手把手教你:如何将ML_GCN用于自己的项目
目录
前言
一、胸部疾病之间的关联信息
二、网络架构
1、GCN网络的输入
2、GCN网络的计算公式
三、GCN加入自己的网络中
四、总结
前言
最近的工作是做X线胸片疾病的多标签分类研究,使用Basline已经可以达到比较高的AUC指标了,最近在思考有没有其他的idea能够将AUC指标提升一下。了解到一个可以提升地方就是利用标签之间的关系信息,即每一种疾病之间都存在关联信息,我想要将该关联信息利用起来从而提升模型的性能,在经过一番搜索之后,找到了旷视发布的这篇论文《Multi-Label Image Recognition with Graph Convolutional Networks》,它使用GCN网络来挖掘标签之间的关联信息,并表示“取得了不错的效果”,是2019年CVPR,同时开源了代码https://github.com/Megvii-Nanjing/ML-GCN。
本篇博客介绍如何在我自己的项目中使用这个GCN网络,让我们进入正题!
一、胸部疾病之间的关联信息
如果对我所做的工作有兴趣,可以查看我的论文笔记:
论文笔记:CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison
许多多标签分类任务的标签之间都是有关联信息的,胸部疾病间也不例外。

如上图所示,Lung Opacity与Consolidation、Atelectasis等疾病存在父子关系,即如果患有Consolidation疾病,那么一定会患Lung Opacity疾病,在官方提供的Baseline方法中并没有挖掘这些关系,于是这便是我们可以改进的地方。
二、网络架构
网络架构如下图所示,CNN部分用来提取图像特征(维度为Dx1),GCN部分用来提取标签间的关联信息(维度为DxC,C是指分类的类别数),最后用点乘得到Cx1维的输出。(值得提一下的是这个网络最后并没有使用全连接层)

CNN部分是一个常规的框架,重点看一下GCN框架部分(GCN的推导原理我不多解释,本篇博客重点是如何使用GCN),要使用GCN框架,我只需要知道两个部分的内容:1、GCN网络的输入 2、GCN网络的公式,下面我主要介绍这两部分。
1、GCN网络的输入
GCN网络的输入是所需要分类类别的Word Embedding(词向量),我的数据集就是14种类别的Word Embedding。
什么是词向量?
可能有一部分只接触过CV,没接触过NLP的朋友不怎么了解词向量是个什么东西,我用自己的理解简单解释一下:平时我们一般表示一个词都是使用One-hot的方式,但是这样有一个问题,就是词之间的关系信息并没有包含在One-hot的表示方法中,举个栗子:One-hot的方式[1,0,0]表示“小哥哥”,[0,1,0]表示“小姐姐”,[0,0,1]表示”天空“,这样会存在问题,我们求”小哥哥“和”小姐姐“向量的余弦相似度为0,”小哥哥“和”天空“的余弦相似度也为0,按照常理来说”小哥哥“和”小姐姐“关联性应该要比”小哥哥“和”天空“的关联性要强,但是使用One-hot编码的形式并没有包含这种关联性。Word Embedding的方式能够包含这些相关性,因为它的每一个词的向量表示是通过使用相应的训练方法训练词库得到,所以词的相关信息都是包含在词的向量当中。(这只是我个人的理解,如果我没有解释清楚,可以自行百度、谷歌查阅)
我们如何获取和使用词向量?
论文中是使用Glove方法训练好的词向量,当然也有FastText、GoogleNews等方法训练的词向量,但是经过作者做实验比较发现差别都差不多,使用Glove方法训练的词向量作为GCN的输入,结果要略好一些,所以最终使用Glove训练的词向量。
以下代码是如何获取和使用Glove训练好的词向量,最后保存为pkl类型是为了训练的时候直接使用。
import torch
#如果没有torchtext包 需要使用命令 pip install torchtext 安装torchtext包
import torchtext.vocab as vocab
# 计算余弦相似度
def Cos(x, y):
cos = torch.matmul(x, y.view((-1,))) / (
(torch.sum(x * x) + 1e-9).sqrt() * torch.sum(y * y).sqrt())
return cos
if __name__ == '__main__':
total = np.array([])
#选择自己所需要的词向量集
glove = vocab.GloVe(name="6B", dim=300)
# No Finding类别
# glove.stoi[]方法是获取对应的词向量的index下标
# glove.vectors[]方法是获取对应词向量下标的词向量
no = glove.vectors[glove.stoi['no']]
finding = glove.vectors[glove.stoi['finding']]
no_finding = no + finding
total = np.append(total, no_finding.numpy())
#......此处省略其他几个类别的代码
#lung opacity类别
lung = glove.vectors[glove.stoi['lung']]
opacity = glove.vectors[glove.stoi['opacity']]
lung_opacity = lung + opacity
total = np.append(total, lung_opacity.numpy())
# Atelectasis
atelectasis = glove.vectors[glove.stoi['atelectasis']]
total = np.append(total, atelectasis.numpy())
# Fracture
fracture = glove.vectors[glove.stoi['fracture']]
total = np.append(total, fracture.numpy())
#我总共有14个类别,所以这个地方写14
total = total.reshape(14, -1)
#保存对应类别的word embedding
pickle.dump(total, open('./glove_wordEmbedding.pkl', 'wb'), pickle.HIGHEST_PROTOCOL)
#可以打印输出看一下余弦相似度
print("NO Finding和Fracture的余弦相似度:", Cos(no_finding, fracture))
print("Lung Opacity和Atelectasis的余弦相似度:", Cos(lung_opacity, atelectasis))
print("Lung Opactiy和Fracture的余弦相似度:", Cos(lung_opacity, fracture))
输出:
NO Finding和Fracture的余弦相似度: tensor(0.0954)
Lung Opacity和Atelectasis的余弦相似度: tensor(0.2576)
Lung Opactiy和Fracture的余弦相似度: tensor(0.2670)
从余弦相似度的结果可以看出NO Finding(健康)和Fracture(骨折)的相关性很小,而Lung Opacity和Fracture存在一点相关性,这些都是符合常理的。
2、GCN网络的计算公式
![]()
公式如上,![]() 为第l层GCN网络的输出,
为第l层GCN网络的输出,![]() 是一个已经经过处理的相关矩阵,
是一个已经经过处理的相关矩阵,![]() 为第l层GCN网络的输入(即第l-1层GCN网络的输出),
为第l层GCN网络的输入(即第l-1层GCN网络的输出),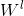 (转移矩阵)为第l层GCN网络可以学习的参数。
(转移矩阵)为第l层GCN网络可以学习的参数。
正如我们上面所说,最开始网络的输入是Word Embedding,即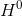 是通过Glove训练得到的word embedding。
是通过Glove训练得到的word embedding。![]() 是可以学习的参数,我们可以一开始随机初始化,h()表示激活函数,一般使用的是LeakyReLU激活函数。现在问题是我们如何得到
是可以学习的参数,我们可以一开始随机初始化,h()表示激活函数,一般使用的是LeakyReLU激活函数。现在问题是我们如何得到![]() ?
?
如何获取![]() 矩阵?
矩阵?
要得到![]() ,首先要得到A,下面我们先介绍github中util.py文件里面获取A和
,首先要得到A,下面我们先介绍github中util.py文件里面获取A和![]() 的代码。
的代码。
#官方提供的github代码中的util包
#gen_A()相当于得到A矩阵
def gen_A(num_classes, t, adj_file):
import pickle
result = pickle.load(open(adj_file, 'rb'))
_adj = result['adj']
_nums = result['nums']
_nums = _nums[:, np.newaxis]
_adj = _adj / _nums
_adj[_adj < t] = 0
_adj[_adj >= t] = 1
#ps:这个地方好像跟论文里面的公式有出入,但是它代码是这样写的,我也就按照它代码来处理
_adj = _adj * 0.25 / (_adj.sum(0, keepdims=True) + 1e-6)
_adj = _adj + np.identity(num_classes, np.int)
return _adj
#gen_adj()相当于通过A得到A_hat矩阵
def gen_adj(A):
D = torch.pow(A.sum(1).float(), -0.5)
D = torch.diag(D)
adj = torch.matmul(torch.matmul(A, D).t(), D)
return adj由上面的代码可以看出,官方已经提供了获取A矩阵的代码,我们自己需提供num_class、t、adj_file这三个参数,num_class是自己的类别数,t表示阈值官方使用的是0.3,adj_file是我们自己需要生成的文件。
adj_file文件是一个字典,里面包含了adj和nums。
下面是我本地训练集数据的保存格式,我需要通过统计训练集数据中每对标签出现的次数,从而获取自己的adj_file文件。
![]()
#这是自己写的生成adj_file的代码
def make_adj_file():
#opt.train_csv是我自己训练集的绝对地址
dataset = load_data(opt.train_csv)
#opt.classes是我分类类别的字段列表,总共是14个类别,相当于将前面几个Path,Sex,Age等5个字段数据去掉了
dataset = dataset[opt.classes].values
#共现矩阵 shape is (14,14)
adj_matrix = np.zeros(shape=(len(opt.classes), len(opt.classes)))
#每个类别出现的总次数 shape is (14, )
nums_matrix = np.zeros(shape=(len(opt.classes)))
'''
算法思路
一、遍历每一行数据
1、统计每一行中两两标签出现次数(自己和自己的不统计在内,即adj_matrix是一个对称矩阵且对角线为0)
2、统计每一行中每个类别出现的次数
'''
for index in range(len(dataset)):
data = dataset[index]
for i in range(len(opt.classes)):
if data[i] == 1:
nums_matrix[i] += 1
for j in range(len(opt.classes)):
if j != i:
if data[j] == 1:
adj_matrix[i][j] += 1
adj = {'adj': adj_matrix,
'nums': nums_matrix}
pickle.dump(adj, open('./adj.pkl', 'wb'), pickle.HIGHEST_PROTOCOL)就此我们已经得到了word embedding(GCN网络的输入,通过Glove预先训练好的词向量得到)、A(通过gen_A()函数得到)、![]() (通过gen_adj(A)函数得到)、W转移矩阵(随机初始化得到)。
(通过gen_adj(A)函数得到)、W转移矩阵(随机初始化得到)。
三、GCN加入自己的网络中
要将GCN加入我们自己的网络中,只需要将github中model.py里面的代码加入到自己网络的代码结构中去就行了。我的CNN部分使用的是DenseNet-121,而原论文中使用的是ResNet,所以我进行了一点微小的调整。(我只使用了model.py里面的GCN网络结构代码,以及util.py中生成A和![]() 的代码)
的代码)
#将model.py中的GCNResnet类改成我自己的GCNDensenet类
class GCNDensenet(nn.Module):
#in_channel是指词向量的维度,即一个词由300维的向量表示,t表示阈值,adj_file是我们上面生成adj_file的文件地址
def __init__(self, model, num_classes, in_channel=300, t=0, adj_file=None):
super(GCNDensenet, self).__init__()
self.features = model.features
self.num_classes = num_classes
self.pooling = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.gc1 = GraphConvolution(in_channel, 1024)
#self.gc2 = GraphConvolution(1024, 2048) 因为我densenet-121最后的feature是1024维,所以把这个地方的2048改成了1024
self.gc2 = GraphConvolution(1024, 1024)
self.relu = nn.LeakyReLU(0.2)
#获取A矩阵
_adj = gen_A(num_classes, t, adj_file)
self.A = Parameter(torch.from_numpy(_adj).float())
# image normalization 由于我的数据都已经归一化过了,所以这部分就没有用
# feature就是CNN网络的输入,inp就是word embedding
def forward(self, feature, inp):
# Densenet feature extract
feature = self.features(feature)
feature = self.pooling(feature)
feature = feature.view(feature.size(0), -1)
#the shape of feature is (batch_size, 1024)
# 2层的GCN网络
# word embedding
adj = gen_adj(self.A).detach()
x = self.gc1(inp, adj)
x = self.relu(x)
x = self.gc2(x, adj)
#the shape of x is (类别数, 1024)
x = x.transpose(0, 1)
x = torch.matmul(feature, x)
return x其他部分代码都是自己的项目相关的代码,就不展示了。
四、总结
完成这些步骤之后,我终于实现在自己的网络中加入GCN模块。然鹅,当我对这个新网络进行训练之后发现,我的AUC指标并没有提升!(我花了大把精力调研、学习GCN,并把它加入到自己的网络结构中,竟然木得提升!)基本和不使用GCN模块的AUC指标差不多,呜呜呜(我突然就变成了一个爱哭鼻子的傻瓜),当然,上网也看了一下其他人实现的效果,好像大部分人都表示GCN加入到网络中作用不大,有些质疑原论文的效果。(咋也不知道,咱也不敢问,毕竟人家是2019年的CVPR),我只好相信可能是我自己的实现或者调参部分存在问题吧。
希望这篇将GCN加入到我自己项目中的博客对大家的工作有所帮助吧,欢迎大家评论区拍砖、斧正!
参考:https://blog.csdn.net/weixin_44880916/article/details/104361378
https://blog.csdn.net/weixin_36474809/article/details/89316439
https://github.com/Megvii-Nanjing/ML-GCN
《Multi-Label Image Recognition with Graph Convolutional Networks》