信用评分之五--并行逻辑回归
转腾讯冯杨的一篇文章
http://blog.sina.com.cn/s/blog_6cb8e53d0101oetv.html
可以参考相关的论文如下:
[1] 王兵. 一种基于逻辑回归模型的搜索广告点击率预估方法的研究[D]. 浙江大学 2013
[2] 祁全昌. 基于内容广告平台的点击率预估系统的设计与实现[D]. 南京大学 2012
[3] 霍艳. 网络广告投放算法的研究[D]. 东北大学 2013
[4] 刘唐. 基于多类别特征的在线广告点击率预测研究[D]. 北京邮电大学 2013
[5] 刘小兵 大规模逻辑回归并行化 搜搜
转载:
逻辑回归(Logistic Regression,简称LR)是机器学习中十分常用的一种分类算法,在互联网领域得到了广泛的应用,无论是在广告系统中进行CTR预估,推荐系统中的预估转换率,反垃圾系统中的识别垃圾内容……都可以看到它的身影。LR以其简单的原理和应用的普适性受到了广大应用者的青睐。实际情况中,由于受到单机处理能力和效率的限制,在利用大规模样本数据进行训练的时候往往需要将求解LR问题的过程进行并行化,本文从并行化的角度讨论LR的实现。
1. LR的基本原理和求解方法
LR模型中,通过特征权重向量对特征向量的不同维度上的取值进行加权,并用逻辑函数将其压缩到0~1的范围,作为该样本为正样本的概率。逻辑函数为
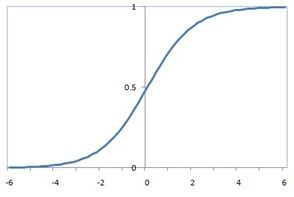
图1 逻辑函数曲线
给定M个训练样本并行逻辑回归![]() ,其中Xj={xji|i=1,2,…N} 为N维的实数向量(特征向量,本文中所有向量不作说明都为列向量);yj取值为+1或-1,为分类标签,+1表示样本为正样本,-1表示样本为负样本。在LR模型中,第j个样本为正样本的概率是:
,其中Xj={xji|i=1,2,…N} 为N维的实数向量(特征向量,本文中所有向量不作说明都为列向量);yj取值为+1或-1,为分类标签,+1表示样本为正样本,-1表示样本为负样本。在LR模型中,第j个样本为正样本的概率是:
![]() 其中W是N维的特征权重向量,也就是LR问题中要求解的模型参数。
其中W是N维的特征权重向量,也就是LR问题中要求解的模型参数。
求解LR问题,就是寻找一个合适的特征权重向量W,使得对于训练集里面的正样本,![]() 并行逻辑回归值尽量大;对于训练集里面的负样本,这个值尽量小(或
并行逻辑回归值尽量大;对于训练集里面的负样本,这个值尽量小(或![]() 并行逻辑回归尽量大)。用联合概率来表示:
并行逻辑回归尽量大)。用联合概率来表示:

对上式求log并取负号,则等价于:
 公式(1)
公式(1)
公式(1)就是LR求解的目标函数。
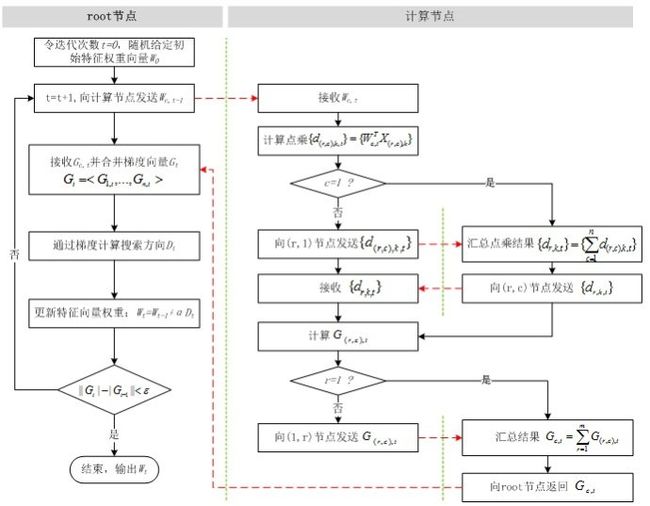
寻找合适的W令目标函数f(W)最小,是一个无约束最优化问题,解决这个问题的通用做法是随机给定一个初始的W0,通过迭代,在每次迭代中计算目标函数的下降方向并更新W,直到目标函数稳定在最小的点。如图2所示。
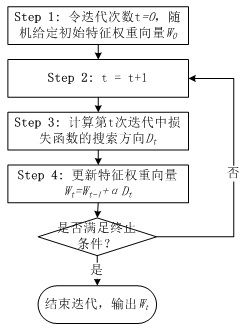
图2 求解最优化目标函数的基本步骤
不同的优化算法的区别就在于目标函数下降方向Dt的计算。下降方向是通过对目标函数在当前的W下求一阶倒数(梯度,Gradient)和求二阶导数(海森矩阵,Hessian Matrix)得到。常见的算法有梯度下降法、牛顿法、拟牛顿法。
(1) 梯度下降法(Gradient Descent)
梯度下降法直接采用目标函数在当前W的梯度的反方向作为下降方向:
![]()
其中![]() 并行逻辑回归为目标函数的梯度,计算方法为:
并行逻辑回归为目标函数的梯度,计算方法为:

(2) 牛顿法(Newton Methods)
牛顿法是在当前W下,利用二次泰勒展开近似目标函数,然后利用该近似函数来求解目标函数的下降方向:
![]()
其中Bt为目标函数f(W)在Wt处的海森矩阵。这个搜索方向也称作牛顿方向。
(3) 拟牛顿法(Quasi-Newton Methods):
拟牛顿法只要求每一步迭代中计算目标函数的梯度,通过拟合的方式找到一个近似的海森矩阵用于计算牛顿方向。最早的拟牛顿法是DFP(1959年由W. C. Davidon提出,并由R. Fletcher和M. J. D. Powell进行完善)。DFP继承了牛顿法收敛速度快的优点,并且避免了牛顿法中每次迭代都需要重新计算海森矩阵的问题,只需要利用梯度更新上一次迭代得到的海森矩阵,但缺点是每次迭代中都需要计算海森矩阵的逆,才能得到牛顿方向。
BFGS是由C. G. Broyden, R. Fletcher, D. Goldfarb和D. F. Shanno各自独立发明的一种方法,只需要增量计算海森矩阵的逆Ht=Bt-1,避免了每次迭代中的矩阵求逆运算。BFGS中牛顿方向表示为
![]()
L-BFGS(Limited-memory BFGS)则是解决了BFGS中每次迭代后都需要保存N*N阶海森逆矩阵的问题,只需要保存每次迭代的两组向量和一组标量即可:

在L-BFGS的第t次迭代中,只需要两步循环既可以增量计算牛顿方向:

2. 并行LR的实现
由逻辑回归问题的求解方法中可以看出,无论是梯度下降法、牛顿法、拟牛顿法,计算梯度都是其最基本的步骤,并且L-BFGS通过两步循环计算牛顿方向的方法,避免了计算海森矩阵。因此逻辑回归的并行化最主要的就是对目标函数梯度计算的并行化。从公式(2)中可以看出,目标函数的梯度向量计算中只需要进行向量间的点乘和相加,可以很容易将每个迭代过程拆分成相互独立的计算步骤,由不同的节点进行独立计算,然后归并计算结果。
将M个样本的标签构成一个M维的标签向量,M个N维特征向量构成一个M*N的样本矩阵,如图3所示。其中特征矩阵每一行为一个特征向量(M行),列为特征维度(N列)。
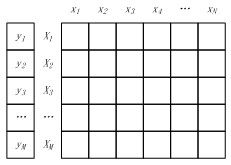
图3 样本标签向量 & 样本矩阵
如果将样本矩阵按行划分,将样本特征向量分布到不同的计算节点,由各计算节点完成自己所负责样本的点乘与求和计算,然后将计算结果进行归并,则实现了“按行并行的LR”。按行并行的LR解决了样本数量的问题,但是实际情况中会存在针对高维特征向量进行逻辑回归的场景(如广告系统中的特征维度高达上亿),仅仅按行进行并行处理,无法满足这类场景的需求,因此还需要按列将高维的特征向量拆分成若干小的向量进行求解。
(1) 数据分割
假设所有计算节点排列成m行n列(m*n个计算节点),按行将样本进行划分,每个计算节点分配M/m个样本特征向量和分类标签;按列对特征向量进行切分,每个节点上的特征向量分配N/n维特征。如图4所示,同一样本的特征对应节点的行号相同,不同样本相同维度的特征对应节点的列号相同。
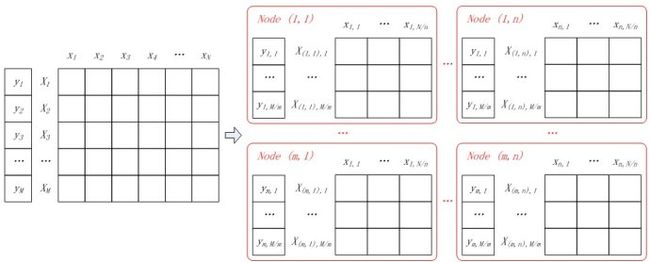
图4 并行LR中的数据分割
一个样本的特征向量被拆分到同一行不同列的节点中,即:
![]()
其中Xr,k表示第r行的第k个向量,X(r,c),k表示Xr,k在第c列节点上的分量。同样的,用Wc表示特征向量W在第c列节点上的分量,即:
![]()
(2) 并行计算
观察目标函数的梯度计算公式(公式(2)),其依赖于两个计算结果:特征权重向量Wt和特征向量Xj的点乘,标量![]() 和特征向量Xj的相乘。可以将目标函数的梯度计算分成两个并行化计算步骤和两个结果归并步骤
和特征向量Xj的相乘。可以将目标函数的梯度计算分成两个并行化计算步骤和两个结果归并步骤
① 各节点并行计算点乘,计算![]() 并行逻辑回归,其中k=1,2,…,M/m,d(r,c),k,t表示第t次迭代中节点(r,c)上的第k个特征向量与特征权重分量的点乘,Wc,t为第t次迭代中特征权重向量在第c列节点上的分量。
并行逻辑回归,其中k=1,2,…,M/m,d(r,c),k,t表示第t次迭代中节点(r,c)上的第k个特征向量与特征权重分量的点乘,Wc,t为第t次迭代中特征权重向量在第c列节点上的分量。
② 对行号相同的节点归并点乘结果

计算得到的点乘结果需要返回到该行所有计算节点中,如图5所示。
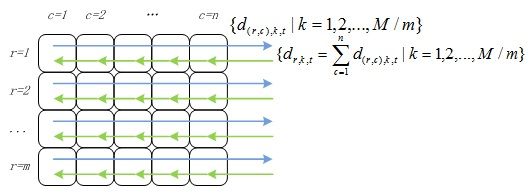
图5 点乘结果归并
③ 各节点独立算标量与特征向量相乘
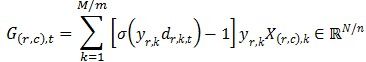
G(r,c),t可以理解为由第r行节点上部分样本计算出的目标函数梯度向量在第c列节点上的分量。
④ 对列号相同的节点进行归并:
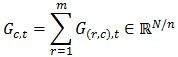
Gc,t就是目标函数的梯度向量Gt在第c列节点上的分量,对其进行归并得到目标函数的梯度向量:
![]()
这个过程如图6所示。

综合上述步骤,并行LR的计算流程如图7所示。比较图2和图7,并行LR实际上就是在求解损失函数最优解的过程中,针对寻找损失函数下降方向中的梯度方向计算作了并行化处理,而在利用梯度确定下降方向的过程中也可以采用并行化(如L-BFGS中的两步循环法求牛顿方向)
3. 实验及结果
利用MPI,分别基于梯度下降法(MPI_GD)和L-BFGS(MPI_L-BFGS)实现并行LR,以Liblinear为基准,比较三种方法的训练效率。Liblinear是一个开源库,其中包括了基于TRON的LR(Liblinear的开发者Chih-Jen Lin于1999年创建了TRON方法,并且在论文中展示单机情况下TRON比L-BFGS效率更高)。由于Liblinear并没有实现并行化(事实上是可以加以改造的),实验在单机上进行,MPI_GD和MPI_L-BFGS均采用10个进程。
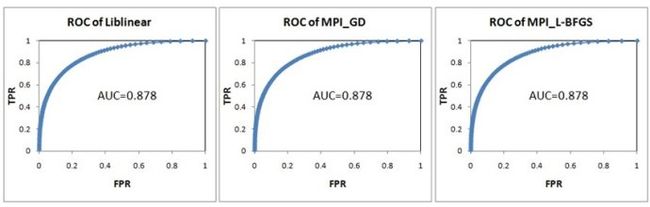
实验数据是200万条训练样本,特征向量的维度为2000,正负样本的比例为3:7。采用十折交叉法比较MPI_GD、MPI_L-BFGS以及Liblinear的分类效果。结果如图8所示,三者几乎没有区别。
将训练数据由10万逐渐增加到200万,比较三种方法的训练耗时,结果如图9,MPI_GD由于收敛速度慢,尽管采用10个进程,单机上的表现依旧弱于Liblinear,基本上都需要30轮左右的迭代才能达到收敛;MPI_L-BFGS则只需要3~5轮迭代即可收敛(与Liblinear接近),虽然每轮迭代需要额外的开销计算牛顿方向,其收敛速度也要远远快于MPI_GD,另外由于采用多进程并行处理,耗时也远低于Liblinear。
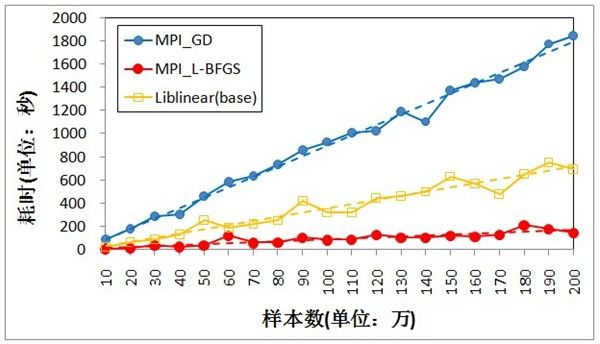
图9 训练耗时对比