2020-ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes-结合图像投票提升点云3D检测

1. 摘要
这篇文章的第一作者是Charles R. Qi,同时也是PointNet,PointNet++,Frustum PointNets和VoteNet的一作,代码目前没有开源。之前进行室内3D检测的SOTA算法VoteNet只使用了point cloud,而point cloud具有以下劣势,点云稀疏,缺少颜色信息,而且数据包含传感器噪声。相对而言,images具有更高的分辨率以及丰富的纹理信息,因此图像可以辅助点云进行3D detection,难点在于如何有效结合。这篇论文基于VoteNet框架,提出了一个专门针对RGB-D场景的3D检测算法框架ImVoteNet,融合了image上的2D Votes和point cloud的3D Votes。和之前进行多模态检测的工作相比,该论文显式地从2D image中提取几何和语义特征,并结合相机内参将这些特征提升至3D空间。为了提高2D-3D特征融合效果,作者还提出了一个multi-tower训练框架。ImVoteNet在SUN RGB-D数据集上达到了SOTA,比之前SOTA的VoteNet又提高了5.7mAP。
2. 简介
19年提出的VoteNet在室内3D检测任务上达到了SOTA,但这是否到极限了呢,是否存在一种有效方式结合RGB image来提升效果?通过分析point cloud和image数据,可以看出RGB image和point cloud之间存在互补关系,因此可以肯定image能够辅助point cloud带来效果提升。RGB image相比与depth image或者Lidar data具有更高的分辨率,包含丰富的纹理信息,而且images可以覆盖blind regions,这些区域由于反光等原因无法由depth sensors获取数据;另一方面,images缺乏绝对深度和尺度,而这些由point cloud可以提供。
如何结合image和point cloud是关键。一种直观的方式是将原始RGB值附加到点云上,通过投影可以得到point-pixel的一一对应。然而,由于3D点太稀疏了,这样做会丢失image空间的稠密特性。基于此,涌现了一些较为高级的方式来融合2D和3D数据。一类方法借助成熟的2D detectors来提供frustum point clouds,能够极大减少进行3D包围盒估计的3D检索空间。然而这种层叠式设计给出的初始proposals没有考虑3D信息,如果2D detectors检测不出物体,那么不会进行后续的3D detection。另外一类方法采用3D为主的方式,将从2D images中抽取的ConvNet特征concatenate到3D voxels或者points上,之后再生成候选以及回归3d bboxes。然而,这类方法没有直接基于2D image进行定位,不能为3D detection提供有效的guidance。
3. 方法概述
该论文提出了ImVoteNet,基于VoteNet使用一种联合的2D-3D投票框架进行3D检测。算法利用了成熟的2D detectors,也保留了从完整的点云进行推断物体的能力,并且是避免了各自的缺陷。
设计算法时主要考虑的是如何有效利用2D image中的几何、语义及颜色信息。其中,几何信息:给定2D BBox,可以获取2D votes,如图1,也即从当前像素指向物体中心像素,之后结合相机内参和像素的深度值,将2D votes提升到3D,产生伪3D Votes,进而附加到3D点上进行生成后续的proposals;语义信息:one-hot向量给出物体类别;颜色信息:三维的RGB信息。这些从images获取到的所有features,将会concatenate到由pointnet++获得的3D seed point featurs上。
图1:使用室内场景的image和point cloud共同进行投票。2D vote将物体3D中心的搜索空间简化为一条射线。
基于联合后的features,仿照VoteNet框架生成3D Hough Votes,再生成最后的3D bboxes。由于seed features包含了2D和3D信息,因此在本质上携带了更多的信息来回归遮挡或者点数目少的物体,而且在处理几何近似物体时更为有效。
另外,作者还发现,进行融合2D和3D信息时,必须很小心地平衡两者,以避免单源信息占主导。因此作者引入了一个使用梯度混合的multi-towered网络结构,确保能够最大化地利用2D和3Dfeatures。在测试时,只有主要的tower作用于联合的2D-3D特征,能够最小化在效率上的牺牲。
算法的整体流程如图2所示:
图2:ImVoteNet算法的3D检测流程。给定RGB-D输入,算法包含两个分支,一个分支进行2D detection,一个分支进行point cloud的feature抽取。之后,将image中抽取的geometric,semantic以及texture cues提升到3D,附加于seed point features。联合后的seed points生成指向3D物体中心的投票,进而估计3D BBoxes。为了使多模态融合更为有效,作者使用了另外2个towers分别输入图像特征和点云特征进行投票和box的回归。
后面章节进行如下介绍:3.1介绍VoteNet,3.2介绍从2D检测获取的image votes,3.3介绍特征融合以及multi-tower训练。4介绍实验,其中4.1和4.2介绍和当前方法的对比,包括精度以及图示结果,4.3介绍ablation study,4.4介绍处理sparse point cloud时的情况。最后5对全文进行总结。
3.1 VoteNet简介
对应论文为《Deep Hough Voting for 3D Object Detection in Point Clouds (VoteNet)》,代码开源。受通用Hough变换的启发,作者提出了一种基于深度学习进行3D检测的投票框架,其主要框架如图3,也就是图2的下半部分。VoteNet在室内数据集SUN RGB-D上达到了SOTA,但没有利用图像信息。
图3:VoteNet结构展示:给定一个具有N个点(包含坐标XYZ)的点云作为输入,使用Backbone网络(PointNet++)进行下采样,并且对每一个点学习深度特征,得到M个点,每个点具有(3+C)维特征;这M个点作为种子点;通过一个投票模块,每一个种子点都独自产生一个投票点,得到新的M个点,每个点具有新的(3+C)维特征;之后,这M个点被聚类成K个类别,然后通过一个聚合模块产生K个建议框;最后,通过3D的NMS(非极大值抑制)得到最终的K’个3D包围盒。
3.2 从2D检测获取的Image Votes
作者根据2D detectors产生的一些candidate boxes产生image votes,一个image vote是一个向量,由当前图像像素位置指向2D BBox的中心,如图1所示。这里默认的是,由相机系中心经过2D bbox中心的射线,一定经过物体3D BBox的中心。除了image vote,每一个像素还会额外增加semantic cues和texture cues,最终具有F’维特征,如图2所示。
作者采用了现成的2D detector(Faster R-CNN),在RGB-D数据集的RGB通道上训练。检测器能够产生M个最有可能的2D bboxes,以及每个bbox对应的class。每一个被检测到的bbox内部的像素都被赋予一个vote,指向bbox的中心。如果一个像素属于多个bboxes,那么该像素就被赋予多个votes(其对应的3D点被复制)。在任何bbox以外的像素点置为0。下面详细介绍image vote包含的geometric,semantic以及texture cues。
a. Geometric cues: 将image votes提升到3D空间
2D votes能够为3D物体的定位提供极其有用的几何线索。给定相机内参矩阵,由相机系中心经过2D bbox中心的射线,经过3D物体的中心。将这个信息附加于3D种子点后,能够有效将3D物体中心的搜素空间降至一维。
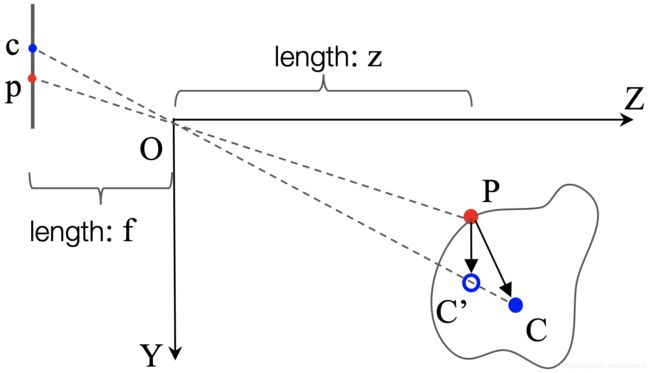
图4:伪3D投票点图示。P是物体上的一个3D点,C是未知的物体3D中心点,p和c分别是在图像平面对应的2D投影点。C’是伪3D投票点,vote向量是PC’。
具体如图4所示,给定3D空间的物体以及2D图像平面的bbox,使用C代表物体的3D中心点,其对应的2D投影点为c,使用P代表物体上某一3D点,其对应的2D投影点为p,如果已知由p到c的vote,那么可以将3D中心点的搜索空间降至射线OC。因此,我们需要考虑如何将射线信息抽取出来附加给3D seed point。
定义相机系下,P=(x1, y1, z1),图像平面坐标系下,p=(u1, v1), c=(u2, v2) ,我们想要恢复物体的真实中心C=(x2, y2, z2) ,也就是3D点P的vote目标点。由P到C的真值vote如下:
![]()
对于2D vote,假定使用简单的针孔模型,焦距为f,很容易得到以下变换:

之后,作者假定P点的深度和C点的深度近似一致。这也是合理的,如果物体距离相机没有那么近,那么物体上一点和物体中心点的深度应该是接近的。之后,给定z1≈z2,可以得到如下形式:
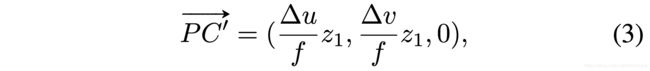
这也被称为伪3D vote,因为C’位于射线OC上,也是C的近似。这个伪3D vote提供了3D中心点相对于点P的相对位置。然而,PC’ 并不准确,直接将其作为geometric cues附加到3D seed point上不合适,因此,需要补偿由假定深度z1 ≈ z2带来的误差,于是,作者将OC射线的方向添加至PC’。下面介绍如何计算OC的方向。
沿着X轴或者Y轴方向的误差是由深度近似带来的,根据图4经过比例约束,可以得到如下:
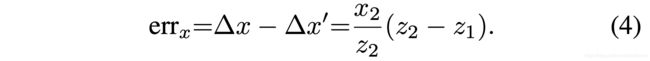
因此,如果我们给出射线OC的方向,也即得到了(x2/z2, y2/z2),那么式4中的左边就已知了,网络只需要估计深度差异∆z = z2 −z1。但由于我们不知道射线OC的方向,可以用OC’的方向代替,如下:

最后,经过归一化并且联合伪vote(式3),最终的image的geometric特征如式6,共包含5维,前两维值加上三个角度。

然而,式6没有考虑到相机的外参,SUN RGB-D数据集中的数据都包含外参矩阵,能够进行重力方向校正,使场景的重力轴和相机系y轴是平行,进而作为输入数据进行3D检测。因此,需要对伪3D vote进行变换。

图5:考虑外参的image vote。这里分别给出点P和点C在相机坐标系和竖直坐标系下的坐标(OY与重力方向平行)。其中PC是真值3D vote,PC’ 是根据式6计算的伪3D vote,而PC’’ 是最终进行特征融合时使用的变换后的伪3D vote。
图5展示了变换过程,由于输入的点云是竖直坐标系,点云深度神经网络只能估计出P和C在Zupright方向上的深度偏差,而不能估计出沿着相机坐标系Zcamera轴方向的偏差(由于网络不知道坐标系间的变换角度)。因此,需要计算一个新的伪3D vote,也即PC’’,其中C’'在射线OC上,PC’’ 垂直于OZupright。首先将PC’ 变换到PC’’,令变换到upright坐标系后的P和C’坐标分别为P=(xp, yp, zp),C’=(xc’, yc’, zc’),根据比例关系,可以得到新的伪3D vote的目标点为式8(第二维分母应是zc’)。
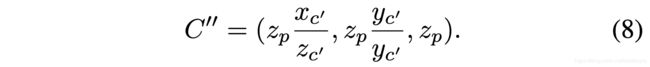
b. semantic cues
在geometric features中,只有利用了2D bboxes的空间关系,而RGB image提供的语义信息没有被使用。这个信息可以作为从3D点云中学习信息的补充,也能够辅助区分几何相似的不同类物体。基于此,作者也将这个语义信息提供给3D seed points,如果一个3D seed point的2D投影点位于某一个2D bbox内,那么将该2D bbox代表的区域语义特征赋予该3D点。如果一个3D seed point落在N个2D bbox内,那么复制N-1个点(小于阈值K)。如果一个3D seed point的投影点不落在任何一个2D bbox,那么传递一个全0的特征向量。
这里作者提出区域语义特征不限于复杂的深度学习特征,仅仅使用一个one-hot class vector足够包含在3D空间区分物体所需要的语义信息。使用one-hot vector不仅能够提供一个轻量的输入(该论文中仅为10维的向量),而且普适于通用的2D detectors(仅需要最后的分类得分)。因此,该论文使用了这种语义表示。
c. texture cues
Image的每个像素都具有颜色,这些低层次信息可以被利用,辅助3D检测。利用方式也很简单,每一个3D seed point都投影到2D空间,寻找最近像素点对应的RGB颜色,附加到该seed point的feature vector中。这里使用原始的RGB值,同样也带来了轻量级的输入,而且与2D networks无关。实验结果也验证了,尽管使用了如此简单的semantic cues和texture cues,和仅使用geometric cues的VoteNet相比,性能也得到了极大提升。
3.3 特征融合以及Multi-tower训练
如图2所示,基于image得到的image votes具有KxF’维,基于point cloud得到的seed points是KxF维,再加上3D坐标,共同构成Kx(3+F+F’)维特征,可以按照VoteNet框架(图3)产生K个vote points,再通过增强回归出3D BBox。然而,需要格外考虑如何优化网络结构,才能最大化多源信息。
在论文《 What makes training multi-modal networks hard?》中提到,如果缺乏一种精细的策略,多模态训练会导致效果下降,反而不如单模态训练。这是由于不同模态解决任务时会有不同的学习率,一些特定的features可能会主导整个学习过程,导致过拟合。在该论文中,作者使用了上述论文提出的梯度混合策略,赋予不同模态towers的梯度以不同的权重,通过加权损失函数来实现。
该论文的multi-tower实现如图2所示,包含三个towers,分别对应三种特征集合:只包含point cloud的feature,只包含image的feature,以及融合的feature。每一个tower都具有相同的检测3D物体的任务,但是他们每个都具有各自的3D投票和3D BBox回归的参数,也具有各自的losses。最终的训练loss是这三者检测loss的加权,如式7。
![]()
在图像tower中,仅使用image features不能定位3D物体,因此作者使用了3D点的几何信息以及相机内参来产生伪3D votes,这也是对于真值3D votes的较好近似。最终结合这个geometric cues,以及semantic cues和texture cues,能够定位3D空间的物体。
需要注意的是,虽然这种multi-tower结构带来了额外的参数,但是在推断时,不需要计算point cloud only tower和image only tower,因此计算开销并不大。
4. 实验
4.1 与当前方法对比
a. 基准数据集:
使用SUN RGB-D数据集,包含室内场景单视角下的~10K张RGB-D图像,其中~5K用于训练,每一个图像都标记了完整带朝向的(amodal oriented)3D bboxes,统共有37个类别。为方便对比,选择了10种最常用的类别进行模型训练和结果对比。为了提供point cloud network的输入,将depth images依据相机内参和用于重力方向校正的外参得到最终的point cloud,其中depth是和RGB对齐的。
b. 与相关工作对比
作者将ImVoteNet与之前的多项工作相比较。其中,层次化结合2D和3D的方法有 2Ddriven, PointFusion和F-PointNet,都依赖2D detectors来产生3D的proposals。Deep Sliding Shapes设计了一种3D空间的,类似FasterR-CNN风格的3D CNN network来产生3D proposals,并在其后结合3D和2D RoI特征估计3D box和识别物体。COG是一种利用类似3D HoG的特征进行滑动形状的检测器。
由于之前的SOTA(VoteNet)仅使用几何信息,因此作者通过引入额外的image features扩展VoteNet,增加了两个更强的baselines。第一个baseline只添加了RGB颜色信息,作为一个三维向量附加给3D seed points。第二个baseline增加了one-hot semantic vector,也添加到在2D box对应视锥体空间的3D seed point上。这两个baseline也可以看作是ablation versions。
和以上算法的定量对比结果如表1所示。

表1 在SUN RGB-D v1验证集上的3D物体检测结果。评估度量使用3D IoU=0.25时的平均精度。其中COG和2D-driven使用房间的layout context来提升效果。
表1展示了每一类物体的3D检测结果,可以看出ImVoteNet比之前的所有方法都要好一大截,而且比之前的SOTA VoteNet提高了5.7 mAP,这说明了将2D image votes提升到3D的有效性。ImVoteNet几乎在所有类别上都得到了更好的结果,而且在经常遮挡的类别如bookshelves上提升了12.5 AP,在几何相似的类别上如dressers提升了11.6 AP,如nightstands提升了7.7 AP。和基于VoteNet的两个变种相比,ImVoteNet也具有明显的优势,而且可以看出直接将RGB features添加到point features会得到更差的效果,或许是由于过拟合。增加用one-hot vector表示的区域特征能够带来提升,但提升非常有限。
4.2 定性结果与讨论
图6 定性结果展示图像信息的作用。第一行:bookshelf能够被检出,得益于2D detectors提供的线索;第二行:黑色的沙发几乎没有点,但由于2D信息的引入,也能够被检测出;第三行:由于引入了2d 位置和语义信息,黑色的desk和chair都能够被检测出,而其中一些真值都没有标出。
图6中给出了ImVoteNet和VoteNet的图示对比结果,展示了image信息如何帮助了3D检测。第一行例子展示了2D物体的localization和semantic带来的帮助,其中杂乱环境下的bookshelf没有被VoteNet检测出,而ImVoteNet就具有足够的置信度确保被检测出。另外image semantics能够辅助网络避免False Positive的chair(coffee table和candles对VoteNet带来了干扰);第二行例子展示了images如何补偿了depth sensor的缺陷。由于黑色沙发的颜色和材质,几乎没有采集到点,VoteNet没有检测出sofa,而ImVoteNet则成功将其检测出来;第三行例子展示了远处被检测出的物体,而这些物体在真值中都没有被标出,说明了结合image cues能够突破3D检测性能的限制。
4.3 算法结构分析实验(Ablation Study)
这里验证了4个模块,分别是geometric cues,semantic cues,texture cues以及gradient blending training对整个算法模型的影响,具体结果如表2所示。对于geometric cues,可以看到不使用任何geometric cues会带来2.2的精度损失,不使用射线的3个角度会带来1.2的精度损失,说明射线方向还是非常重要的。对于semantic cues,可以看出尽管使用10维的one-hot class vector,相比于其他高维特征但仍然取得了最好的结果。对于texture cues,也使用最简单的原始RGB值,比其他复杂的逐像素的features相比仍然效果最好。

表2:针对2d cues的ablation study。
对于gradient blending training,不同tower的权重影响整体梯度融合训练的效果。作者采用了四种不同的混合模式,如表3所示,分别得到了不同的精度。这里作者提到仅仅使用image tower,就能够比表1中很多之前的方法精度要高,展示了ImVoteNet框架的有效性。
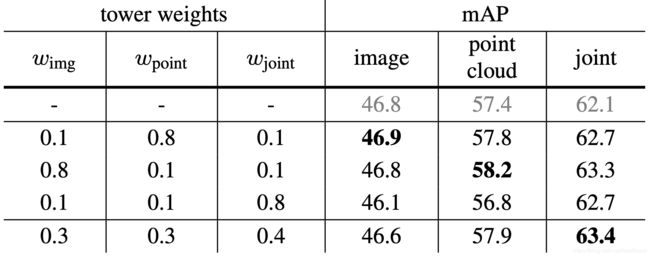
表3:针对gradient blending training的分析。
4.4 稀疏点云检测结果
由深度图得到的点云非常稠密,通常包含10k~100k的点,然而很多情况下只能得到稀疏的点云,例如使用vSLAM或者SFM重建得到的点云。这里分析了ImVoteNet在处理sparse点云时的性能。这里对由深度图得到的点云,使用两种方式进行下采样,一种均匀随机下采样,一种提取2D image ORB特征点对应的3D点。在表4中给出了不同点云输入情况的结果,可以看出随着点云数目的减少精度迅速下降,也可以看出增加image cues能够极大提升效果,这在点云数目少时更为明显。另外,由于ORB特征点对应的3D点在空间分布不均匀导致结果非常差,如图7所示。
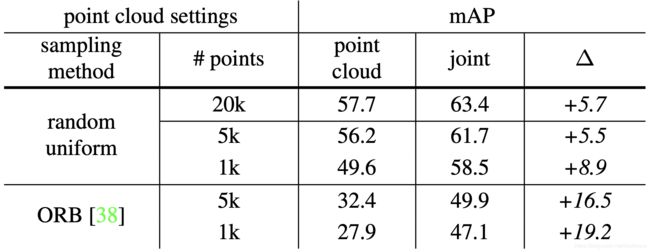
表4:针对sparse point cloud情况的分析。
图7: 不同数目点云在空间中的分布情况。
5. 总结
这篇文章探索了如何使用image信息辅助基于voting的3D检测框架。之前的VoteNet依靠voting机制有效增强了点云中的几何信息。这篇文章展示了ImVoteNet如何使用额外的图像,提供geometric,semantic和texture信息于3D voting的过程,详细介绍了如何将2D的geometric信息提升到3D。通过使用基于梯度混合的多模态的训练方法,ImVoteNet极大提升了处理稀疏或不友好分布点云的3D检测性能。
本文中所有图片均引自改论文。本解读只讲述核心观点,如需深入了解,可阅读原始论文。如有问题,请随时交流,如有错误,请随时指正。