springboot与检索


elasticsearch的安装:
[root@localhost docker]# docker pull elasticsearch
这种方式下载一般会很慢,或者直接卡死,我们可以使用阿里云的镜像加速服务
您可以通过修改 daemon配置文件 /etc/docker/daemon.json 来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https:aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
ES镜像的运行
[root@localhost ~]# docker run -d -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name ES1 c71178df2dd5
- -e ES_JAVA_OPTS="-Xms256m -Xmx256m"
- 因为 elasticsearch是java实现的,默认初始会2G大小的堆内存,虚拟机内存不足的话会启动报错,所以我们通过-e添加参数进行堆内存大小的限制.-Xms是初始的堆内存大小,-Xmx是最大的堆内存使用.
- 默认进行web通信时使用的是9200端口,分布式的情况下,elasticsearch各个节点之间的饿通信需要使用的是9300端口,所以,我们需要做两个端口映射.
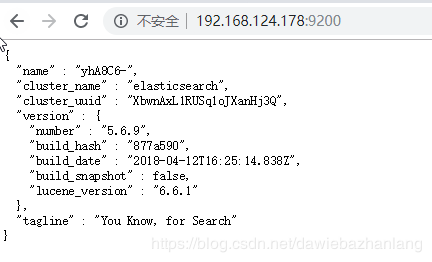
启动成功后,可以在浏览器进行访问:
ES的快速入门
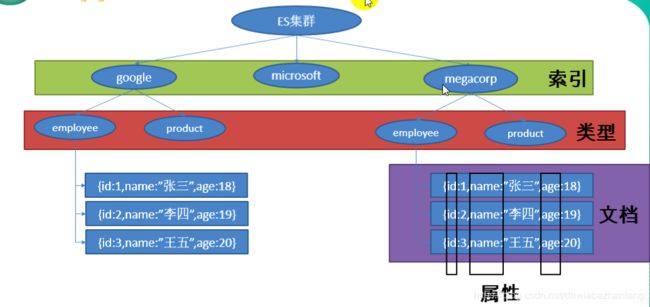
- 索引: 给ES存储数据的行为,称为索引,其实就是存储的意思

springboot整合ES
springboot默认是使用springdata整合ES的.也支持使用jest操作ES
使用jest整合ES
1.导入依赖
<dependency>
<groupId>io.searchboxgroupId>
<artifactId>jestartifactId>
<version>5.3.3version>
dependency>
2.配置主机和端口
spring:
elasticsearch:
jest:
uris: http://192.168.124.127:9200
- 开始测试
@Autowired
JestClient jestClient;
@Test
public void contextLoads() throws IOException {
//给ES中索引 (保存) 一个文档
Article article = new Article();
article.setAuthor("zhangsan");
article.setId(1);
article.setTitle("好消息");
article.setContent("hello world");
//创建一个索引,然后把article索引到ES中的atguigu索引中.
//构建一个索引功能
Index index = new Index.Builder(article).index("atguigu").type("news").build();
//执行
jestClient.execute(index);
}
/**
* 使用jest进行搜索功能,以全文搜索为例
*/
@Test
public void search() throws IOException {
//构建查询规则
String json = "{\n" +
" \"query\" : {\n" +
" \"match\" : {\n" +
" \"content\" : \"hello\"\n" +
" }\n" +
" }\n" +
"}";
//构建搜索
Search search = new Search.Builder(json).addIndex("atguigu").addType("news").build();
//执行搜索并且获取搜索结果
SearchResult result = jestClient.execute(search);
System.out.println(result.getJsonString());
}
Jest的文档
使用springdata整合ES
- 导入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
- 配置节点名称和节点通信端口
spring:
data:
elasticsearch:
cluster-name: elasticsearch # 节点名称
cluster-nodes: 192.168.124.127:9300 # 节点间进行通信的端口
- 更换版本
启动之后会报错
org.elasticsearch.transport.ConnectTransportException: [][192.168.124.127:9300] connect_timeout[30s]
这个错误主要是,由于我们那个springboot的版本和elasticsearch的版本比匹配导致的,解决方案有两种,第一种是 给springboot版本升级,(但是一般升级后也可能还是不匹配),第二种就是更换低版本的elastic.[版本匹配参考],(https://github.com/spring-projects/spring-data-elasticsearch),我们可以对自己的pom问价那种的elastic和springdata的版本分析之后,决定到底是升级还是降级
运行低版本的ES镜像
[root@localhost ~]# docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9201:9200 -p 9301:9300 --name ES2 5e9d896dc62c
- 测试
用法可以参考官方文档
两种用法:
* 1. 编写一个ElasticSearchRepository接口的子接口
* 2. ElasticSearchTemplate 操作ES
1.编写接口
//该接口有两个泛型,ElasticsearchRepository2,编写实体类
//@Document的作用就是用来指定实体类将要被存储的索引名称和类型
@Document(indexName = "atguigu" , type = "book")
public class Book {
private Integer id;
private String author;
private String bookName;
}
3 测试类
@Autowired
BookRepository bookRepository;
@Test
public void test02(){
Book book = new Book();
book.setId(1);
book.setAuthor("刘猛");
book.setBookName("我是特种兵");
bookRepository.index(book);
}
@Test
public void test03(){
for (Book book : bookRepository.findBookByBookNameLike("我")) {
System.out.println(book);
}
}
4 访问结果