Python爬虫教程:Xpath实战训练
Xpath介绍
1. 维基百科看 Xpath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作
为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询 语言。
2.我来扯扯Xpath
- Xpath使用路径表达式在xml和html中进行导航(据说访问速度、效率比bs4快)
- Xpath包含标准函数库
- Xpah是一个W3c的标准
3.Xpath基本使用语法
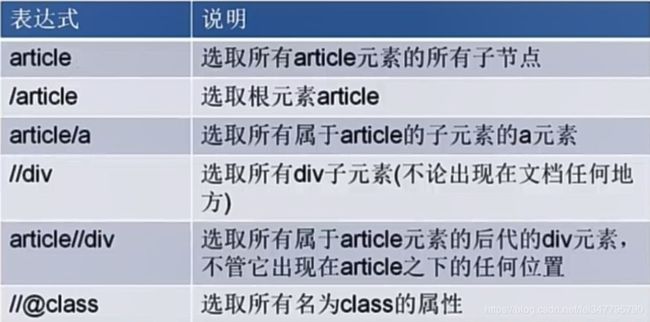


看代码,边学边敲边记
1.在cmd下启动我们的Scrapy项目子项—jobbole
(1)快速进入虚拟环境(设置方法见上一篇)
C:\Users\82055\Desktop>workon spiderenv
(2)进入到项目目录
(spiderenv) C:\Users\82055\Desktop>H:
(spiderenv) H:\env\spiderenv>cd H:\spider_project\spider_bole_blog\spider_bole_blog
(3)输入spider命令(格式:scrapy crawl 子项的name)
(spiderenv) H:\spider_project\spider_bole_blog\spider_bole_blog>scrapy crawl jobbole
(4)如果是win系统,可能会出现下面错误
from twisted.internet import _win32stdio
File "h:\env\spiderenv\lib\site-packages\twisted\internet\_win32stdio.py", line 9, in
import win32api
ModuleNotFoundError: No module named 'win32api'
(5)解决方法:安装 pypiwin32模块(采用豆瓣源安装)
虚拟环境中
pip install -i https://pypi.douban.com/simple pypiwin32
(6)再次执行spider命令
(spiderenv) H:\spider_project\spider_bole_blog\spider_bole_blog>scrapy crawl jobbole
2018-08-23 23:42:01 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: spider_bole_blog)
···
2018-08-23 23:42:04 [scrapy.core.engine] INFO: Closing spider (finished)
2018-08-23 23:42:04 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 440,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 21919,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 8, 23, 15, 42, 4, 695188),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 8, 23, 15, 42, 2, 770906)}
2018-08-23 23:42:04 [scrapy.core.engine] INFO: Spider closed (finished)
2.在Pycharm下启动我们的Scrapy项目子项—jobbole
(1)打开项目,在项目根目录下新建一个main.py,用于调试代码。
(2)在main.py中输入下面内容
import sys
import os
'''
更多Python学习资料以及源码教程资料,可以加群821460695 免费获取
'''
# 导入执行spider命令行函数
from scrapy.cmdline import execute
# 获取当前项目目录,添加到系统中
# 方法一:直接输入,不便于代码移植
#(比如小明和小红的项目路径可能不一样,那么小明的代码想在小红的电脑上运行,
# 路径就要手动改了,python怎么能这么麻烦呢,请看方法二)
# sys.path.append("H:\spider_project\spider_bole_blog\spider_bole_blog")
# 方法二:代码获取,灵活,代码移植也不影响
# print(os.path.dirname(os.path.abspath(__file__)))
# result : H:\spider_project\spider_bole_blog\spider_bole_blog
# 获取当前项目路径,添加到系统中
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# 执行spider命令
execute(['scrapy','crawl','jobbole'])
(3)修改setting.py文件设置,将ROBOTSTXT_OBEY值改为False,默认为True或者被注释掉了,文件中注释解释内容:Obey robots.txt rules,表示我们的spider的网址必须要遵循robots协议,不然会直接被过滤掉,所以这个变量的属性值必须设置为Fal0se哦!
# 大概是第21-22行,ROBOTSTXT_OBEY默认值为True
# 修改为False,如下:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
(4)直接运行测试文件main.py,运行结果和上面在cmd是一样的。
(5)在jobbole.py中的的parse函数中加一个断点,然后Debug模式运行测试文件main.py
断点设置:
debug结果分析: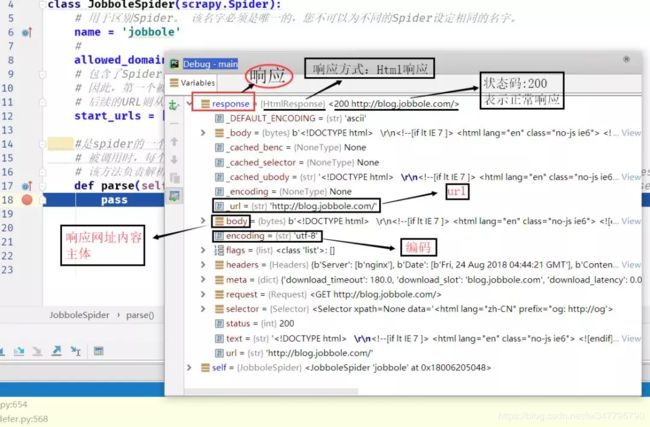
3.编写jobbole.py中的的parse函数,利用Xpath获取网页内容
(1)为了简单起见,我随便选取了一篇文章《Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的》。
(2)把start_urls的属性值改为http://blog.jobbole.com/114256/,使spider从当前文章开始爬起来。
start_urls = ['http://blog.jobbole.com/114256/']
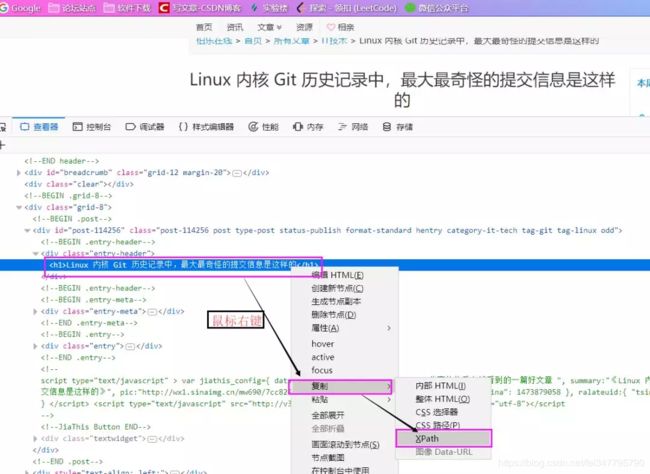
(3)网页中分析并获取文章标题Xpath路径

在FireFox浏览器下按F12进入开发者模式,选择查看器左边的选取图标功能,然后将鼠标移动到标题处,在查看器中会自动为我们找到源码中标题的位置,如上图分析,标题应该在html下的body中的第一个div中的第三个div中的第一个div中的第一个div中的h1标签中,那么Xpath路径即为:
/html/body/div[1]/div[3]/div[1]/div[1]/h1
是不是感觉到很复杂,哈哈哈,不用灰心,其实分析起来挺简单的,另外我们还有更简单的方法获取Xpath,当我们在查看器重找到我们要的内容后,直接右键,即可复制我们想要的内容的Xpath路径了。
(4)修改jobbole.py中的的parse函数,运行打印出文章标题
# scrapy 的 response里面包含了xpath方法,可以直接用调用,返回值为Selector类型
# Selector库中有个方法extract(),可以获取到data数据
def parse(self, response):
# firefox 浏览器返回的Xpath
re01_selector = response.xpath('/html/body/div[1]/div[3]/div[1]/div[1]/h1/text()')
# chrome 浏览器返回的Xpath
re02_selector = response.xpath('//*[@id="post-114256"]/div[1]/h1/text()')
re01_title = re01_selector.extract()
re02_title = re02_selector.extract()
print('xpath返回内容:'+str(re01_selector))
print('firefox返回文章标题为:' + re01_title)
print('chrome返回文章标题为:' + re02_title)
运行结果:
# 观察结果发现Xpath返回的Selector对象值包括 xpath路径和data数据
xpath返回内容:[]
firefox返回文章标题为:Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的
chrome返回文章标题为:Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的
从上面可以看出,FireFox和Chorme获取到的Xpath是不一样的,but实际返回的东西是一样的,只是用了不同的语法,我这里说明的意思是想告诉大家:Xpath的表达方式不止一种,可能某个内容的Xpath有两种或者更多,大家觉得怎么好理解就使用哪一个。
(5)我们继续获取其他数据(复习巩固一下Xpath的用法)
为了快速、有效率的调式数据,给大家推荐一种方法:
# cmd 虚拟环境中输入: scrapy shell 你要调试的网址
scrapy shell http://blog.jobbole.com/114256/
这样在cmd中就能保存我们的访问内容,可以直接在cmd下进行调试,不用在pycharm中每调试一个数据,就运行一次,访问一次页面,这样效率是非常低的。
获取文章发布时间
>>> data_r = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()')
>>> data_r.extract()
['\r\n\r\n 2018/08/08 · ', '\r\n \r\n \r\n\r\n \r\n · ', ', ', '\r\n \r\n']
>>> data_r.extract()[0].strip()
'2018/08/08 ·'
>>> data_str = data_r.extract()[0].strip()
>>> data_str.strip()
'2018/08/08 ·'
>>> data_str.replace('·','').strip()
'2018/08/08'
# data_selector = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()')
# data_str = data_selector.extract()[0].strip()
# data_time = data_str.replace('·','').strip()
获取文章点赞数、收藏数和评论数
# 点赞数
>>> praise_number = response.xpath('//h10[@id="114256votetotal"]/text()')
>>> praise_number
[]
>>> praise_number = int(praise_number.extract()[0])
>>> praise_number
1
# praise_number = int(response.xpath('//h10[@id="114256votetotal"]/text()').extract()[0])
# 收藏数
>>> collection_number = response.xpath('//span[@data-book-type="1"]/text()')
>>> collection_number
[]
>>> collection_number.extract()
[' 1 收藏']
>>> collection_word = collection_number.extract()[0]
>>> import re
>>> reg_str = '.*(\d+).*'
>>> re.findall(reg_str,collection_word)
['1']
>>> collection_number = int(re.findall(reg_str,collection_word)[0])
>>> collection_number
1
# collection_str = response.xpath('//span[@data-book-type="1"]/text()').extract()[0]
# reg_str = '.*(\d+).*'
# collection_number = int(re.findall(reg_str,collection_word)[0])
# 评论数
>>> comment_number = response.xpath('//span[@class="btn-bluet-bigger href-style hide-on-480"]/text()')
>>> comment_number
[]
>>> comment_number.extract()[0]
' 评论'
# 由于我选的这篇文章比较新,还没有评论,哈哈哈。。。
# 如果有的话,后面和上面获取收藏数是一样的方法(正则匹配)。
上是在cmd中的测试过程,可以看出来,我基本上都是用的都是//span[@data-book-type=“1”]这种格式的Xpath,而非像FireFox浏览器上复制的Xpath,原因有两点:
1.从外形来看,显然我使用的这种Xpath要更好,至少长度上少很多(特别对于比较深的数据,如果像
FireFox这种,可能长度大于100也不奇怪)
2.从性能上来看,我是用的这种形式匹配更加准确,如果莫个页面包含js加载的数据(也包含div,p,a 等标签),如果我们直接分析FireFox这种Xpath,可能会出错。
建议:
(1)决心想学好的,把本文二中的Xpath语法好好记一下,练习一下;
(2)爬取网页抓取数据尽量用谷歌浏览器。
3.现在jobbole.py中的代码及运行结果
代码:
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114256/']
def parse(self, response):
# 标题
# chrome 浏览器返回的Xpath
re01_seletor = response.xpath('//*[@id="post-114256"]/div[1]/h1/text()')
re01_title = re01_seletor.extract()
# 发布日期
data_selector = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()')
data_str = data_selector.extract()[0].strip()
data_time = data_str.replace('·','').strip()
# 点赞数
praise_number = int(response.xpath('//h10[@id="114256votetotal"]/text()').extract()[0])
# 收藏数
collection_str = response.xpath('//span[@data-book-type="1"]/text()').extract()[0]
reg_str = '.*(\d+).*'
collection_number = int(re.findall(reg_str,collection_str)[0])
print("文章标题:"+re01_title[0])
print("发布日期:"+data_time)
print("点赞数:"+str(praise_number))
print("收藏数:"+str(collection_number))
运行结果:
文章标题:Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的
发布日期:2018/08/08
点赞数:1
收藏数:2