R语言资源汇总
这是一个信息爆炸的时代,知识和技术变得越来越廉价,计算机技术门槛越来越低。无论是做数据分析还是应用开发,都不要将时间耗费在学习既有知识上面,学习能力不再是最重要的。迅速获得各方面资源、高效扩展知识面成为了重要的能力基础(尽量自顶向下地学习),不应当在这方面花费太多时间,更不要自己重头实现已有的方法(人生苦短,不要重复造轮子),而应将时间集中投入到两个层面上:一个是解决问题的架构设计,另一个是优化或创新技术方法。
必须指出:R是一门见多识广的语言,看得越多越显得厉害,需要思考的地方不会很多(当然要精通R也不是容易的事,比如能从头写一个ggplot体系就有点难度),而且基本上不会涉及到计算机的专业知识(比如内存管理技巧、网络协议、操作系统原理等),技术难点基本上都比较低,这一点与 C 和 Java 之类的很不一样。毕竟R的使用人群不是程序员,而是从事其他专业领域的数据分析人员和研究者。R中技能的更新是很重要的,R包日新月异,更新技能的学习成本不容小觑(知乎某用户提到R技能更新的问题说得确实很有道理:数据处理神器data.table)。
正如标题所述,本文仅仅是一个资源的汇总,本质上就是一些工具集合,会用这些工具并不代表就能善于数据分析。对于数据分析而言,更重要的是方法学的积累、领悟和进一步改进创新,这是需要多读文献多交流、了解别人如何分析、由浅而深地了解分析方法,需日积月累和勤于思考。
常规分析
本部分为R语言常规分析的常用工具,工欲善其事必先利其器,这些工具是熟练掌握的部分(尤其是数据整理系列工具)。
数据整理:tidyverse系列(数据整理的工具大集合)、data.table(新一代的数据表体系,高效且简洁,可参考:data.table文档、Introduction to data.table、Importing data.table、数据处理神器data.table)、vroom(基于索引的数据读取工具,比data.table更快)、rlist(处理非结构化list非常方便,可参考:github.io/rlist、rlist-tutorial、非结构化数据处理神器rlist包)、tidytext(文本挖掘工具,可参考:tidytext_introduction、R语言进行文本挖掘;还有readtext也可以文本数据挖掘)、sparklyr(使用dplyr操作Spark,可参考:sparklyr: R interface for Apache Spark、无缝对接Spark与R;此外还有个叫sparkR的包也不错)、rio(强大的数据导入导及格式转换工具,可参考:Import, Export, and Convert Data Files、github/rio)、vtreat(一个对预测模型进行变量预处理的工具)、stringi(字符串处理工具)、Matrix(著名的稀疏矩阵包,类似的还有MatrixModels。另外stats的model.matrix 常用来生成设计矩阵)。
特别介绍tidyverse系列,可参考tidyverse_packages。主要包有:
数据表操作类:tibble、dplyr、tidyr、purrr(一个扩展性的函数编程包,尤其是改善循环效率) 、broom(将统计模型结果整理成数据框形式)、readr和readxl(读取数据表的优化版,即read_*()系列,区别于read.*()系列)
特殊数据操作类:stringr(字符串处理工具)、forcats(非常棒的因子变量相关处理的工具)、lubridate(时间类数据的分析及可视化)、hms、blob。
其他:rvest(R的爬虫工具,可参考:tidyverse/rvest、rvest包总结)、magrittr(高效的管道操作,我们见到的%>%源于此包)、glue(paste函数的高级版,可便捷地操作连接数据和string)
常用的作图工具ggplot2也属于tidyverse系列。
另外,还有一些包也属于,如readxl、jsonlite等(jsonlite比rjson更为好用)。这些包都可以在tidyverse官网找到文档。
还有个叫purrrlyr的包,是purrr和dplyr的交叉(“名副其实”),可参考: purrrlyr:purrr和dplyr的交叉
早期还有个叫plyr的工具,现在已经被dplyr和purrr等工具替代。reshape2的许多功能也能在tidyr中找到。
其他链接:
Relationship to base and plyr functions
R语言函数式编程purrr的应用
purrr_reference
purrr-tutorial
broom官方介绍(tidyverse官网的子网站,里面有各种链接,包括菜单栏的Article和Reference等,同tidyverse其他包的介绍)
broom和dplyr的配合使用
关于tidyverse系列由R语言大神Hadley Wickham缔造(可去Hadley个人主页 和 这篇文章 膜拜下Hadley大神),另外,贴一下tidyverse部分核心成员的图以及Hadley出品的一本教程的封面图。

建模分析:Hmisc(提供各种用于数据分析的函数,且集成格式化和可视化处理)、car(提供了大量的增强版的拟合和评价回归模型的函数)、lme4和nlme(线性混合模型)、glmmTMB(广义线性混合模型)、Rstan(Stan概率编程语言的R语言接口,stan的数学库提供了可微的概率函数和线性代数,R包中还提供了基于表达式的线性建模,后验概率可视化和留一法交叉验证。Rstan介绍)、NMF(非负矩阵分解)、explore(建模预处理)、multcomp(各类线性模型的同时性检验)。
模型评价:pROC、ROCR、plotROC(绘制交互式ROC曲线图)。
其他:自助法(boot和bootstrap包)、JSON转换(rjson)、逐步回归系列(step、drop1、add1系列函数)、置换检验(coin和lmPerm包)、可视化数据挖掘(rattle包)、正则表达式辅助函数(可以使用stringr中的各种函数如str_match、str_extract、str_detect)、图像处理(EBImage为主、magick为辅)等、数据抓取(httr+xml2,但其实使用rvest就挺好)、处理PDF(pdftools可提取PDF文本信息及元数据信息,且兼容PDF中的表格数据,但对于换行操作仍是无可奈何;tabulizer可提取PDF中的表格数据,但是对于缺乏表格线的表格的提取效果不好)、并行运算(parallel、foreach以及future都不错)、数据分析工作流(tidycwl进行可视化)、其他文本工具(tidyxl整理excel、gridtext在网格中渲染文字、flextable为HTML和office绘制图表、jiebaR和chinese.misc处理中文分词)。
其他链接:use R for fun系列之玩转图像篇
生存分析
包括KM曲线、统计检验、各类生存模型、模型预测与评价、功效分析等等各个方面。
统计学生存模型:Cox模型、加法风险模型(相对Cox而言,Cox属于乘法风险模型)、Weibull模型、对数Logistic模型、加速失效时间模型(AFT)、竞争风险模型、重复事件分析、随机效应生存分析(混合效应模型)、贝叶斯生存分析、多状态模型等。
机器学习生存数据建模:正则化建模(glmnet)、决策树分析(包括条件推理树)、随机森林分析、Boosting建模(GBM)、Super Learner、SVM生存分析(survivalsvm)、神经网络生存分析(Python版本有个DeepSurv包)、复合协变量分析、监督主成分分析等等。基本上各种分类数据的机器学习方法和统计建模方法都可以推广到生存数据建模中来。
模型预测和评价:包括C-index、时间依赖ROC和AUC、NRI和IDI、预测误差等评估。
特别介绍的包
survminer:基于ggplot2,不仅能画出好看的KM曲线,还有各种辅助功能,比如选取连续变量的界值(surv_cutpoint),森林图(ggforest)、cox模型校正曲线(ggcoxadjustedcurves)、竞争风险(ggcompetingrisks)等。快速浏览可参考清单survminer_cheatsheet;具体文档可参考:survminer_rdocumentation、rpkgs_survminer、survminer R package: Survival Data Analysis and Visualization、Informative_Survival_Plots.Rmd等。
rms:相应地有一本书可以看看,Regression Modeling Strategies,很不错。
其他:npsurvSS可进行生存分析中的非参数检验(如5年时刻的生存率差异检验等)、样本量和功效估计等、RMST(restricted mean survival time,限制平均生存时间)的差异,可参考:npsurvSS
详细内容和其他包的介绍,请参考:CRAN Task View: Survival Analysis
机器学习和统计建模
包括各类机器学习模型,如:决策树(包括条件推理树)、随机森林、Boost类算法(包括xgboost)、SVM、神经网络算法、贝叶斯模型、遗传算法优化、正则化(惩罚)降维、模型选择和验证、集成建模(如 SuperLearner、各类综合性工具包)、可视化数据挖掘等,以及各种聚类分析(层次聚类、划分聚类(包括kmeans、k-medoids、pam、谱聚类等)、模型聚类 [如最大似然估计流派的EM聚类法、贝叶斯聚类]、二维聚类 [如样本和特征同时聚类]、马尔科夫聚类等),应有尽有。
特别介绍的包
caret:机器学习建模的大型工具集,官方文档为 caret、short_introduction_caret。涉及的模型200多个(可以查看:caret/available-models),涉及特征可视化(更直观地理解变量特点)、数据预处理(包括分类变量的处理 [哑变量化或因子化等] 、近似零方差特征的去除、相关特征和共线性特征的去除[当然个人觉得反而应当利用这种相关信息,不仅是pls]、变量的中心化和标准化、缺失值填补、特征变量变换 [包括PCA变换、Box-cox变换和Yeo-Johnnson变换 [正态化] 等;虽然一般说法是Box-cox变换只适用于因变量的转换,但笔者看了下一篇Yeo-Johnnson变换介绍的文章中提到这些方法也是可以对自变量进行转换的] )、数据分割(包括创建平衡数据 [createDataPartition]、交叉验证数据分割 [createFolds]、Bootstrap分割 [createResample] 、时间序列的数据分割等)、模型训练(包括调参、模型性能度量、模型选择 [ tolerance、oneSE、best 等策略,又称“one standard error”规则,即不选择CV值最小的模型,而是选择高于最小CV值一个标准差之内的最简模型,比如glmnet通常推荐lambda.1se,参考:模型选择的一些基本思想和方法 ]、模型的比较和相应的可视化)、类别不平衡的处理(包括二次抽样等)等。有人对caret包的文档进行了翻译 R语言caret包应用
factoextra:可以轻松提取和可视化探索性多变量数据分析的输出,包括PCA和聚类等。可参考:rpkgs_factoextra
还有几个比较受欢迎的包:mlr3、xgboost、h2o
glmpca:PCA的广义版本,可用于非正态分布(如泊松分布等)的降维。
modelStudio:实现一个交互式平台帮助解释机器学习模型。
tfprobability:提供一个与TensorFlow Probability的接口。
mlr3pipelines:实现机器学习pipeline操作。
interpret:实现机器学习可解释性的Boosting Machine(EBM)框架。
DiffXTables:检测异常模式(如二维分布的检验)。
orf:有序森林,估计有序分类模型的条件概率及可视化。
详细内容和其他方法,可参考:
机器学习:CRAN Task View: Machine Learning & Statistical Learning
聚类分析:CRAN Task View: Cluster Analysis & Finite Mixture Models
缺失数据处理:CRAN Task View: Missing Data
多元统计:CRAN Task View: Multivariate Statistics
可视化
R语言的可视化主要基于base和grid这两个包,其余可视化包都是在这两个包的基础上扩展。
最常用的两个工具包:ggplot2 和 lattice。凡是可视化,都可以尝试搜索这两个包能否搞定。另外,由于很多工具包侧重于计算而忽略了可视化的美观优化,因此推荐将计算结果提取出来,重新使用ggplot2或lattice作图。
ggplot2:ggplot2的体系是非常庞大的(cheatsheet里只是列举了最简单基础的示例罢了),作图可以非常灵活,要学完整个ggplot2的体系是要花不少时间的。可以参考:ggplot2官方介绍(有张Cheatsheet可供快速查阅)、ggplot2主文档(这个是学习ggplot2的主要阵地)、如何使用 ggplot2、ggplot2图集汇总、ggplot2高效实用指南。
lattice:lattice官方介绍(书的代码和图)、Getting Started with Lattice Graphics、使用lattice进行高级绘图、R绘图lattice包
基于ggplot2进一步扩展的包(详细可参考官方扩展介绍:ggplot2 extensions):
ggstatsplot:各类统计分析和可视化一行命令搞定,强力推荐(2020年补充:需R3.6版本,过段时间可更新R4.0)。
ggpubr: 生成杂志期刊等出版物的图形的包,是ggplot的一个补充
ggplotify:将其他类型的图转成ggplot类型
ggrepel:用于避免图形标签重叠
ggsci:SCI论文作图配色
ggtech:科技公司主题配色
ggthemes:提供扩展的图形风格主题
ggthemr:另一个惊艳的主题风格包,可参考:ggthemr助你制作惊艳美图
ggpomological:水果味的主题风格,很清新舒服。还有一个修改主题的包也不错:hrbrthemes。
ggtext:在ggplot中使用markdown/html语法构建文本(也支持插入图片),使用很舒服
ggcorrplot:相关性分析图的ggplot2版本
ggboxplot:箱线图的进一步加工
ggfortify:一行R代码来实现繁琐的可视化(有空的时候可以逛逛)
ggraph:用于绘制网络状、树状等特定形状的图形,用于绘制网络图等;
ggnetwork:网络状图形的geoms
ggradar:绘制雷达图
ggtree:树图可视化
ggVennDiagram:韦恩图
ggupset:韦恩图的upset版本
ggmap:提供Google Maps,Open Street Maps等流行的在线地图服务模块
ggiraph:绘制交互式的ggplot图形
ggthreed:ggplot画3D图
ggstance:实现常见图形的横向版本
ggalt:添加额外的坐标轴,geoms等
ggforce:添加额外geoms,比如桑基图、放大zoom图等
ggpmisc:各类ggplot相关扩展,还可以生成公式(拟合曲线)、各种图的组合、优化等等
geomnet:绘制网络状图形
ggExtra:绘制图形的边界直方图
gganimate:绘制动画图
ggspectra:绘制光谱图
ggTimeSeries:时间序列数据可视化
ggseas:季节调整工具
ggchicklet:圆角柱形图
ggvis:交互式图表多功能系统(Hadley Wickham出品的另一个强大的作图包,可参考ggvis 0.4 overview、ggvis包学习笔记之初识ggvis、ggvis交互式作图介绍)
ggdendro:画层次聚类树图(可参考:R画树状图:一种轻量级方法 )
ggparty:扩展partykit可视化(树模型 如决策树等)。
ggbubbles:各种气泡图,包括矩阵气泡图。
gghalves:对称ggplot图截取一般进行拼接。
ggRandomForests:随机森林(包括生存模型)的可视化工具。
ggforest:绘制森林图(如生存分析的森林图)。
plotrix:也是不错的作图工具,功能包括双坐标、坐标截断、3D饼图、扇图、钟表图、韦恩图、各种基本形状绘制等。
rayshader:一行代码将ggplot渲染为3D图(见过的最接近3D渲染效果),效果十分逼真,可从不同角度观看。
rayrender:也是一个3D渲染工具。
Complexheatmap:bioconductor出品的热图绘制工具,非常好用的热图绘制工具(可以借助其annotation的丰富功能,画出很多的图形组合,设置可以使用空矩阵绘制空热图从而仅保留annotation)。
corrplot:专注于画相关性图。
circlize:circos plot,可参考 用circlize包绘制circos plot、根据vcf文件计算SNP密度并用circlize可视化结果
circular:环形可视化,可绘制各种环形图,包括windrose图(玫瑰图)。
scales:提供图片坐标的scaling操作,由Hadley Wickham出品,可参考scales。
packcircles:圆形树图。
gridExtra:图片布局,还有patchwork也可以实现一图多页。
gplots:一些作图的优化,包括热图、boxplot、barplot、韦恩图。
scatterplot3d:3D作图工具,当然还有很多其他不错的3D作图包,如barplot3d等;可到Task View或网上搜索。
rgdal:绘制地图(有个不错的示例,EasyChart),和ggmap类似,还有 leaflet(交互式地图)。
ape:遗传进化树。
igraph:各种网络图。同类的还有tidygraph(可能在github上)
diagram:流程图。
cairoDevice:支持cairo和GTK。
RColorBrewer:配色工具,同类的还有colorspace、viridis、munsell等
showtext:修改base包作图的字体,可以任意修改。
rggobi:交互式作图系统。
rgl:交互式3D绘图
altair:altair是python中的强大的可视化工具,R语言也有了接口,借鉴过来。
其他
dygraphs:绘制交互式时间序列图,利用htmlwidgets开发的时间序列交互图形RStudio出品。
plotly:交互式绘图包
rbokeh:用于创建交互式图表和地图
Highcharter:绘制交互式Highcharts图
visNetwork:绘制交互式网状图
networkD3:绘制交互式网状图
d3heatmap:绘制交互式热力图
DT:用于创建交互式表格
threejs:绘制交互式3d图形和地球仪
rglwidget:绘制交互式3d图形
DiagrammeR:绘制交互式图表
MetricsGraphics:绘制交互式MetricsGraphics图
rCharts:提供了对多个JS可视化库(highcharts/nvd3/polychart)的R封装,可参考:rcharts、rCharts_1、rCharts_2。
recharts:Recharts是百度echarts的接口封装,目前有recharts,echartr等。
coefplot:可视化统计模型结果
latticeExtra:lattice绘图系统扩展包
animation:可以用来做动画。
waffle:善于画各种各样的格子。
coefplot:可视化统计模型系数估计。
wordcloud2:绘制词云。
ggPMX和ggResidpanel:拟合模型的诊断函数和绘图工具包。
radarBoxplot:雷达箱式图,支持多变量可视化。
graphlayouts:网络可视化布局工具包。
tidymv:可视化广义加性模型。
ormPlot:扩展了RMS回归建模策略,并提供不错的可视化。
basetheme:为base绘图提供主题选择。
nomnoml:绘制UML的工具。
hpackedbubble:基于Highcharts的打包气泡图。
sankeywheel:擅长各类桑基图以及和弦图。
关于拼图:https://www.sohu.com/a/289245806_613208
图形的grid操作:R语言grid包使用笔记——viewport
上述工具包无法解决的问题,可以再到网上搜索,或查看 CRAN Task View: Graphic Displays & Dynamic Graphics & Graphic Devices & Visualization
格式化输出
rmarkdown:准确说,rmarkdown属于文档报告工具,所有格式化输出都可以基于此。官方介绍很详细:rmarkdown,里面可以找到cheatsheets,另外也可参考这个rmarkdown标记的介绍:Rmarkdown用法与R语言动态报告。其中还应包括一些小工具,如:Dashboards(或flexdashboard制作dashboard原型、flexdashboard)、htmlwidgets、各种输出格式(包括输出PPT,PPT除了Rstudio官网推荐的那几个外,还有个叫slidify的包也很不错;此外,还有个包叫officer可以操控已有的PPT和Word,至此真正实现了全方位的R里面操作PPT和Word,不再只是生成PPT和Word而已了)、多文档构建网站(可以方便地呈现整个项目的报告,不同文档之间可以通过导航栏切换,也可以使用child链接下划线开头的Rmd fragments [参考:Rmd partials],或者试试使用html超链接中填入相对路径。此工具再结合flexdashboard就可以构建比较复杂的报告呈现了)、各种编程语言对接(见下文的“对接其他编程语言”)。
knitr:一款优秀的报告生成工具,以便数据分析可重复(分析报告敏捷的生成)。这个类似于Jupyter Notebook的功能。除了支持html以外,还支持Word、PDF的输出。据说这个比最初的Sweave好用很多。可参考:knitr、Overleaf guides、knitr 与可重复的统计研究、自动化报告。
kableExtra:输出美化的表格。可参考:kableExtra官方介绍、另一个类似的官方介绍。另外,flextable这个包也不错。输出表格的工具包还有很多,包括 Hmisc, NMOF, papeR, quantreg, rapport, reporttools, sparktex, tables, xtable, ztable等等,可以参考Task View介绍。
bookdown:可以用来写书(网络书本),确实是很方便的工具。还有blogdown用于快速构建博客。
tableone:快速构建统计论文的表1。可参考 快速绘制文章“表一”
export:可输出至PPT、Word、Excel、PDF等各种文件(好像这个包被CRAN移除了)。
flextable:可绘制图表并导出至html和office系列文档中。
bibtex:文献管理工具,此外还有 RefManageR 也是类似的功能。
latex2exp:LaTeX转化工具。
R2wd:输出word,此外还有R2PPT输出PPT。
formatR:格式化R代码。此外类似的还有 humanFormat、lubridate、highlight等。
textreuse:可以进行论文查重(暂时归类到格式化这里)。
其他:resumer(生成简历)、exams(考试相关)、htmltools(html相关,这方面还有很多工具)、markdown和rmarkdown、bookdown(创建书籍)等。
crayon:可用于在输出端添加颜色。
wordmatch:用于两个word的文本对照。
gluedown:提供R向量和降价文本之间的转换功能,可将字符串和markdown语法粘合在一起,可将带格式的向量打印到文档。
有一个叫 RPUBS的网站有不少使用knitr输出的文档。
Task View上还有很多,包括LaTeX、HTML、MarkDown的处理,Pipeline Toolkits,Project Workflows,格式化工具和格式转换工具等等。请参考:CRAN Task View: Reproducible Research
对接其他编程语言
Rmarkdown 和 knitr 配合,可以很方便地在Rstudio里写别的编程语言,可参考:rmarkdown/language-engines。
而对接数据需要一些包,比如对接python可以用 reticulate(可参考:reticulate),C++可以用Rcpp等。
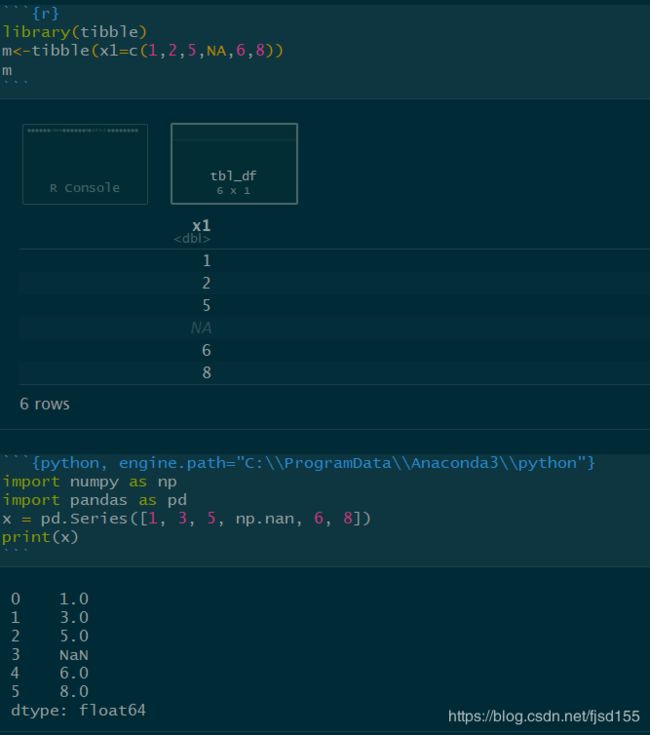
笔者暂时只尝试了如何在Rmarkdown里同时写R和Python,但数据的对接似乎有点问题,并不能像reticulate官方文档介绍的那样可以互相调用数据,总是报错说找不到指定路径中指定的python版本(暂时懒得折腾了,事情太多了,等以后要用的时候再搞搞,或者暂时用原来那种互相调用脚本的方式传递数据)。下面是一个OK的示例(无数据传递):
如果数据传递OK的话,那么这个工具可以实现复杂的数据分析过程,举个栗子:
假如有两种语言A和B,每个语言分成不同的步骤,比如A1,A2,A3;B1,B2,B3... 执行顺序可以是A1-B1-A2-B2...
其中,A2可以继续继承A1的所有变量,因为属于同一个Session,如果传统pipeline的话,A2需要重新初始化和加载数据
B1可以查看A1所有的细节,也可以对A1的变量进行修改(可读可写),也就是A2中可以自动获得这些修改结果。当然计算上,A和B仍是串行的(子步骤的交叉串行。若是要A和B并行、互相实施监督,那就得自己写工具实现了)。当然,这种串行组合,只适用于动态语言(如R、Python及JavaScript等),对于需要编译的静态语言(如C和Java)来说,只能调用编译后的执行程序。
另外,注意到Rmarkdown支持JavaScript,这就使得复杂的前端设计也有可能可以在Rmarkdown里完成。
不得不感慨一下,Rmarkdown确实很厉害,我们可以再Rmarkdown里方便地编写和调试python等其他语言以及数据对接,可以在R里做PPT准备汇报,可以在R里制作交互式html页面(尤其是R的某些包 [如 networkD3、recharts等] 还集成了一些JavaScript里很不错的UI,这使得本来就擅长于可视化的R更加强大了)。
临床研究
参考:CRAN Task View: Clinical Trial Design, Monitoring, and Analysis
工具包很丰富,包括样本量计算、区组随机、各期临床试验设计(计量爬坡、3+3设计)、药代动力学分析、三臂研究、适应性设计、功效分析等,临床研究相关的计算需求,都可以尝试到这里找找解决方案。
生信分析
待补充,可参考Bioconductor系列包。
CRAN中的有GeneNet、pam、ape等。
代谢组学:MetabolicSurV(整合了生存分析的代谢组学分析工具)、cliqueMS(基于MS进行注释的工具,2019年发表于Bioinformatics,值得研究下)。
UCSCXenaTools:数据库连接工具。
其他可能要用的
开发测试(列举几个Hadley Wickham出品的工具包):devtools(开发工具以及包管理)、testthat(测试工具)、Roxygen2(开发文档相关)、profvis(评估代码的运行时间和所需内存)。
R包的一次性加载和安装:pacman包,可参考:pacman包:在R中一次性安装加载多个包 ,这里面也提到了常规加载和安装多个包的方式(包比较多的时候不要一个个install和library)。
如下资源,在需要时到Task View界面查找即可(或Google百度搜索相关资料),无需进行额外汇总。
数据库:CRAN Task View: Databases with R
网络技术:CRAN Task View: Web Technologies and Services
贝叶斯:CRAN Task View: Bayesian Inference
概率分布:CRAN Task View: Probability Distributions
实验设计和分析:CRAN Task View: Design of Experiments (DoE) & Analysis of Experimental Data
遗传学:CRAN Task View: Statistical Genetics
并行与大数据:CRAN Task View: High-Performance and Parallel Computing with R
医学图像:CRAN Task View: Medical Image Analysis
Meta分析:CRAN Task View: Meta-Analysis
模型部署:CRAN Task View: Model Deployment with R
自然语言处理:CRAN Task View: Natural Language Processing
最优化问题:CRAN Task View: Optimization and Mathematical Programming
药代动力学:CRAN Task View: Analysis of Pharmacokinetic Data
系统发生学:CRAN Task View: Phylogenetics, Especially Comparative Methods
稳健建模:CRAN Task View: Robust Statistical Methods
时间序列分析:CRAN Task View: Time Series Analysis
CRAN Task View: gRaphical Models in R
相关知识充电
Nearest Shrunken Centroid:又称NSC 或 PAM(Prediction Analysis for Microarrays),详细内容可参考PAM: Prediction Analysis for Microarrays(内有PNAS论文链接)。主要用于生信数据的多分类问题。其主要思想是,与类别无关的特征的类内均值和整体均值相差很小,通过不断迭代类内均值和整体均值的差距界值进行降维(去除噪音),最终保留的基因被认为是有意义的特征。
加权最小二乘回归:针对因变量的异方差现象而提出。参考:异方差性以及加权最小二乘优化
非负最小二乘回归:指的是系数权重不能为负数时,如何求解线性回归。
分位数回归:其原理是将数据按因变量进行拆分成多个分位数点,研究不同分位点情况下时的回归影响关系情况。分位数线性回归可用加权最小二乘法求解。参考:分位数回归(Quantile Regression)、回归分析结果不稳定,还可以试试这种方法
二次判别分析:针对线性判别分析而言,二次判别分析可以划2根线。
稳健建模:主要是针对异常值而言,稳健建模可以判断异常值,从而更有效地反映真实情况。
Weibull回归:生存分析的参数模型。可参考 回归分析方法大杂谈——Weibull回归、实用的(却又被忽略的)Weibull回归
旋转森林:可参考 森林(随机森林、超随机树 和 旋转森林)。
极限机器学习:对于单隐层神经网络,极限机器学习ELM可以随机初始化输入权重和偏置并得到相应的输出权重。可用于分类和生存数据。参考:极限学习机(ELM)
Logic Regression:真正的“逻辑”回归。相关论文:Logic Regression。在看到这篇论文前,笔者就很想构建包含逻辑“或运算”的回归模型,并将这一思想用于某一个医学研究中,结果还不错。谁料竟然这也有人研究过了!这篇论文中,将逻辑运算和Logistic等常规模型进行融合,很符合笔者的预想。以下是相关R包文档中的截图:

EM聚类:一般指使用GMM聚类,而GMM的求解需使用EM算法。可参考 EM聚类学习笔记、EM聚类详细推导
谱聚类:是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间距离尽量距离较远,以达到常见的聚类的目的(这让笔者想到了马尔科夫聚类,不知道有没有人将其和谱聚类进行对比)。可参考 谱聚类(spectral clustering)原理总结、白话什么是谱聚类算法、【ML】谱聚类、谱聚类算法(Spectral Clustering)、[机器学习基础 21]白板推导 谱聚类等。
关于QQ图和PP图:参考自 QQ图和PP图
统计学里Q-Q图(Q代表分位数)是一个概率图,用图形的方式比较两个概率分布,把他们的两个分位数放在一起比较。首先选好分位数间隔。图上的点(x,y)反映出其中一个第二个分布(y坐标)的分位数和与之对应的第一分布(x坐标)的相同分位数。因此,这条线是一条以分位数间隔为参数的曲线。如果两个分布相似,则该Q-Q图趋近于落在y=x线上。如果两分布线性相关,则点在Q-Q图上趋近于落在一条直线上,但不一定在y=x线上。Q-Q图可以用来可在分布的位置-尺度范畴上可视化的评估参数。
从定义中可以看出Q-Q图主要用于检验数据分布的相似性,如果要利用Q-Q图来对数据进行正态分布的检验,则可以令x轴为正态分布的分位数,y轴为样本分位数,如果这两者构成的点分布在一条直线上,就证明样本数据与正态分布存在线性相关性,即服从正态分布。
P-P图是根据变量的累积概率对应于所指定的理论分布累积概率绘制的散点图,用于直观地检测样本数据是否符合某一概率分布。如果被检验的数据符合所指定的分布,则代表样本数据的点应当基本在代表理论分布的对角线上。
由于P-P图和Q-Q图的用途完全相同,只是检验方法存在差异。要利用QQ图鉴别样本数据是否近似于正态分布,只需看QQ图上的点是否近似地在一条直线附近,而且该直线的斜率为标准差,截距为均值。用QQ图还可获得样本偏度和峰度的粗略信息。
使用R代码重头实现QQ图(当然有各种各样的现成的包可以实现QQ图,包括qqplot和qqnorm函数等)
n<-100
m<-30
x<-rnorm(n,mean=10,sd=5)
a<-sample(n,m)
y<-rnorm(m,mean=10,sd=20)
x[a]<-y
hist(x)
x<-sort(x)
Theoretical<-qnorm(c(1:n)/n,mean=0,sd=1) # qnorm可用于计算正态分布的百分位值
plot(x~Theoretical,pch=19)
abline(mean(x),sd(x))
核密度估计
非参数估计:核密度估计KDE
概率密度估计介绍
面向对象编程
S3和S4对象,可参考《R语言实战》这本书,以及网上某些参考资料:R语言面向对象编程、【r<-高级|理论】R的函数
R语言里还有各种技巧:比如类的操作(可以随时修改一个对象的class)、函数的操作(可以随时修改一个函数的参数列表、函数体)。data.frame本质上是多个等长list,美元符号和嵌套中括号的使用,unclass的使用,attr的使用,环境的使用(环境内变量的调用),可变参数列表的使用,变量可通过get获取value,有一种类叫formula,可以保存y~x这种公式,泛型函数的构建和使用等等,具体可读读《R语言实战》以及网上的资料。
另外,S3通过泛型函数实现面向对象编程,S3也可以实现类的继承,可参考:R语言面向对象编程 和 R语言基于S3的面向对象编程 中的示例。S3要实现比较复杂的类操作时,代码也会显得臃肿,而且没有类型检查机制,是一种不安全、比较随意、容易出错的方式。给笔者的感觉就是,伪装的面向对象编程,总感觉怪怪的。
而S4就比较有感觉了,这一套做法很大程度上和Java之类的很像,容易理解和使用(类的创建、实例化、继承、接口方法等等都和Java中的有点像),而且有类型检查。具体可参考:R语言基于S4的面向对象编程。
此外还有R6对象系统,笔者暂时没了解。面向对象编程的好处在于封装和继承,这是使得一些通用逻辑得以复用的技巧,这在大型复杂项目中,可以使得代码进一步优化。平时使用R语言不太需要接触这些,暂时了解不多,以后若有机会在这个领域继续从事更多的工作,则可以再找时间研究下更多的细节。
层次分析法
R中构建层次分析法(运筹决策分析中的一种,而不是分层效应模型),可参考:R语言构建层次分析模型不看一下吗
琐碎记录
Nomogram的教程:Logistic、Cox回归之图形化呈现(R语言中绘制Nomogram)、教你用R画列线图,形象展示预测模型的结果、基于R的生存资料预测模型构建与Nomogram绘制
ggplot绘图细节汇总:ggplot2中如何设置坐标轴大小等绘图细节(总结整理)
生存分析的一些资料:
R语言-Survival analysis(生存分析)
Survival Analysis Basics
使用R进行生存分析
计算生存率和p值
R语言 生存分析
R语言做热图:R语言绘制热图——pheatmap
R语言中各种假设检验:R语言各种假设检验实例整理(常用)
常用的数据可视化图表(当然这个内容不限于R语言):数据可视化:基本图表
R教程:R语言教程
不错的R包:KableExtra包做复杂的表格比较棒(代码直接生成HTML表格或LaTeX式表格)。
shiny:R语言只做小网页的工具包。
Rmd:R文档工具。
将矩阵转为列表
如何将矩阵转换为R中列向量的列表
------------------------------------------------------------------------
比较两个模型C-index的差异:可以使用Hmisc包中的rcorrp.cens方法。
比较两个模型AUC的差异,也有类似的方法,也可以用AUC的差异比较统计量(有个公式)直接计算p值。
calibration的计算,有一个地方容易搞错,就是在cph构造时,应当设置time.inc参数,并且与之后的calibrate构造时的u参数一致。网上很多资料没注意到这个细节,所得结果实际上是有问题的。甚至有的资料直接以为calibrate中的u参数只要与surv构造时的time一致就行,这是有问题的。
有一个不是很理解的东西:psm——parametric survival model,参数生存模型,这个体系不了解。rms包中多次提及这个方法,之后可以研究下。比较psm与cox的优劣和适用场景。
------------------------------------------------------------------------
一个关于purrr包的应用实例
有人找我讨论这样一个问题,想对数据集进行分组划分后,对任意两个变量进行运算(如任意两个变量之间的回归或相关分析),并将所有的统计结果汇总成表,非循环的写法如何实现?
该问题的简单版是purrr包教程中的一个例子(代码来源不明,但purrr包官方介绍和各类教程中有很多类似的例子,可参考:purr官方网站、purrr-tutorial、reference_purrr、purrr、cheatsheets_purrr):
mtcars %>%
split(.$cyl) %>% ## from base package
map(~ lm(mpg ~ wt, data = .)) %>%
map(~broom::glance(.)) %>%
reduce(bind_rows)这个限定了回归的formula,能否改成任意两个变量之间的回归呢?于是笔者将原代码修改成如下代码:
matrix_1<-combn(c(1:5),2)
list_1<-split(matrix_1, rep(1:ncol(matrix_1), each = nrow(matrix_1)))
compute_<-function(d){
return(map(list_1,~tibble(y=d[,.x[1]],x=d[,.x[2]])) %>%
map(~lm(y ~ x, data = .)) %>%
map(~broom::glance(.)) %>%
reduce(bind_rows))
}
mtcars %>%
split(.$cyl) %>%
map(~compute_(.)) %>%
reduce(bind_rows)本质上就加了一行“重构数据表”,因为直接修改formula似乎行不通,笔者尝试了预处理formula列表再转命令行的方式,似乎在管道中某些数据传不进去:
eval(parse(text = formula))问题解决了,这里再附几个关于tidyverse相关的链接可以瞅瞅:
purrr的一个官方例子讲解
purrr包的另一个例子(博主嵌套使用map实现需求)
------------------------------------------------------------------------
回想一下,笔者曾靠着R的基本函数,重复造了很多轮子,虽然各种需求都能实现,但是效率不高。还是要转变思维,不用动不动就重头写代码,多用用别人写好的工具,人生苦短啊。
资源链接
R语言的工具包真的很多,不可能全列举出来,还有很多很多不错的包没接触过,以及有很多包的文档没去了解,在需要的时候可以参考下面这些链接或工具。
R Packages各类文档收集
R语言packages列表 | 分类 (里面列举了很多很多包,这个公众号会定期更新列表)
cran-packages
rOpenSci(收集了各类科研文献数据相关的工具包)
学习一个包,可以先到CRAN上找找看有没有包的文档官网链接(优先级为:Vignettes、URL、Reference manual)
搜介绍文档的另一种可能方法(以dplyr包为例):在R中运行vignette("dplyr")或browseVignettes("dplyr"),或者将链接https://cran.r-project.org/web/packages/dplyr/vignettes/中的dplyr替换成需要的包名试试 。
寻找R包的工具:cranly、dlstats和packagefinder,可以参考:如何搜索你想要的R包、cranly:你的R包管理工具 。
github: awesome-R(末尾还有很多不错的资源链接和书的推荐)
rdocumentation
rdrr.io
rnotebook
R成精系列-R语言的常用的包
R/Python 数据科学实战
cheatsheets for R
与R无关的链接:github: awesome-cheatsheet、awesome-awesomeness(awesome的awesome)
CRAN Task Views:R资源的一个整理集合,需要寻找资源时可优先到这里找找。
CRAN Task View: Survival Analysis
CRAN Task View: Machine Learning & Statistical Learning
CRAN Task View: Bayesian Inference
CRAN Task View: Clinical Trial Design, Monitoring, and Analysis
CRAN Task View: Cluster Analysis & Finite Mixture Models
CRAN Task View: Databases with R
CRAN Task View: Probability Distributions
CRAN Task View: Design of Experiments (DoE) & Analysis of Experimental Data
CRAN Task View: Statistical Genetics
CRAN Task View: Graphic Displays & Dynamic Graphics & Graphic Devices & Visualization
CRAN Task View: High-Performance and Parallel Computing with R
CRAN Task View: Medical Image Analysis
CRAN Task View: Meta-Analysis
CRAN Task View: Missing Data
CRAN Task View: Model Deployment with R
CRAN Task View: Multivariate Statistics
CRAN Task View: Natural Language Processing
CRAN Task View: Optimization and Mathematical Programming
CRAN Task View: Analysis of Pharmacokinetic Data
CRAN Task View: Phylogenetics, Especially Comparative Methods
CRAN Task View: Reproducible Research
CRAN Task View: Robust Statistical Methods
CRAN Task View: Time Series Analysis
CRAN Task View: Web Technologies and Services
CRAN Task View: gRaphical Models in R