1.进程上下文与中断上下文
进程上下文指一个进程在执行的时候,cpu中的所有寄存器值(通用寄存器、eflags、esp、eip等)、堆栈段代码段数据段、内核栈以及task_struct里的一堆信息(进程状态、mm_struct、files_struct等)。Linux使用schedule()进行进程上下文切换。
中断上下文由软硬件触发中断,查找IDT表内相应中断门,SAVE_ALL宏在栈中保存中断处理程序可能会使用的所有CPU寄存器(eflags、cs、eip、ss、esp已由硬件自动保存),并将栈顶地址保存到eax寄存器中来形成。然后中断处理程序调用do_IRQ(pt_regs*)函数,查找irq_desc数组来执行具体的中断逻辑。

进程上下文和中断上下文区别:
1.中断或异常处理程序执行的代码不是一个进程,是一个内核控制路径。作为内核控制路径它很“轻”,只包含了内核中断程序必须的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等,无需恢复进程的虚拟内存等资源,建立和终止开销小。
2.中断上下文与特定进程无关,当发生某个中断时不管这个中断是哪个进程的都借用当前运行进程的内核栈来执行。
软中断与系统调用(指system_call):都会暂停当前CPU运行的用户态上下文,保存工作现场,然后陷入到内核态工作。主要区别是系统调用切换到同进程的内核态上下文,而软中断在系统有大量软中断等待处理情况下有可能会切换到ksoftirqd内核线程程进行处理。一般情况下软中断耗时为3us,系统调用耗时200ns起步。
2.fork分析:
fork、vfork、clone都是用户态C函数库提供的封装接口,用于进行系统调用,分别调用内核态的sys_fork、sys_vfork、sys_clone函数,它们最终都调用do_fork()来实现进程的创建;do_fork主要为子进程分配新pid,然后调用copy_process()复制进程描述符。整个函数调用关系图如下:
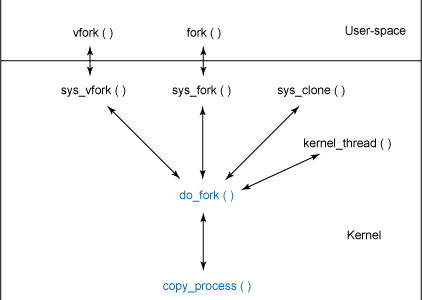
它们三者的主要区别在于:
fork()子进程全面拷贝父进程拥有的包括页表项在内的资源,clone_flags为SIGCHLD;使用写时复制(COW)技术来降低复制开销,即子进程先共享父进程的物理页,这些区域的页表条目都被标记为只读并且区域结构被标记为私有写时复制,只要有一个进程试图写一个页面则会触发一个保护故障,故障处理程序在物理内存中创建这个页面的一个新副本,更新页表条目指向这个新的副本,恢复页面可写权限,然后重新执行写操作。
vfork()创建的进程能共享父进程的内存地址空间,子进程对地址空间的任何修改都对父进程可见,反之亦然。因此为了防止父进程重写子进程需要的数据,阻塞了父进程的执行,一直到子进程退出或执行一个新程序为止。
通常vfork和execve一起使用,来避免fork不必要的复制。
clone()函数功能更为强大,可以让你选择性地继承父进程的资源,可以让你像vfork一样与父进程共享地址空间,也可以不和父进程共享,创造出来的新进程也可以不和原进程是父子关系,可以是兄弟关系。
它的函数签名如下:
int clone (int (*__fn) (void *__arg), void *__child_stack,int __flags, void *__arg, ...)
fn为新进程执行的函数,当该函数返回时子进程终止,函数返回一个整数表示子进程退出代码。
flags包含各类信息,低字节指定子进程结束时发送到父进程的信号代码,通常选择SIGCHLD信号,剩余三个字节给一clone标志组用于编码,如下表所示:
| 标志 | 含义 |
|---|---|
| CLONE_PARENT | 创建的子进程的父进程为调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子” |
| CLONE_FS | 子进程与父进程共享相同的文件系统,包括root、当前目录、umask |
| CLONE_FILES | 子进程与父进程共享相同的文件描述符(file descriptor)表 |
| CLONE_NEWNS | 在新的namespace启动子进程,namespace描述了进程的文件hierarchy |
| CLONE_SIGHAND | 子进程与父进程共享相同的信号处理(signal handler)表 |
| CLONE_PTRACE | 若父进程被trace,子进程也被trace |
| CLONE_VFORK | 父进程被挂起,直至子进程释放virtual memory资源(exit或execve) |
| CLONE_VM | 子进程与父进程共享内存描述符和所有的页表 |
| CLONE_THREAD | 把子进程插入到父进程的同一线程组中,并迫使子进程共享父进程的信号描述符 |
系统调用fork、vfork和clone在内核中对应的服务例程分别为sys_fork(),sys_vfork()和sys_clone(),执行sys系统调用例程前的过程见深入理解Linux系统调用。
int sys_fork(struct pt_regs *regs) { return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL); } int sys_vfork(struct pt_regs *regs) { return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->sp, regs, 0, NULL, NULL); } sys_clone(unsigned long clone_flags, unsigned long newsp, void __user *parent_tid, void __user *child_tid, struct pt_regs *regs) { if (!newsp) newsp = regs->sp; return do_fork(clone_flags, newsp, regs, 0, parent_tid, child_tid); }
do_fork的第一个参数clone_flags与clone()函数的flags相同,第二个stack_start参数与clone()函数的child_stack相同。可以看到三个系统调用只是使用了不同的参数调用do_fork()。
其中sys_clone没有clone的C函数中的fn和args参数,实际上封装函数用fn指针覆盖子进程压栈的clone返回后跳转的地址,args指针正好存放在子进程堆栈中的fn下面。当clone() C函数结束时,CPU从栈中取出返回地址跳转到fn(args)函数。
sys_fork使用的clone_flag为SIGCHLD,即子进程结束时发送给父进程SIGCHLD信号;sys_vfork使用的clone_flag为CLONE_VFORK | CLONE_VM | SIGCHLD。用户栈使用的都是父进程的栈。
接下来看看do_fork()的代码:
struct kernel_clone_args { u64 flags; int __user *pidfd; int __user *child_tid; int __user *parent_tid; int exit_signal; unsigned long stack; unsigned long stack_size; unsigned long tls; };
1 long _do_fork(struct kernel_clone_args *args) 2 { 3 u64 clone_flags = args->flags; 4 struct completion vfork; 5 struct pid *pid; 6 struct task_struct *p; 7 int trace = 0; 8 long nr; 9 10 /* 11 * Determine whether and which event to report to ptracer. When 12 * called from kernel_thread or CLONE_UNTRACED is explicitly 13 * requested, no event is reported; otherwise, report if the event 14 * for the type of forking is enabled. 15 */ 16 if (!(clone_flags & CLONE_UNTRACED)) { 17 if (clone_flags & CLONE_VFORK) 18 trace = PTRACE_EVENT_VFORK; 19 else if (args->exit_signal != SIGCHLD) 20 trace = PTRACE_EVENT_CLONE; 21 else 22 trace = PTRACE_EVENT_FORK; 23 24 if (likely(!ptrace_event_enabled(current, trace))) 25 trace = 0; 26 } 27 // 拷贝父进程task_struct以及其中的一些资源,返回创建的task_struct的指针 28 p = copy_process(NULL, trace, NUMA_NO_NODE, args); 29 add_latent_entropy(); 30 31 if (IS_ERR(p)) 32 return PTR_ERR(p); 33 34 /* 35 * Do this prior waking up the new thread - the thread pointer 36 * might get invalid after that point, if the thread exits quickly. 37 */ 38 trace_sched_process_fork(current, p); 39 // 取出task结构体内的pid 40 pid = get_task_pid(p, PIDTYPE_PID); 41 nr = pid_vnr(pid); 42 43 if (clone_flags & CLONE_PARENT_SETTID) 44 put_user(nr, args->parent_tid); 45 // 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行 46 if (clone_flags & CLONE_VFORK) { 47 p->vfork_done = &vfork; 48 init_completion(&vfork); 49 get_task_struct(p); 50 } 51 // 将子进程添加到调度器的队列,使得子进程有机会获得CPU 52 wake_up_new_task(p); 53 54 /* forking complete and child started to run, tell ptracer */ 55 if (unlikely(trace)) 56 ptrace_event_pid(trace, pid); 57 // 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间,保证子进程优先于父进程运行 58 if (clone_flags & CLONE_VFORK) { 59 if (!wait_for_vfork_done(p, &vfork)) 60 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); 61 } 62 63 put_pid(pid); 64 return nr; 65 }
可以看到do_fork()创建子进程描述符以及子进程执行所需要的所有其他数据结构,依靠调用copy_process()来完成,它的主要代码如下:
1 /* 2 创建进程描述符以及子进程所需要的其他所有数据结构 3 为子进程准备运行环境 4 */ 5 static struct task_struct *copy_process(unsigned long clone_flags, 6 unsigned long stack_start, 7 unsigned long stack_size, 8 int __user *child_tidptr, 9 struct pid *pid, 10 int trace) 11 { 12 int retval; 13 struct task_struct *p; 14 15 // 分配一个新的task_struct,此时的p与当前进程的task,仅仅是stack地址不同 16 p = dup_task_struct(current); 17 18 // 检查该用户的进程数是否超过限制 19 if (atomic_read(&p->real_cred->user->processes) >= 20 task_rlimit(p, RLIMIT_NPROC)) { 21 // 检查该用户是否具有相关权限,不一定是root 22 if (p->real_cred->user != INIT_USER && 23 !capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN)) 24 goto bad_fork_free; 25 } 26 27 retval = -EAGAIN; 28 // 检查进程数量是否超过 max_threads,后者取决于内存的大小 29 if (nr_threads >= max_threads) 30 goto bad_fork_cleanup_count; 31 32 // 初始化自旋锁 33 34 // 初始化挂起信号 35 36 // 初始化定时器 37 38 // 完成对新进程调度程序数据结构的初始化,并把新进程的状态设置为TASK_RUNNING 39 retval = sched_fork(clone_flags, p); 40 41 // copy父进程task_struct中的各类结构体, 包括mm、files、fs、sig等,有深拷贝和浅拷贝(只拷贝父进程task_struct中的某些结构指针并增加引用计数) 42 retval = copy_semundo(clone_flags, p); 43 if (retval) 44 goto bad_fork_cleanup_security; 45 retval = copy_files(clone_flags, p); 46 if (retval) 47 goto bad_fork_cleanup_semundo; 48 retval = copy_fs(clone_flags, p); 49 if (retval) 50 goto bad_fork_cleanup_files; 51 retval = copy_sighand(clone_flags, p); 52 if (retval) 53 goto bad_fork_cleanup_fs; 54 retval = copy_signal(clone_flags, p); 55 if (retval) 56 goto bad_fork_cleanup_sighand; 57 retval = copy_mm(clone_flags, p); 58 if (retval) 59 goto bad_fork_cleanup_signal; 60 retval = copy_namespaces(clone_flags, p); 61 if (retval) 62 goto bad_fork_cleanup_mm; 63 retval = copy_io(clone_flags, p); 64 65 // 初始化子进程的内核栈 66 retval = copy_thread(clone_flags, stack_start, stack_size, p); 67 if (retval) 68 goto bad_fork_cleanup_io; 69 70 if (pid != &init_struct_pid) { 71 retval = -ENOMEM; 72 // 这里为子进程分配了新的pid号 73 pid = alloc_pid(p->nsproxy->pid_ns_for_children); 74 if (!pid) 75 goto bad_fork_cleanup_io; 76 } 77 78 /* ok, now we should be set up.. */ 79 // 设置子进程的pid 80 p->pid = pid_nr(pid); 81 // 如果是创建线程 82 if (clone_flags & CLONE_THREAD) { 83 p->exit_signal = -1; 84 // 线程组的leader设置为当前线程的leader 85 p->group_leader = current->group_leader; 86 // tgid是当前线程组的id,也就是main进程的pid 87 p->tgid = current->tgid; 88 } else { 89 if (clone_flags & CLONE_PARENT) 90 p->exit_signal = current->group_leader->exit_signal; 91 else 92 p->exit_signal = (clone_flags & CSIGNAL); 93 // 创建的是进程,自己是一个单独的线程组 94 p->group_leader = p; 95 // tgid和pid相同 96 p->tgid = p->pid; 97 } 98 99 if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) { 100 // 如果是创建线程,那么同一线程组内的所有线程、进程共享parent 101 p->real_parent = current->real_parent; 102 p->parent_exec_id = current->parent_exec_id; 103 } else { 104 // 如果是创建进程,当前进程就是子进程的parent 105 p->real_parent = current; 106 p->parent_exec_id = current->self_exec_id; 107 } 108 109 // 将pid加入PIDTYPE_PID这个散列表 110 attach_pid(p, PIDTYPE_PID); 111 // 递增 nr_threads的值 112 nr_threads++; 113 114 // 返回被创建的task结构体指针 115 return p; 116 }
其主要过程为:
检查参数clone_flags所传递标志的一致性,在某些情况下返回错误代码。
调用dup_task_struct()为子进程复制一份进程描述符,包括复制父进程的thread_info结构和内核栈,同时把新进程描述符的使用计数器(tsk->usage)设置为2,用来表示进程描述符正在被使用而且其相应的进程处于活动状态。
检查系统中存在的进程数量(nr_thread)是否超过max_threads值。
调用sched_fork()函数,用于进程调度相关内容的初始化,如根据父进程的clone_flags设置子进程的优先级和权重等,为保证公平调度父子进程之间会共享父进程的时间片,并设置子进程的状态为TASK_RUNNING,这样才会被调度器放入运行队列中。
根据clone_flags有选择地进行一系列task_struct中各种字段的copy操作,主要包括:
copy_files(),使用dup_fd复制父进程task_struct中的file_struct指针,并将file对象里的引用计数+1(f_count成员)或者生成新副本。

copy_fs(),复制父进程根目录,进程所在目录。同样需要将引用计数+1或者生成新副本。
copy_signal()和copy_sighand()复制信号和信号处理函数。
copy_mm()复制用户地址空间,如果是内核线程则没有用户空间。如果有CLONE_VM标志则共享父进程mm结构,并将父进程mm的usr引用计数+1;否则不与父进程共享,调用allocate_mm()分配出一个新mm(包括分配新的PGD)并初始化,然后调用dup_mmap(mm)拷贝父进程vm_area_struct页面映射表,页面写保护标记也在复制时被设置。

/* * This structure defines the functions that are used to load the binary formats that * linux accepts. */ struct linux_binfmt { struct list_head lh; struct module *module; int (*load_binary)(struct linux_binprm *); //通过读存放在可执行文件中的信息为当前进程建立一个新的执行环境 int (*load_shlib)(struct file *); //用于动态的把一个共享库捆绑到一个已经在运行的进程, 这是由uselib()系统调用激活的 int (*core_dump)(struct coredump_params *cprm); //在名为core的文件中, 存放当前进程的执行上下文. 这个文件通常是在进程接收到一个缺省操作为”dump”的信号时被创建的, 其格式取决于被执行程序的可执行类型 unsigned long min_coredump; /* minimal dump size */ };
|
格式 |
linux_binfmt定义 |
load_binary |
load_shlib |
core_dump |
|---|---|---|---|---|
|
a.out |
aout_format |
load_aout_binary |
load_aout_library |
aout_core_dump |
|
flat style executables |
flat_format |
load_flat_binary |
load_flat_shared_library |
flat_core_dump |
|
script脚本 |
script_format |
load_script |
无 |
无 |
|
misc_format |
misc_format |
load_misc_binary |
无 |
无 |
|
em86 |
em86_format |
load_format |
无 |
无 |
|
elf_fdpic |
elf_fdpic_format |
load_elf_fdpic_binary |
无 |
elf_fdpic_core_dump |
|
elf |
elf_format |
load_elf_binary |
load_elf_binary |
elf_core_dump |
/* * This structure is used to hold the arguments that are used when loading binaries. */ struct linux_binprm { char buf[BINPRM_BUF_SIZE]; // 保存可执行文件的头128字节 #ifdef CONFIG_MMU struct vm_area_struct *vma; unsigned long vma_pages; #else # define MAX_ARG_PAGES 32 struct page *page[MAX_ARG_PAGES]; #endif struct mm_struct *mm; unsigned long p; /* current top of mem , 当前内存页最高地址*/ unsigned int cred_prepared:1,/* true if creds already prepared (multiple * preps happen for interpreters) */ cap_effective:1;/* true if has elevated effective capabilities, * false if not; except for init which inherits * its parent's caps anyway */ #ifdef __alpha__ unsigned int taso:1; #endif unsigned int recursion_depth; /* only for search_binary_handler() */ struct file * file; /* 要执行的文件 */ struct cred *cred; /* new credentials */ int unsafe; /* how unsafe this exec is (mask of LSM_UNSAFE_*) */ unsigned int per_clear; /* bits to clear in current->personality */ int argc, envc; /* 命令行参数和环境变量数目 */ const char * filename; /* Name of binary as seen by procps, 要执行的文件的名称 */ const char * interp; /* Name of the binary really executed. Most of the time same as filename, but could be different for binfmt_{misc,script} 要执行的文件的真实名称,通常和filename相同 */ unsigned interp_flags; unsigned interp_data; unsigned long loader, exec; };
1 static int __do_execve_file(int fd, struct filename *filename, 2 struct user_arg_ptr argv, 3 struct user_arg_ptr envp, 4 int flags, struct file *file) 5 { 6 char *pathbuf = NULL; 7 struct linux_binprm *bprm; //存储可执行文件信息 8 struct files_struct *displaced; 9 int retval; 10 11 if (IS_ERR(filename)) 12 return PTR_ERR(filename); 13 14 /* 15 * We move the actual failure in case of RLIMIT_NPROC excess from 16 * set*uid() to execve() because too many poorly written programs 17 * don't check setuid() return code. Here we additionally recheck 18 * whether NPROC limit is still exceeded. 19 */ 20 if ((current->flags & PF_NPROC_EXCEEDED) && 21 atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) { 22 retval = -EAGAIN; 23 goto out_ret; 24 } 25 26 /* We're below the limit (still or again), so we don't want to make 27 * further execve() calls fail. */ 28 current->flags &= ~PF_NPROC_EXCEEDED; 29 30 retval = unshare_files(&displaced); //为进程复制一份文件表 31 if (retval) 32 goto out_ret; 33 34 retval = -ENOMEM; 35 bprm = kzalloc(sizeof(*bprm), GFP_KERNEL); //调用kzmalloc在堆上分配一个linux_binprm结构体 36 if (!bprm) 37 goto out_files; 38 39 retval = prepare_bprm_creds(bprm); 40 if (retval) 41 goto out_free; 42 43 check_unsafe_exec(bprm); 44 current->in_execve = 1; 45 46 if (!file) 47 file = do_open_execat(fd, filename, flags); //调用open_exec()查找并打开二进制文件; 48 retval = PTR_ERR(file); 49 if (IS_ERR(file)) 50 goto out_unmark; 51 52 sched_exec(); //确定最小负载cpu以执行新程序,并把当前进程转移过去 53 54 bprm->file = file; 55 if (!filename) { 56 bprm->filename = "none"; 57 } else if (fd == AT_FDCWD || filename->name[0] == '/') { 58 bprm->filename = filename->name; 59 } else { 60 if (filename->name[0] == '\0') 61 pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d", fd); 62 else 63 pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d/%s", 64 fd, filename->name); 65 if (!pathbuf) { 66 retval = -ENOMEM; 67 goto out_unmark; 68 } 69 /* 70 * Record that a name derived from an O_CLOEXEC fd will be 71 * inaccessible after exec. Relies on having exclusive access to 72 * current->files (due to unshare_files above). 73 */ 74 if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt))) 75 bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE; 76 bprm->filename = pathbuf; 77 } 78 bprm->interp = bprm->filename; 79 80 retval = bprm_mm_init(bprm); 81 if (retval) 82 goto out_unmark; 83 84 retval = prepare_arg_pages(bprm, argv, envp); 85 if (retval < 0) 86 goto out; 87 88 //填充linux_binprm数据结构,再次检查文件是否可执行(至少设置一个执行访问权限) 89 //用可执行文件的前128字节填充linux_binrpm结构的buf段,这些字节包含用于识别可执行文件格式的一些信息 90 retval = prepare_binprm(bprm); 91 if (retval < 0) 92 goto out; 93 94 //将文件路径名、命令行参数以及环境串拷贝到一个或多个新分配的页框中(最终它们会分配给用户态地址空间) 95 retval = copy_strings_kernel(1, &bprm->filename, bprm); 96 if (retval < 0) 97 goto out; 98 99 bprm->exec = bprm->p; 100 retval = copy_strings(bprm->envc, envp, bprm); 101 if (retval < 0) 102 goto out; 103 104 retval = copy_strings(bprm->argc, argv, bprm); 105 if (retval < 0) 106 goto out; 107 108 would_dump(bprm, bprm->file); 109 110 //至此,二进制文件已经被打开,struct linux_binprm结构体中也记录了重要信息,需要调用exec_binprm识别该可执行文件的格式并最终运行该文件 111 retval = exec_binprm(bprm); 112 if (retval < 0) 113 goto out; 114 115 /* execve succeeded */ 116 current->fs->in_exec = 0; 117 current->in_execve = 0; 118 rseq_execve(current); 119 acct_update_integrals(current); 120 task_numa_free(current, false); 121 free_bprm(bprm); 122 kfree(pathbuf); 123 if (filename) 124 putname(filename); 125 if (displaced) 126 put_files_struct(displaced); 127 return retval;
继续查看exec_binprm()源码,可以看到构造出linux_binprm对象后search_binary_handler()函数实现了核心功能。由于linux注册的每种可执行文件对应一种linux_binfmt结构体,内核用链表的方式将它们组织起来,并线性扫描链表,对每一种fmt调用其load_binary()方法,如果成功则停止遍历。
static int exec_binprm(struct linux_binprm *bprm) { pid_t old_pid, old_vpid; int ret; /* Need to fetch pid before load_binary changes it */ old_pid = current->pid; rcu_read_lock(); old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent)); rcu_read_unlock(); //调用search_binary_handler()对formats链表进行逐个扫描,并尽力应用每个元素的load_binary方法,把linux_binprm结构传递给这个函数 // list_for_each_entry(fmt, &formats, lh): // retval = fmt->load_binary(bprm); //只要load_binary方法成功应答了文件的可执行格式,对formats的扫描即终止 ret = search_binary_handler(bprm); if (ret >= 0) { audit_bprm(bprm); trace_sched_process_exec(current, old_pid, bprm); ptrace_event(PTRACE_EVENT_EXEC, old_vpid); proc_exec_connector(current); } return ret; }
我们假设执行的可执行文件为最常见的elf格式,由前面的bin_fmt表可以看到elf格式的load_binary方法名为load_elf_binary,我们来探究这个函数源码,了解新的程序上下文是如何替换进来的。由于load_elf_binary代码量很多,我们进行一些节选。
1.执行一些一致性检查
/* 1 填充并且检查ELF头部 */ /* Get the exec-header 1.1 填充ELF头信息 在load_elf_binary之前 内核已经使用映像文件的前128个字节对bprm->buf进行了填充, 这里使用这此信息填充映像的文件头 */ loc->elf_ex = *((struct elfhdr *)bprm->buf); retval = -ENOEXEC; /* 1.2 First of all, some simple consistency checks 比较文件头的前四个字节,查看是否是ELF文件类型定义的"\177ELF"*/ if (memcmp(loc->elf_ex.e_ident, ELFMAG, SELFMAG) != 0) goto out; /* 1.3 除前4个字符以外,还要看映像的类型是否ET_EXEC和ET_DYN之一;前者表示可执行映像,后者表示共享库 */ if (loc->elf_ex.e_type != ET_EXEC && loc->elf_ex.e_type != ET_DYN) goto out; /* 1.4 检查特定的目标机器标识 */ if (!elf_check_arch(&loc->elf_ex)) goto out; if (!bprm->file->f_op->mmap) goto out;
2. 读入kernel_read读入elf的program header table,该表将elf一些连续的节映射到运行时内存段
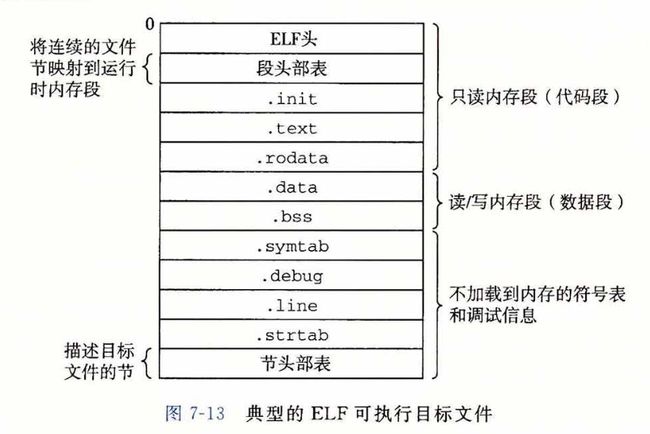

3.处理elf依赖的动态链接库。PT_INTERP在elf program header中用于指明为加载可执行文件而用的动态链接库名称,在linux下通常为/lib/ld.so.2
for (i = 0; i < loc->elf_ex.e_phnum; i++, elf_ppnt++) { char *elf_interpreter; loff_t pos; if (elf_ppnt->p_type != PT_INTERP) //找到PT_INTERP段,这个段表示可执行程序运行时,需要依赖的动态链接库解释器 continue; /* * This is the program interpreter used for shared libraries - * for now assume that this is an a.out format binary. */ retval = -ENOEXEC; if (elf_ppnt->p_filesz > PATH_MAX || elf_ppnt->p_filesz < 2) goto out_free_ph; retval = -ENOMEM; //为动态链接器分配空间并读取加载 elf_interpreter = kmalloc(elf_ppnt->p_filesz, GFP_KERNEL); if (!elf_interpreter) goto out_free_ph; pos = elf_ppnt->p_offset; //根据其位置p_offset和大小p_filesz,将整个解释器段读入缓冲区 retval = kernel_read(bprm->file, elf_interpreter, elf_ppnt->p_filesz, &pos); if (retval != elf_ppnt->p_filesz) { if (retval >= 0) retval = -EIO; goto out_free_interp; } /* make sure path is NULL terminated */ retval = -ENOEXEC; if (elf_interpreter[elf_ppnt->p_filesz - 1] != '\0') goto out_free_interp; interpreter = open_exec(elf_interpreter); kfree(elf_interpreter); retval = PTR_ERR(interpreter); if (IS_ERR(interpreter)) goto out_free_ph; /* * If the binary is not readable then enforce mm->dumpable = 0 * regardless of the interpreter's permissions. */ would_dump(bprm, interpreter); /* Get the exec headers */ pos = 0; //读入解释器前128字节,即解释器映像头部 retval = kernel_read(interpreter, &loc->interp_elf_ex, sizeof(loc->interp_elf_ex), &pos); if (retval != sizeof(loc->interp_elf_ex)) { if (retval >= 0) retval = -EIO; goto out_free_dentry; } break; out_free_interp: kfree(elf_interpreter); goto out_free_ph; }
检查解释器头的信息并读入解释器的程序头:
if (interpreter) { retval = -ELIBBAD; /* Not an ELF interpreter */ if (memcmp(loc->interp_elf_ex.e_ident, ELFMAG, SELFMAG) != 0) goto out_free_dentry; /* Verify the interpreter has a valid arch */ if (!elf_check_arch(&loc->interp_elf_ex) || elf_check_fdpic(&loc->interp_elf_ex)) goto out_free_dentry; /* Load the interpreter program headers */ interp_elf_phdata = load_elf_phdrs(&loc->interp_elf_ex, interpreter); if (!interp_elf_phdata) goto out_free_dentry; /* Pass PT_LOPROC..PT_HIPROC headers to arch code */ elf_ppnt = interp_elf_phdata; for (i = 0; i < loc->interp_elf_ex.e_phnum; i++, elf_ppnt++) switch (elf_ppnt->p_type) { case PT_LOPROC ... PT_HIPROC: retval = arch_elf_pt_proc(&loc->interp_elf_ex, elf_ppnt, interpreter, true, &arch_state); if (retval) goto out_free_dentry; break; } }
4.释放本进程先前所占用的几乎所有资源,通过flush_old_exec()函数来完成。
retval = flush_old_exec(bprm);
它包括如下操作:
分配一个新的信号处理程序表,把旧表引用计数减1
调用de_thread(),将进程从旧的线程组脱离
调用unshared_files()拷贝一份包含进程已打开文件表的file_struct结构。因此exec后进程的打开文件保持不变(close-on-exec标记的文件除外)。
调用exec_mmap()释放分配给进程的内存描述符、所有线性区以及所有页框,并清除进程页表。
将可执行文件路径名赋值给进程描述符的comm字段
调用flush_thread()清除浮点寄存器的值和TSS段保存的调试寄存器的值。
调用flush_signal_handlers()函数,用于将每个信号恢复为默认操作,从而更新信号处理程序表。
调用flush_old_files()函数关闭所有设置了close-on-exec标志的文件。
现在原来的进程上下文环境基本被清空,已经没有了回头路。
5.为进程的用户态堆栈分配一个新的线性描述符区,并将那个线性区插入到进程的地址空间。
/* Do this so that we can load the interpreter, if need be. We will change some of these later */ retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP), executable_stack);
6.搜索program header中的PT_LOAD段,通过elf_map()将elf文件相应段映射到进程虚拟内存空间:
elf_bss = 0; elf_brk = 0; start_code = ~0UL; end_code = 0; start_data = 0; end_data = 0; /* Now we do a little grungy work by mmapping the ELF image into the correct location in memory. */ for(i = 0, elf_ppnt = elf_phdata; i < loc->elf_ex.e_phnum; i++, elf_ppnt++) { int elf_prot, elf_flags; unsigned long k, vaddr; unsigned long total_size = 0; if (elf_ppnt->p_type != PT_LOAD) continue; if (unlikely (elf_brk > elf_bss)) { unsigned long nbyte; /* There was a PT_LOAD segment with p_memsz > p_filesz before this one. Map anonymous pages, if needed, and clear the area. */ retval = set_brk(elf_bss + load_bias, elf_brk + load_bias, bss_prot); if (retval) goto out_free_dentry; nbyte = ELF_PAGEOFFSET(elf_bss); if (nbyte) { nbyte = ELF_MIN_ALIGN - nbyte; if (nbyte > elf_brk - elf_bss) nbyte = elf_brk - elf_bss; if (clear_user((void __user *)elf_bss + load_bias, nbyte)) { } } } elf_prot = make_prot(elf_ppnt->p_flags); elf_flags = MAP_PRIVATE | MAP_DENYWRITE | MAP_EXECUTABLE; vaddr = elf_ppnt->p_vaddr; /* * If we are loading ET_EXEC or we have already performed * the ET_DYN load_addr calculations, proceed normally. */ if (loc->elf_ex.e_type == ET_EXEC || load_addr_set) { elf_flags |= MAP_FIXED; } else if (loc->elf_ex.e_type == ET_DYN) { if (interpreter) { load_bias = ELF_ET_DYN_BASE; if (current->flags & PF_RANDOMIZE) load_bias += arch_mmap_rnd(); elf_flags |= MAP_FIXED; } else load_bias = 0; load_bias = ELF_PAGESTART(load_bias - vaddr); total_size = total_mapping_size(elf_phdata, loc->elf_ex.e_phnum); if (!total_size) { retval = -EINVAL; goto out_free_dentry; } } error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt, elf_prot, elf_flags, total_size); if (BAD_ADDR(error)) { retval = IS_ERR((void *)error) ? PTR_ERR((void*)error) : -EINVAL; goto out_free_dentry; } if (!load_addr_set) { load_addr_set = 1; load_addr = (elf_ppnt->p_vaddr - elf_ppnt->p_offset); if (loc->elf_ex.e_type == ET_DYN) { load_bias += error - ELF_PAGESTART(load_bias + vaddr); load_addr += load_bias; reloc_func_desc = load_bias; } } k = elf_ppnt->p_vaddr; if (k < start_code) start_code = k; if (start_data < k) start_data = k; /* * Check to see if the section's size will overflow the * allowed task size. Note that p_filesz must always be * <= p_memsz so it is only necessary to check p_memsz. */ if (BAD_ADDR(k) || elf_ppnt->p_filesz > elf_ppnt->p_memsz || elf_ppnt->p_memsz > TASK_SIZE || TASK_SIZE - elf_ppnt->p_memsz < k) { /* set_brk can never work. Avoid overflows. */ retval = -EINVAL; goto out_free_dentry; } k = elf_ppnt->p_vaddr + elf_ppnt->p_filesz; if (k > elf_bss) elf_bss = k; if ((elf_ppnt->p_flags & PF_X) && end_code < k) end_code = k; if (end_data < k) end_data = k; k = elf_ppnt->p_vaddr + elf_ppnt->p_memsz; if (k > elf_brk) { bss_prot = elf_prot; elf_brk = k; } } loc->elf_ex.e_entry += load_bias; elf_bss += load_bias; elf_brk += load_bias; start_code += load_bias; end_code += load_bias; start_data += load_bias; end_data += load_bias;
7.调用set_brk()创建一个新的匿名线性区来映射程序的bss段,该段大小是在可执行程序链接时即可计算出来的。当进程首次写该段某一页中的变量时,会发生缺页故障分配一个页框。
retval = set_brk(elf_bss, elf_brk, bss_prot);
8.按需调用一个装入动态链接程序的函数,该操作也会为动态链接程序分配堆栈、text段、数据段的线性区描述符,动态链接程序的正文段和数据段在线性区的起始地址是由动态链接程序本身指定的。
if (interpreter) { unsigned long interp_map_addr = 0; elf_entry = load_elf_interp(&loc->interp_elf_ex, interpreter, &interp_map_addr, load_bias, interp_elf_phdata); if (!IS_ERR((void *)elf_entry)) { /* * load_elf_interp() returns relocation * adjustment */ interp_load_addr = elf_entry; elf_entry += loc->interp_elf_ex.e_entry; } if (BAD_ADDR(elf_entry)) { retval = IS_ERR((void *)elf_entry) ? (int)elf_entry : -EINVAL; goto out_free_dentry; } reloc_func_desc = interp_load_addr; allow_write_access(interpreter); fput(interpreter); } else { elf_entry = loc->elf_ex.e_entry; if (BAD_ADDR(elf_entry)) { retval = -EINVAL; goto out_free_dentry; } }
9.create_elf_tables填写目标文件参数环境变量等必要信息,包括argc、envc等,放到用户堆栈上,这样可执行程序和动态链接程序才能根据内核保存在用户堆栈上的信息为自己建立一个基本的执行上下文。
retval = create_elf_tables(bprm, &loc->elf_ex, load_addr, interp_load_addr); if (retval < 0) goto out; current->mm->end_code = end_code; current->mm->start_code = start_code; current->mm->start_data = start_data; current->mm->end_data = end_data; current->mm->start_stack = bprm->p; if ((current->flags & PF_RANDOMIZE) && (randomize_va_space > 1)) { /* * For architectures with ELF randomization, when executing * a loader directly (i.e. no interpreter listed in ELF * headers), move the brk area out of the mmap region * (since it grows up, and may collide early with the stack * growing down), and into the unused ELF_ET_DYN_BASE region. */ if (IS_ENABLED(CONFIG_ARCH_HAS_ELF_RANDOMIZE) && loc->elf_ex.e_type == ET_DYN && !interpreter) current->mm->brk = current->mm->start_brk = ELF_ET_DYN_BASE; current->mm->brk = current->mm->start_brk = arch_randomize_brk(current->mm); #ifdef compat_brk_randomized current->brk_randomized = 1; #endif } if (current->personality & MMAP_PAGE_ZERO) { /* Why this, you ask??? Well SVr4 maps page 0 as read-only, and some applications "depend" upon this behavior. Since we do not have the power to recompile these, we emulate the SVr4 behavior. Sigh. */ error = vm_mmap(NULL, 0, PAGE_SIZE, PROT_READ | PROT_EXEC, MAP_FIXED | MAP_PRIVATE, 0); } regs = current_pt_regs();
10.最后start_thread()宏修改保存在内核态堆栈但属于用户态寄存器的eip和esp的值,以使它们分别指向动态链接程序入口点和新的用户态堆栈栈顶。即有动态链接库存在时,我们的程序被内核加载完后跳转到用户空间时,控制权在解释器(linux的ld),解释器加载运行程序所需的动态链接库(包括识别哪些共享库必须被装入,共享库中的哪些函数被有效请求,然后执行mmap()将相应.so文件正文和数据段映射到进程虚拟地址空间)后控制权才会转移到用户程序主入口点。
finalize_exec(bprm); start_thread(regs, elf_entry, bprm->p); retval = 0;
由此,新程序上下文完全替换了旧程序上下文,我们的新程序得以执行。