),但 MAE 值只降低了 3.6%(从 2.33 到 2.25)。很明显,RMSE 把更大的注意力放在最大的误差值上,而 MAE 给每个误差值相同的权重。你可以自己尝试降低某个误差值,会发现对 RMSE 几乎不会产生影响。
接下来你会看到关于 RMSE 更有趣的特性。
RMSE 的预测实例
刚刚我们介绍了每个性能评估指标的定义(bias、MAPE、MAE、RMSE),但还不清楚它们使用在模型上的差异。有人可能认为用 RMSE 代替 MAE,或者用 MAE 替代 MAPE,不会有太大差异,但事实上不是这样的。
我们来看个简单的例子。假设某个产品每周的销量始终比较低且平稳,偶尔会有一笔大订单(可能受促销活动等影响)。下面是我们观察到的最近几周的销量情况:
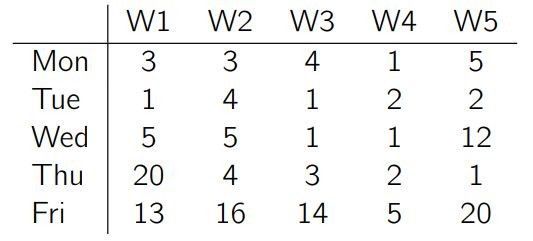
对于该产品的销量,我们虚构三个不同的预测结果。第一个预测每天销量为 2,第二个预测每天销量为 4,第三个预测每天销量为 6,如下图所示:

我们看看每个预测的 bias、MAPE、MAE 和 RMSE 结果:
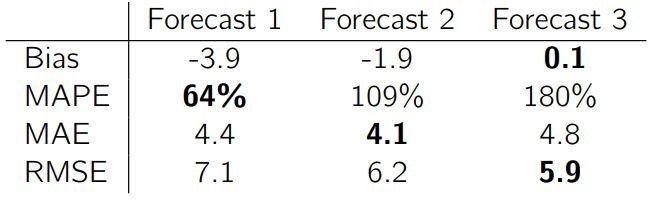
预测 #1 基于 MAPE 表现最好,预测 #2 基于 MAE 表现最好,预测 #3 基于 RMSE 和 bias 表现最好(但基于 MAE 和 MAPE 表现最差)。下面我们来看每个预测结果的组成:
预测结果 #1 取了一系列较低的值
预测结果 #2 为实际值的中位数
预测结果 #3 为实际值的平均数
中位数 vs 平均数 —— 数学最优化
在进一步讨论不同的预测性能评估指标之前,我们花点时间来了解为什么以中位数作为预测值会得到较好的 MAE,以及用平均数作为预测值会得到较好的 RMSE。
这里会涉及一些数学知识,如果你对这些公式不理解,不要在意。你可以略过这部分,直接跳到 RMSE 和 MAE 的结论部分。
1、RMSE
首先来看 RMSE:

实际上,我们可以用它的简化版,即 MSE:
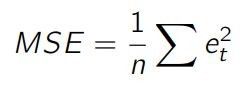
如果你的预测模型把 MSE 当作指标,它会将其最小化。我们可以通过使其导数为零,来将数学函数最小化:
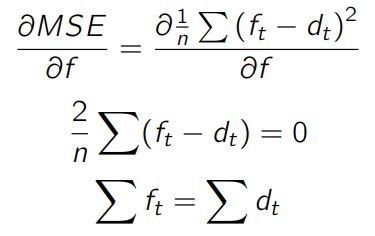
若要使预测最优化,模型会趋于让整体预测值与实际值相等。
2、MAE
接下来,我们对 MAE 做同样的分析:

或者
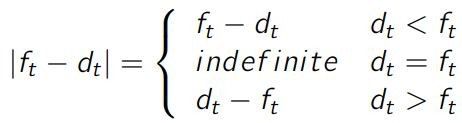
以及
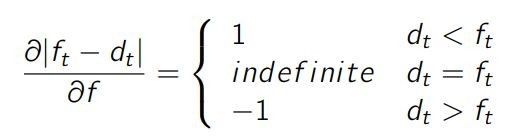
这意味着
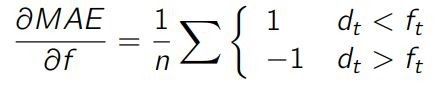
若要使 MAE 最优化(如,使其导数为零),预测模型要让预测值高于实际值的次数等于低于实际值的次数。换句话说,我们希望找到一个值可以把数据集一分为二,这也正是中位数的定义。
3、MAPE
遗憾的是,MAPE 的导数不具备直接明了的特性。我们可以简单认为,MAPE 会优先给出较低的预测值,因为当实际值比较低时,预测误差会被分配较高的权重。
结论
综上所述,在任何模型上,对 RMSE 的最优化是试图找到平均值,而 MAE 的最优化是让预测偏高的次数与偏低的次数相等。不得不承认,MAE 和 RMSE 在数学本质上存在较大的差异。一个瞄准中位数,另一个瞄准平均数。
MAE 还是 RMSE?如何选择?
我们不能说瞄准中位数好或者瞄准平均数好,这不是一个非黑即白的问题。每项技术都存在优点和隐患,下面我们会讨论这个问题。只有经过试验,才能知道哪项技术适用于当前的数据集。你甚至可以同时选择 RMSE 和 MAE。
下面我们花点时间,来讨论选择 RMSE 或 MAE 对偏差值、异常值灵敏度以及无规律序列的影响。
Bias
对于许多实例,你会发现实际值的中位数与平均数不同。可能发生的是,实际值中存在一些峰值,导致整体分布产生偏移。这些偏移的分布在供应链行业常常发生,因为定期的促销活动或客户的批量采购。这会使实际的中位值比平均数低,如下图所示:
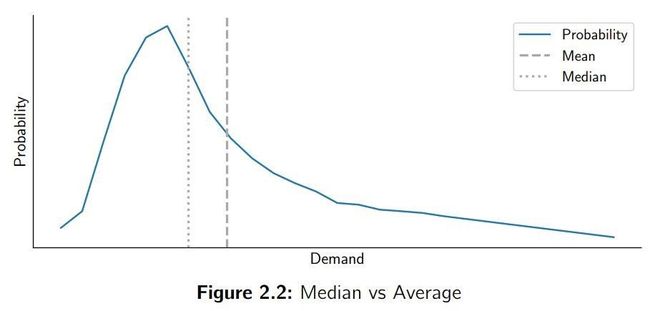
这说明预测模型在使 MAE 最小化时会产生偏差,然而在使 RMSE 最小化时不会产生偏差(因为它瞄准的是平均数)。这确实是 MAE 的主要缺陷。
异常灵敏度
如我们所讨论的,RMSE 会为大的误差值分配高权重,同时也要付出代价:对异常点过于敏感。我们看下面的例子:
若一个序列的中位值为 8.5,平均值为 9.5。我们已经知道,如果模型使 MAE 最小化,我们会预测出中位数(8.5),这样整体会比平均数低 1 个单位(bias = -1)。之后你可能会选择对 RMSE 做最小化,预测平均值来避免这种情况。
不过,如果我们突然观察到一个值为 100:

中位数仍然为 8.5,并没有发生改变,但平均值变成了 18.1,在这种情况下,我们不希望预测结果趋近于平均数,而是重新使用中位数。
一般来说,对于存在异常值的情况,中位数比平均数的鲁棒性更强。在供应链产业中,这一点尤为重要,因为我们要面对很多异常点。
对于异常点来说,鲁棒性总是一个好的特性吗?答案是否定的。
无序序列
糟糕的是,在异常点存在的情况下,中位数的鲁棒性可能会对无规律的序列产生非常不好的影响。
试想我们对一个客户出售产品,该产品的利润很高,客户似乎每三个星期中会有一个星期下订单。遗憾的是,客户的购买行为没有任何规律。我们可以观察到其平均数为 33,但而中位数为 0。
我们不得不对该产品做每个星期的预测。试想,我们让预测模型瞄准平均数(33),经过一段时间,我们得到的总平方误差为 6667(RMSE 为 47),总绝对误差为 133(MAE 为 44)。

如果我们让预测模型瞄准中位数(0),我们得到的总绝对误差为 100(MAE 为 33),总平方误差为 10000(RMSE 为 58)。
很明显,对于没有规律的序列,MAE 是一个比较差的性能评估指标。
结论
MAE 会忽略异常值,而 RMSE 会注意到异常值并得到没有偏差的预测。那么应该使用哪个指标呢?很遗憾,不存在确定的答案。如果你是一名供应链领域的数据科学家,你应该多做试验:如果使用 MAE 作为性能评估指标会得到很大偏差,你可能需要使用 RMSE。如果数据集包含很多异常值,导致预测结果产生偏移,你可能需要用 MAE。
还需要注意的是,你可以选择一个或多个评估指标(如 MAE&bias)来计算预测的误差,然后用另一个指标(RMSE?)来对模型进行优化。
还有最后一个技巧,面对实际值较低的序列,可以将其聚合到一个更大的时间范围。例如,如果以星期为周期的值很低,你可以试试按照月份来进行预测,甚至按季度预测。你也可以通过简单的除法,把原始时间序列分解到较小的时间范围上。这一方法可以帮助你更好地使用 MAE 作为评估指标,同时对峰值做平滑处理。
原文链接:
https://medium.com/analytics-vidhya/forecast-kpi-rmse-mae-mape-bias-cdc5703d242d
(*本文为 AI科技大本营编译文章,转载请联系 1092722531)
◆
精彩推荐
◆
“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。目前,大会早鸟票抢购中~扫码购票,领先一步!

推荐阅读
阿里达摩院做AI这两年
性能比GPU高100倍!华人教授研发全球首个可编程忆阻器AI计算
豪投10亿!华为放话:3年培养100万AI人才!网友神回应了
《长安十二时辰》教了哪些算法知识?
非科班出身程序员,如何超越科班程序员?
谷歌停止中国版搜索引擎;李楠宣布离职魅族;微软用 Rust 替代 C/C++ | 极客头条
首批8款5G手机获3C认证:华为占4款;IBM获AT&T“几十亿美元”云计算合同;马库斯:未来薪酬将以Libra发放
用50年前NASA送阿波罗上天的计算机挖矿什么体验? 出一个块要10^18年……
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢