【python自动化第五篇:python入门进阶】
今天内容:
- 模块的定义
- 导入方法
- import的本质
- 导入优化
- 模块分类
- 模块介绍
一、模块定义:
比如说:文件名为test.py的文件,他的模块名就是test
例如:在同一个文件夹下创建main.py(导入模块的程序),test.py(模块文件)
#main.py文件内容如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import test
print (test.name) #导入test模块下的变量
print(test.say_hello())
#test.py文件内容如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
name = "wanghui"
def say_hello():
print('hello %s'%name)二、导入方法:
import module1,module2,module3..... (多个导入用英文逗号隔开)
from module_name import * (导入所有的module_name下的所有代码拿到当前的程序下先执行一遍,建议不要这样使用)
from module_name import logger as logger_module_name (导入module_name模块下的logger函数,并重命名为logger_module_name)
三、import的本质
import导入:相当于是将模块的内容解释之后赋值给需要导入该模块的程序,调用的时候需要以module.func(模块对应的方法)来调用这个模块的方法
from module import func这样的导入:相当于是打开module这个文件并找到func方法执行一遍,直接用func名来调用即可。
包的定义:本质就是一个目录(必须带有一个__init.py__的文件),
包的导入:导入包的目的就是为了解释包下的init.py文件
路径搜索的意义:就是为了能在import的时候找到正确的模块路径(也就是跨目录的模块搜索功能)。
路径搜索用到的模块:sys,os
| 1 2 3 4 5 6 7 8 9 |
|
这样的话就可以实现跨目录的调用了,一定要记得加载到环境变量中。
完整的导入技巧如下:
| 1 2 3 4 5 6 |
|
四、导入优化
像是有些模块在重复使用的情况下,import的导入方法要弱于from module import func;毕竟重复使用的时候也只是使用模块对应的方法。要单纯使用import的时候多个函数的模块调用会导致运行效率不高。故引入from modue import func 来直接定义好要调用的func,从而提高多个函数的模块调用的效率!
五、模块的分类:
- 标准库(内置模块)
- 第三方库(开源模块)
- 自定义模块
六、标准库
1.时间模块
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
t = time.time() # 单位是秒, 是从1970.1.1-00:00:00到现在经历的秒
print(t) #1544488596.48
q = time.localtime() # 时间元组格式的时间
print(q) # time.struct_time(tm_year=2016, tm_mon=8, tm_mday=22, tm_hour=2, tm_min=57, tm_sec=59, tm_wday=0, tm_yday=235, tm_isdst=0)
w = time.timezone # 格里尼治时间和本地时间的差(按秒计算)
print(w / 3600) # 打印时区差 -8
e = time.altzone # 夏令时(DST)和UTC时间差 time.daylight 是否使用夏令时
print(e / 3600) # 打印小时差 -9
# time.sleep(10) #休息10秒
r = time.gmtime() # 需要传入秒数,然后就转换成时间元组(time.timezone),
print(r) # 不加时间戳参数则表示打印的是格林尼治时间元组
#time.struct_time(tm_year=2018, tm_mon=12, tm_mday=11, tm_hour=0, tm_min=36, tm_sec=36, tm_wday=1, tm_yday=345, tm_isdst=0)
y = time.localtime() # 转换成当地时间元组形式
print(y) # 加参数则能够随着本地的时间格式转换
#time.struct_time(tm_year=2018, tm_mon=12, tm_mday=11, tm_hour=8, tm_min=36, tm_sec=36, tm_wday=1, tm_yday=345, tm_isdst=0)
d = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 将元组结构时间转换成格式化时间
print(d) #2018-12-11 08:36:36
f = time.strptime('2016-08-23 00:30:32', "%Y-%m-%d %H:%M:%S") # 格式化时间转换成元组结构时间
print(f)
#time.struct_time(tm_year=2016, tm_mon=8, tm_mday=23, tm_hour=0, tm_min=30, tm_sec=32, tm_wday=1, tm_yday=236, tm_isdst=-1)
g = time.asctime() # 将时间转换成Tue Aug 23 00:35:52 2016格式
print(g)
k = time.ctime() # 将时间戳格式转换成Tue Aug 23 00:35:52 2016格式
print(k) 操作图如下:

datetime模块:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import datetime
print(datetime.date) #
print(datetime.time) #
print(datetime.datetime.now()) # 2018-12-11 08:51:58.775000
print(datetime.datetime.now() + datetime.timedelta(3)) # 获取到的三天后的时间
#2018-12-14 08:51:58.775000
print(datetime.datetime.now() + datetime.timedelta(-3)) # 获取三天前的时间
#2018-12-08 08:51:58.775000
print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 获取三小时以后的时间
#2018-12-11 11:51:58.775000
print(datetime.datetime.now() + datetime.timedelta(hours=-3)) # 获取三小时钱的时间
print(datetime.datetime.now() + datetime.timedelta(minutes=3)) # 获取三分钟以后的时间
print(datetime.datetime.now() + datetime.timedelta(minutes=-3)) # 获取三分钟之前的时间
# 时间替换
c_time = datetime.datetime.now() # 获取当前时间
print(c_time.replace(minute=4, hour=2)) # replace当前时间
#2018-12-11 02:04:58.775000 2.random
random基础操作:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
random实战生成六位验证码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 方法一:
import random
check_code = [] # 定义空列表,用于传递验证码用
for i in range(6): # 定义验证码位数
r = random.randint(0, 5) # 定义生成验证码的次数
if i == 2 or r == 4: # 第二位或者第四次生成数字。将其加入空列表
num = random.randint(0, 9)
check_code.append(str(num))
else: # 其他情况
word = random.randint(65, 90) # 定义字母并见此追加到列表中
word_str = chr(word)
check_code.append(str(word_str))
final_code = "".join(check_code)
print(final_code)
# 方法二:
checkcode = ''
for m in range(6): # 定义验证码位数
current = random.randint(0, 9) # 让数字活动起来
if m == 2 or current == 4: # 位数和次数 (完全随机的话current == m)
tmp = random.randint(0, 9) # 如果次数随机等于m,则将其任意值赋给tmp
else:
tmp = chr(random.randint(65, 90)) # 其余的为字母
checkcode += str(tmp) # 拼接字符串
print(checkcode) # 打印验证码3.os模块:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
3.sys模块:
| 1 2 3 4 5 6 7 8 9 10 |
|
4.shutil:高级的 文件、文件夹、压缩包 处理模块
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
5.shelve模块
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 简单的将key,value数据持久化的一个模块,可以持久化任何pickle支持的python数据格式
# 由于不能多次dump或者load多次,效率低下
import shelve, datetime
d = shelve.open("test.txt")
info = {'name': 'wanghui', 'age': 25}
job = ['IT', 'WORKER', 'DESIGNER']
d["job"] = job
d["info"] = info
d['date'] = datetime.datetime.now()
d.close()
d = shelve.open("test.txt")
print(d.get('job')) # 获取job列表
print(d.get('info')) # 获取字典
print(d.get('date')) # 获取时间
d.close()6.xml模块
需要处理的test.xml文件:
2
2008
141100
5
2011
59900
69
2011
13600
调用xml模块的方法处理xml文件:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import xml.etree.ElementTree as ET
tree = ET.parse('test.xml') # 定义要处理的文件
first = tree.getroot() # 获取根节点参数
print(first.tag) #
# 遍历xml文档
for second in first: # 读取第二级节点
print(second.tag, second.attrib)
for third in second: # 读取第三级节点
print(third.tag, third.attrib)
for forth in third:
print(forth.tag, forth.attrib)
# 只遍历其中的year节点
for node in first.iter("year"):
print(node.tag, node.text)
# 修改xml文件
for node in first.iter('year'):
new = int(node.text) + 1 # year + 1
node.text = str(new) # 转换成str
node.set("updated", 'yes') # 添加新的属性
tree.write("test.xml")
# 删除节点
for country in first.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
first.remove(country)
tree.write('out.xml')
# 创建xml文件
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist") # 声明namelist
personinfo = ET.SubElement(new_xml, 'personinfo', attrib={'enrolled': 'yes'})
name = ET.SubElement(personinfo, "age", atrrib={'checked', 'no'})
name.text = 'wanghui'
age = ET.SubElement(personinfo, "age", atrrib={'checked', 'no'})
sex = ET.SubElement(name, 'sex')
age.text = '25'
personinfo2 = ET.SubElement(new_xml, 'personinfo', attrib={'enrolled': 'no'})
name = ET.SubElement(personinfo2, "age", atrrib={'checked', 'no'})
name.text = "alex"
age = ET.SubElement(personinfo2, "age")
age.text = '12'
ex = ET.ElementTree(new_xml) # 生成文档对象
ex.write('test1.xml', encoding='utf-8', xml_declaration=True)
ET.dump(new_xml) # 打印生成的格式7.configparser模块:用于处理配置文件
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# configparser:处理配置文件
import configparser
conf = configparser.ConfigParser() # 生成configparser对象
conf["DEFAULT"] = {'ServerAliveInterval': '45', # 生成第一个实例
'Compression': 'yes',
"CompressionLevel": 9
}
conf['bitbucher.org'] = {} # 第二个实例
conf['bitbucher.org']['User'] = 'hg'
conf["topsecret.server.com"] = {} # 第三个实例
topsecret = conf["topsecret.server.com"]
topsecret['Host Port'] = "52333"
topsecret['ForwardXll'] = 'no'
with open('example.ini', 'w') as configfile:
conf.write(configfile) # 写入配置文件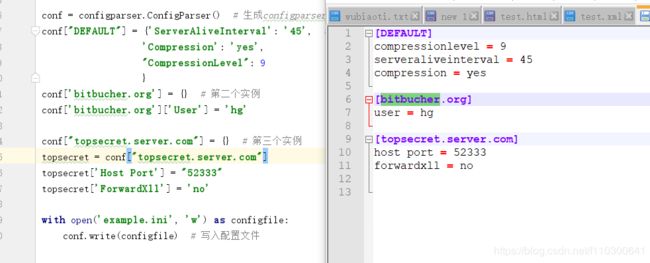
其他操作:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
python字符串前面加u,r,b的含义
u/U:表示unicode字符串
不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码。
一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。
建议所有编码方式采用utf8
r/R:非转义的原始字符串
与普通字符相比,其他相对特殊的字符,其中可能包含转义字符,即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。而如果是以r开头,那么说明后面的字符,都是普通的字符了,即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
以r开头的字符,常用于正则表达式,对应着re模块。
b:bytes
python3.x里默认的str是(py2.x里的)unicode, bytes是(py2.x)的str, b”“前缀代表的就是bytes
python2.x里, b前缀没什么具体意义, 只是为了兼容python3.x的这种写法
8.hashlib模块:提供加密算法
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import hashlib
m = hashlib.md5() # 创建md5加密对象
m.update(b'hello') # 对象中插入数值
print(m.hexdigest()) # 以十六进制打印md5值
#5d41402abc4b2a76b9719d911017c592
m.update(b"it's me!!")
print(m.hexdigest())
#ad9aa8b4b73be9c9e704d57014a014a0
m.update(b'as long as you love me!')
print(m.hexdigest())
#43beb5c5cce0dc3f07f371f9fbd732f8
# 拼接
m2 = hashlib.md5()
m2.update(b"helloit's me!!") # 更新之后的和拼接的md5一样
print(m2.hexdigest())
#ad9aa8b4b73be9c9e704d57014a014a0
s1 = hashlib.sha512()
s1.update(b"helloit's me!!") # 复杂算法
print(s1.hexdigest())
# 带中文的加密
f1 = hashlib.md5()
f1.update(b"你妹呀!!")
print(f1.hexdigest())
# 更吊的版本
import hmac
k1 = hmac.new(b'wanghui', b'message') # 仅支持ascii码,不支持中文
print(k1.hexdigest())
print(k1.digest())
# 带中文的加密
k2 = hmac.new("你大爷的!!", "呵呵哒!")
print(k2.hexdigest())9.re模块:匹配字符串(模糊匹配)