开源数据库在平安的应用实践
2019年5月9日,平安科技数据库产品及存储产品部总经理在第十届数据库技术大会DTCC上分享了《开源数据库在平安的应用实践》,本文根据演讲内容整理,围绕以下几个方面进行分享:
1.平安为什么要使用开源数据库?
2.使用开源数据库,需要投入哪些成本?
3.如何选择合适的开源数据库?
4.引入和应用开源数据库的策略是什么?
5.平安的开源数据库架构如何?
6.三个开源数据库在平安的具体应用案例

汪洋 平安科技数据库产品及存储产品部总经理
很高兴在DTCC十年的节点上,又回到北京,站在这个台上跟大家分享,我一直对DTCC是有感情的,因为我本身是北京人,但是离开北京已经20多年了,每年借着DTCC可以回家看看。
我叫汪洋,来自平安科技,在平安科技负责两个团队,存储产品团队和数据库产品团队,这两个产品团队全都跟数据有关。平安科技是平安集团的全资子公司,它有三个职能,一个集团的高科技内核,二是创新孵化器,这两年也开始将技术和服务对外输出。
我在平安科技做了8年,今天我讲的是平安在开源数据库方面的应用实践,对于很多金融公司来讲,受到一行两会的监管,在采用开源数据库的时候,基本保持观望的态度;而任何一家组织架构的转型,包括引入一些新的技术,都是有风险的,尤其是对于金融公司,大家都知道,平安集团就是一家综合金融公司,它覆盖了金融产品的方方面面。
那么为什么平安在这种情况下开始引入架构的转型,开始引入一些开源数据库,并且在内部推广?希望我今天的分享能给金融同业或其他公司带来一些借鉴。
一、平安为什么要使用开源数据库?
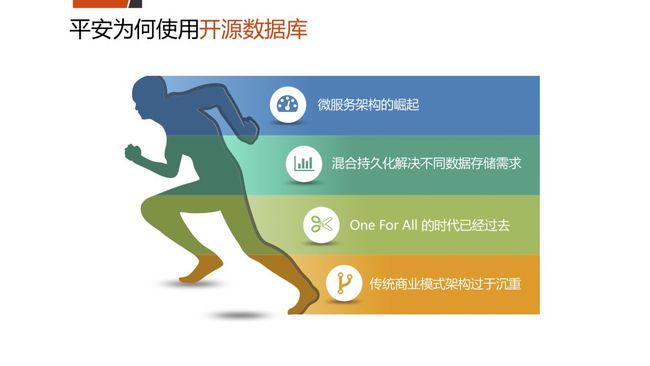
1.微服务架构的崛起
在2013-2014年的时候,很多像平安这样的传统公司都在探索怎么样进行互联网转型,那时Gartner提出双模式发展,双模式发展就是为了适应传统企业向互联网转型的需要,一方面企业对于传统的应用系统仍然需要三高,即高可用高可靠高性能;另一方面要快速响应,在自己的领域内能够向互联网转型,这就要求敏捷开发,敏捷交付。这个时候过去的单体架构带来很多问题:
开发周期很长,上线时间长,推向市场时间变很长
变更风险大,因为单体架构,牵一发而动全身
很难进行扩容,特别是根据不同的组件进行扩容
而微服务架构的崛起,能够把一个单体架构拆成各个模块,针对模块进行扩容,因为每个模块有不同的负载特性,模块之间是松偶合的,微服务架构的崛起就带来它底层的持久化存储的需要。
2.混合持久化解决不同数据存储需求
微服务架构带来了多态性的存储。为什么会有多态性,因为我们的数据不再向以前一样:以前的我们追求高一致性,都是企业化数据;但是在很多互联网场景下我们做秒杀时并不需要那么高的一致性,它的数据格式也是不一样的,因此也出现了不同的存储引擎,随着微服务的发展,可根据他自己的特性、数据格式、采取不同的数据库。
3.One for all时代已经过去
现在不是One for all,而是Best fit
每个业务场景都有特定的数据库。
所以我说技术没有对错,没有最好,只有适合业务场景的技术。
4.传统商业数据库架构过于沉重
以Oracle为例,大约二十年前我学习的时候只有几本书,现在的书可能一个房间都装不下,安装Oracle软件也是,都很大,但是装MySQL,都是轻量的,只有几十或几百兆,部署也相对简单,这有利于快速试错,快速把市场需求转换为产品原型,快速推向市场。总之技术都是服务于业务。
还有我们是被开发人员倒逼,他们为了满足业务需求使用开源数据库,如果运维方面跟不上的话,运维会成为背锅侠,因为最终生产出问题是落在了运维身上。
二、使用开源数据库,需要投入哪些成本
从整体看,开源数据库并不是免费的,使用开源数据库是一个循序渐进过程,在使用开源数据库时不能牺牲系统稳定性,因此需要许多其他方面的成本投入。
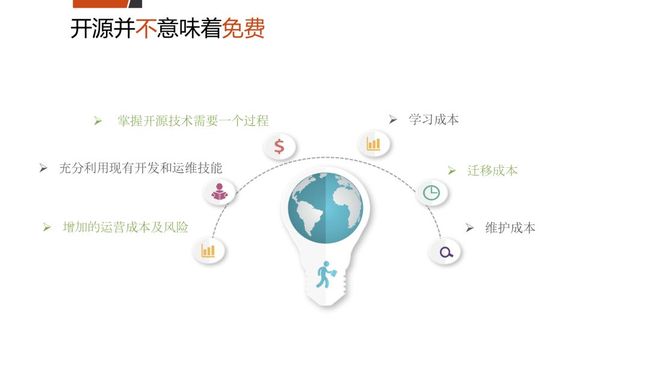
学习成本:学习成本是针对开发和运维人员的,因为数据库对开发人员从来不是一个黑盒子,当数据库体量变大时,肯定会遇到各种各样的问题,所以开发和运维都存在一个学习周期。
迁移成本:虽然世面上很多迁移工具可以节省开发人员的投入,实际上这些工具没有尽善尽美,特别是在代码迁移上,虽然转换过来功能可行,但你会发现代码几乎是不可读的。
所以宁愿把业务逻辑重构,重新看一遍,再用新数据库语法重新写一遍,在迁移过程中,数据迁移占小,代码迁移才是大头。
维护成本:需要对数据库有很深的了解,才能在发生问题时快速定位,解决问题,事件响应机制、监控指标等都是维护成本。
时间成本:掌握开源技术也需要一个过程,充分应用现有开发和运维技术,比如我当初为什么会选PostgreSQL,PostgreSQL对现有一直在Oracle系统上的运维和开发团队来说,学习曲线是相对来说比较短,能够快速进行迁移。
增加的运营成本及风险:增加运维成本的风险,人员招聘、人员培训都有一个周期,数据库团队、产品、运维机制都需要在生产环境中不断的锤炼,才能变得不断完善、成熟。
三、如何选择合适的开源数据库?


业务场景的需求:每个数据库都是服务一个业务场景的需求,平安集团的好处是业务场景非常丰富:产险、寿险、养老险、壹钱包、健康互联网、智慧城市等,我们可以在业务场景中充分的验证这些开源数据库,哪些数据库适用于哪些业务场景,在场景中不断的打磨运维和开发团队。
有适合的替代方案:你在使用的数据库有没有合适的替代方案,比如我想从Oracle迁移出来,选择什么数据库,在四五年前,我选择的是PostgreSQL,现在证明当时的决定是对的,你可以看到AWS有很多RDS服务,所有迁移的方案,都是从Oracle迁移到PostgreSQL,也就是说PostgreSQL跟Oracle是相近的,他们间的迁移成本和学习成本都相对是较少的。
我们现有开发人员的技能:过往有过Oracle经验的开发比较容易迁移到PostgreSQL。
现有数据库的负载模式:根据每个系统负载类型可以选择不同的开源数据库。
开源社区活跃度:如果你选择一个开源数据库活跃度不高,你心里没底,你不知道它能不能发展下去,我们选择开源数据库希望尽可能的能用很长时间。
市场份额及行业知名度:数据库处于出生期、成长期、成熟期、老年期的哪一个区域,需要了解它的生命周期,了解它在国外国内的一些应用情况来增加使用信心。
开发语言:数据库本身的开发语言,能否匹配到现在团队成员所具备的技能。运维需要快速定位问题发生在哪一步,研发人员需要对开源数据库的代码进行改造,让他更适配应用场景,所以开发语言也是考虑因素。
数据库类型:我们在布局整个数据库组合时,要考虑在哪些数据库类型上进行布局,有很多数据库类型,但不是每个数据库类型都需要,所以需要选择。
数据库技术的发展趋势:希望所选择的数据库是未来技术发展的趋势。
不要使用太多的开源产品:如果数据库种类太多也会增加运维成本,因为每一个数据库都需要学习成本,在满足业务场景的需求下选择尽可能少的数据库产品,尽量做到标准化。
四、引入和应用开源数据库的策略是什么?


现有的系统是已经运行生产的系统,它对运行的可用性有较高的要求,不能因为引入开源数据库就对系统性能造成影响。应该按照重要性进行分类,平安根据数据库按重要性分为3类。
不同业务线开放程度不一样,平安一些传统的大公司,如寿险、产险、银行,他们相对来说比较谨慎;但是一些互联网公司,如陆金所、壹钱包、健康互联网,他们比较积极进取,愿意进行新技术的尝试,当然要确保不会对业务造成大的影响,完善后再推广到传统公司。
数据库产品团队有一百多人,不太现实让每个人都去掌握多种数据库,特别在刚开始的时候,我会让一两个人去负责某个数据库产品,以点带面去对其他开发人员进行培训。其他的比如制定数据库架构、运营和开发的指南手册;对运营、开发以及DBA提供培训。
另外,持续进行架构优化;积累开发和运营经验;学习源代码;建立自己的研发团队;加入开源社区,这些都是在引入时需要有一定的计划。

以下是平安各业务使用的不同类型开源数据库的选型策略。


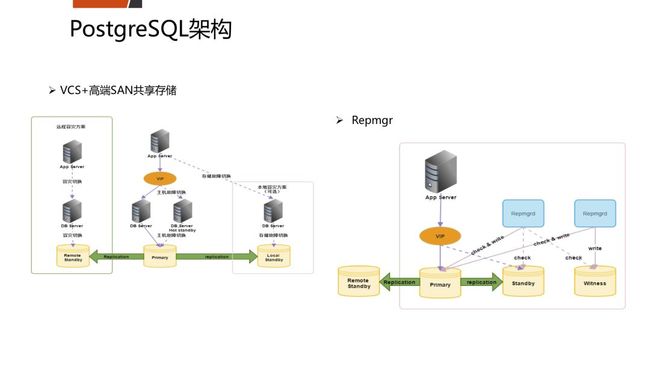
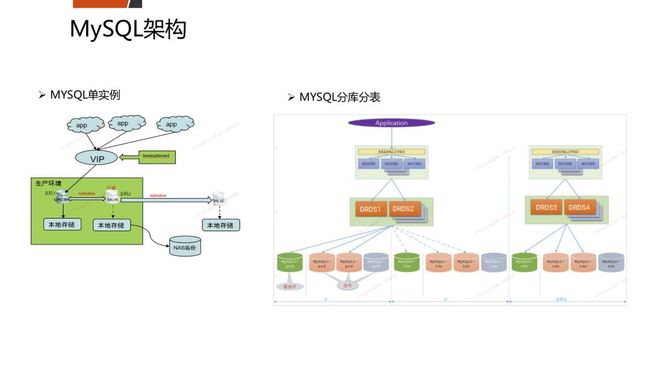
五、平安的开源数据库架构如何?
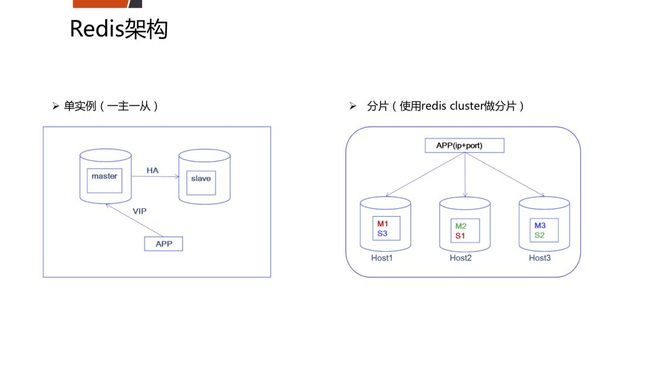
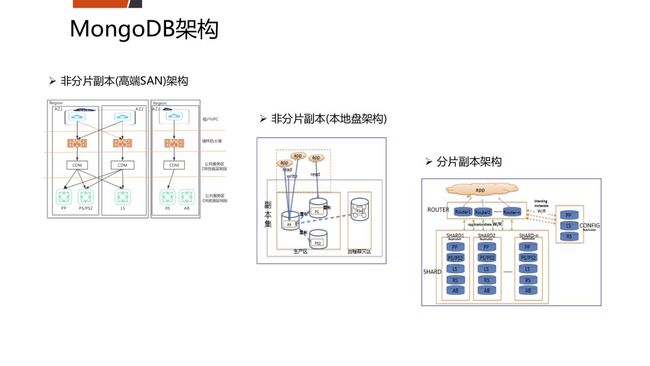
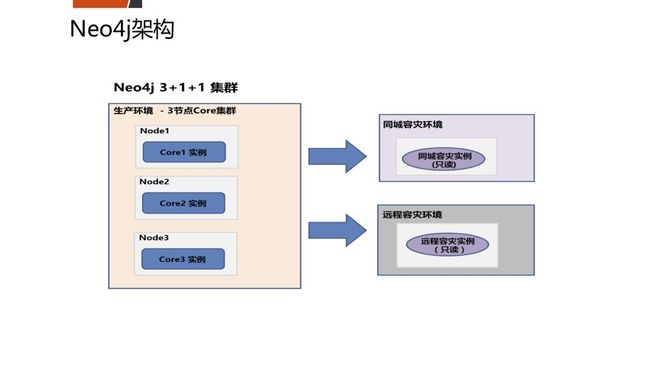
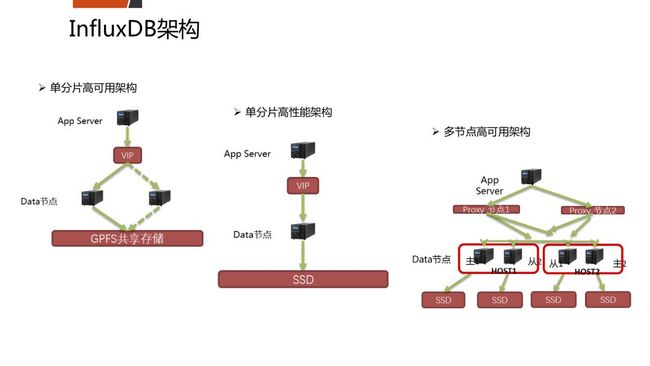
六、三个开源数据库在平安的应用案例
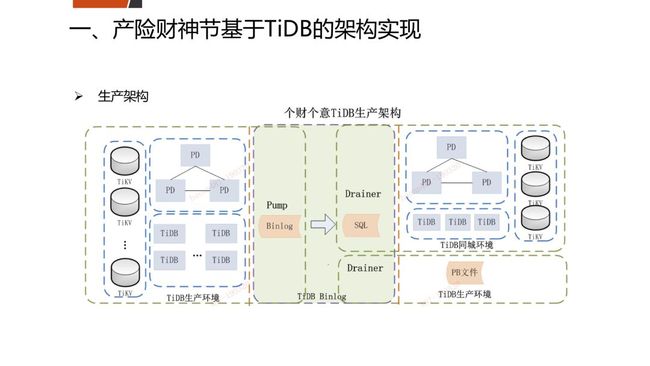
第一个案例是我们今年在1月8号 产险“财神节”活动使用TiDB,25个节点的集群,有主从两套架构,包括TiDB、TiKV,总共25个节点,主从之间通过BinLog做到异步同步。
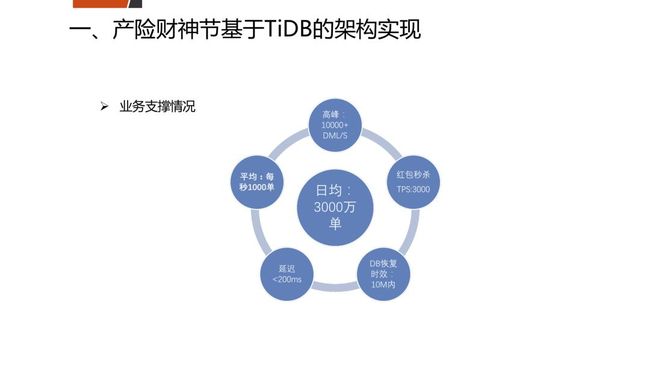
业务高峰期数据,如每秒10000+DML、平均每秒1000单、红包秒杀TPS3000等。单从TPS来看,数据不是很大,但对于每个业务场景,要看相对值而不是绝对值,因为每一个Transaction的复杂度是不同的,对于产险,一个Transaction中有多达上百个SQL语句。
其实这个产品当时搭建了25个节点,我们的标准规格是NVMe,一时很难找到这么多的NVMe机器,因此采用SSD,也是很好的满足了产险秒杀活动的需要。
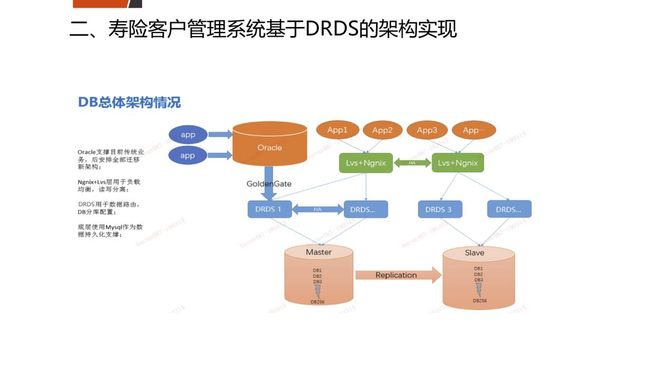
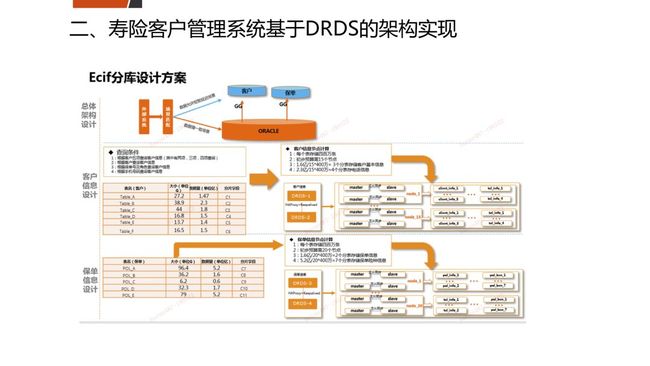
第二个案例是寿险客户管理系统基于我们自研的DRDS。因为客户信息数据非常重要,所以我们是把写的负载仍然放在Oracle,然后是实现读写分离,读是用另外一个数据库集群、另外一个资源来实现,并且是在这个读上面来使用单独的架构,这是35个节点的集群,15个节点是记录客户信息的变化,20个节点是记录保单信息的。通过客户服务和保单服务,来实现两个DRDS的集群,当客户查询的时候,就是去相应的集群上访问查询。

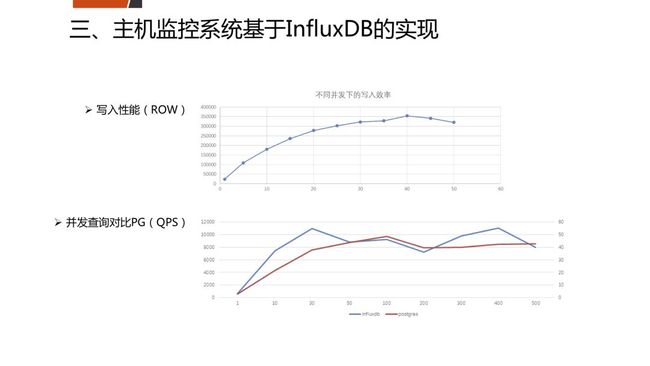
InfluxDB是时序数据库中的佼佼者,时序数据库发展前景也是非常不错的,特别是在IoT时代,不停有大量的数据产生,对这些数据存储需要能支持高并发的写入,它具有非常强的优势;另外根据时间序列对数据进行分析聚合,在实际场景中也得到广泛的应用。
我们自己的数据库产品团队,是将它用在了监控系统上,去采集很多数据,我们现在有更多的监控对象,如cpu、memory、nginx、I/O、各种数据库等。InfluxDB的写入性能每秒可达到35w,这在关系型数据库里面,单机的、在有index的情况下,很难想象能达到每秒35w。还有并发查询与PostgreSQL相比的数据,时序数据库还是有比较明显的优势。
七、发展路径
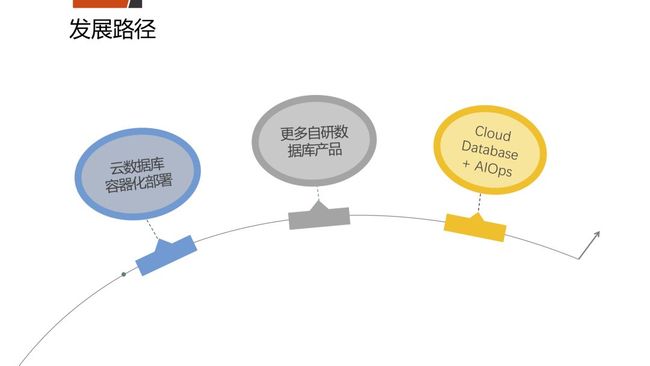
引入众多开源数据库之后,我们在平安云上,通过Cloud Database的方式,对外提供服务。一个方向是我们现在正在做云数据库容器化的部署,以期达到更高密度的部署、更强的自愈能力、更容易扩展的价值。
另一个方向是更多自研数据库产品,基于这些数据库产品开发出自主可控的数据库,比如基于分布式KV数据库开发出图数据库产品。
最后一个就是刚刚提到的Cloud Database,云提供商是有天然的做AIOps的优势,因为做AI最重要的就是数据,数据量要大,而且数据样本要非常丰富,小的公司要做AIOps是不太可能的,所以我们可以基于平安云来收集这些数据库的运营信息,结合人工智能和机器学习,进行更精细的异常检测、故障预测,能够进行更精细化的资源管理,来不断完善我们的产品。
以上,就是我今天关于平安在开源数据库方面的应用实践的一些分享,谢谢大家!
出处:https://mp.weixin.qq.com/s/5JbVkf4IyqPrsCipo_042A
2019数据技术嘉年华 金融峰会 · 深圳站 即将开始,欢迎大家报名参加~



公司简介 | 招聘 | DTCC | 数据技术嘉年华 | 免费课程 | 入驻华为严选商城

zCloud | SQM | Bethune Pro2 | zData一体机 | MyData一体机 | ZDBM 备份一体机

Oracle技术架构 | 免费课程 | 数据库排行榜 | DBASK问题集萃 | 技术通讯

升级迁移 | 性能优化 | 智能整合 | 安全保障 | 架构设计 | SQL审核 | 分布式架构 | 高可用容灾 | 运维代维
云和恩墨大讲堂 | 一个分享交流的地方
长按,识别二维码,加入万人交流社群

请备注:云和恩墨大讲堂