人工神经网络(ANN)介绍
生物神经元
人脑有数十亿个神经元。神经元是人脑中相互连接的神经细胞,参与处理和传递化学信号和电信号。

以下是生物神经元的重要组成部分:
- 树突 – 从其他神经元接收信息的分支
- 细胞核 – 处理从树突接收到的信息
- 轴突 – 一种被神经元用来传递信息的生物电缆
- 突触 – 轴突和其他神经元树突之间的连接
人脑神经元处理信息的过程:多个信号到达树突,然后整合到细胞体中,如果积累的信号超过某个阈值,就会产生一个输出信号,由轴突传递。
人工神经元
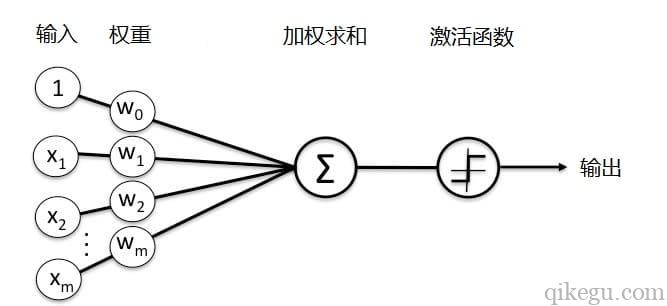
人工神经元是一个基于生物神经元的数学模型,神经元接受多个输入信息,对它们进行加权求和,再经过一个激活函数处理,然后将这个结果输出。
生物神经元对照人工神经元
| 生物神经元 |
人工神经元 |
| 细胞核 |
节点 (加权求和 + 激活函数) |
| 树突 |
输入 |
| 轴突 |
带权重的连接 |
| 突触 |
输出 |
人工神经网络
人工神经网络,模仿哺乳动物大脑皮层的神经系统,但规模要小得多。它由许多简单的处理单元(神经元)互联组成,这些处理单元(神经元)的作用类似于生物神经元,接受信息输入,处理后向下一层输出信息。
人工神经网络由多层神经元组成。层与层之间的神经元有连接,而层内之间的神经元没有连接。最左边的层叫做输入层,这层负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层。

人工神经网络的训练
给神经网络输入一批样本数据,神经网络会产生输出。比较神经网络的输出与样本中的正确结果,根据两者的差值,对神经网络的权重进行调整,使差值变小。重复这个过程,直到神经网络产生正确输出,从而确定神经网络的权重值完成训练。
训练好的神经网络就可以用来处理数据,给神经网络输入数据,给出正确的输出。
所以,所谓神经网络的训练过程,实际上就是确定神经元之间输入权重的过程。

如上图所示,具体训练过程如下:
- 给神经网络输入一批样本数据,经过神经网络传输到输出层,这一步被称为前向传播。
- 计算损失函数的值,损失函数的值表示预测结果(Prediction Y)和已知结果(True label Y)之间的差值。
- 使用优化器(Optimizer,通常使用梯度下降算法与反向传播算法),调整权重值,使差值变小。
重复以上3个步骤训练权重,直到损失函数的值(差值)最小,确定最终的权重值,完成训练。
注意: 关于人工神经网络的详细内容,可参考我们的深度学习教程。
TensorFlow 人工神经网络例子
TensorFlow中,Estimator是一种可极大地简化机器学习编程的高阶API。Estimator 会封装下列操作:
- 训练
- 评估
- 预测
- 导出以供使用
开发人员可以使用TensorFlow预创建的 Estimator,也可以编写自定义 Estimator。所有 Estimator(无论是预创建的还是自定义)都是基于 tf.estimator.Estimator 类的类。
这一部分,我们将学习使用TensorFlow的高阶APIEstimator中的DNNClassifier训练神经网络,DNNClassifier是一个神经网络分类器的实现。训练数据集我们将采用MNIST数据集。
MNIST(Modified National Institute of Standards and Technology database)是一个手写数字的大型数据库,通常作为各种图像识别系统的训练数据集,该数据集包含了从0到9的手写数字的28×28像素图像的集合,现在已经成为英语数字训练的标准数据集。

该神经网络训练好后,功能是能够识别手写数字。
用TensorFlow训练神经网络并不复杂,我们将按以下步骤进行:
- 导入数据
- 转换数据
- 构造张量
- 构建模型
- 训练和评估模型
- 改进模型
1. 导入数据
首先需要导入必要的库,除了TensorFlow,我们将使用:
- numpy 计算、处理多维数组的python包
- sklearn 机器学习相关的包,包含许多有用的函数
sklearn可用于导入MNIST数据集,预处理数据等。
import numpy as np import tensorflow as tf
openml.org是一个分享机器学习数据和实验的公共存储库,每个人都可在上面分享、下载数据集。sklearn.datasets包中的fetch_openml函数可以从openml存储库下载数据集。我们将使用该函数从openml.org下载MNIST数据集,下载会花几分钟时间。
MNIST数据集中包含了样本特征集mnist.data及样本标签mnist.target。
# 导入sklearn库中fetch_openml函数,下载MNIST数据集 from sklearn.datasets import fetch_openml mnist = fetch_openml('mnist_784') print(mnist.keys()) print(mnist.data.shape) print(mnist.target.shape)
使用train_test_split函数将数据集随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42) y_train = y_train.astype(int) y_test = y_test.astype(int) batch_size = len(X_train) # 查看训练样本子集、训练样本标签子集、测试样本子集、测试样本标签子集的形状 print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
train_test_split函数的参数解释:
train_data:被划分的样本特征集train_target:被划分的样本标签test_size:如果是浮点数,在0-1之间,表示测试子集占比;如果是整数的话就是测试子集的样本数量random_state:是随机数的种子
随机数种子
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。随机数种子,其实就是该组随机数的编号,在需要重复试验的时候,种子相同可以保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下,得到的随机数组是一样的,但填0或不填,则每次都会不一样。
2. 数据预处理
在进行训练之前,需要对数据集作归一化处理,可以提高模型收敛速度和模型精度。我们将使用最小最大值标准化方法,该方法的公式是:
(X-min_x)/(max_x - min_x)
sklearn库中已经为此提供了一个函数: MinMaxScaler()
## 导入MinMaxScaler from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # 训练样本子集 X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) # 测试样本子集 X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
3. 构造张量
构造输入特征列张量。TensorFlow中的特征列可以视为原始数据和 Estimator 之间的媒介。特征列功能强大,可以将各种原始数据转换为 Estimator 可以使用的格式。
feature_columns = [tf.feature_column.numeric_column('x', shape = X_train_scaled.shape[1:])]
4. 构建模型
该神经网络结构包含两个隐藏层,第一层为300个神经元,第二层为100个神经元。这些值都是经验值,你可以尝试调整这些值,看看它如何影响网络的准确性。
要构建模型,可以使用estimator.DNNClassifier。
estimator = tf.estimator.DNNClassifier( feature_columns=feature_columns, hidden_units=[300, 100], n_classes=10, model_dir = './train/DNN')
参数
feature_columns: 定义要在网络中使用的特征列hidden_units: 定义隐藏层的神经元数量n_classes: 定义要预测的分类数量,这里是0~9,是10个类model_dir: 定义TensorBoard的路径
5. 训练和评估模型
可以使用numpy方法来训练和评估模型。
# 训练模型 train_input = tf.estimator.inputs.numpy_input_fn( x={"x": X_train_scaled}, y=y_train, batch_size=50, shuffle=False, num_epochs=None) estimator.train(input_fn = train_input,steps=1000) # 评估模型 eval_input = tf.estimator.inputs.numpy_input_fn( x={"x": X_test_scaled}, y=y_test, shuffle=False, batch_size=X_test_scaled.shape[0], num_epochs=1) result = estimator.evaluate(eval_input, steps=None) print(result)
输出
{'accuracy': 0.9720714, 'average_loss': 0.09608318, 'loss': 1345.1646, 'global_step': 4000}
可以看到,现在模型的准确率为97%。
6. 改进模型
为减少过拟合,添加正则化参数来改进模型。我们设置dropout率为0.3,使用Adam Grad优化器:tf.train.ProximalAdagradOptimizer, 设置以下参数:
- 学习速率: learning_rate
- L1正则化: l1_regularization_strength
- L2正则化: l2_regularization_strength
estimator_imp = tf.estimator.DNNClassifier( feature_columns = feature_columns, hidden_units = [300, 100], dropout = 0.3, n_classes = 10, optimizer=tf.train.ProximalAdagradOptimizer( learning_rate=0.01, l1_regularization_strength=0.01, l2_regularization_strength=0.01 ), model_dir = './train/DNN1') estimator_imp.train(input_fn = train_input, steps=1000) result = estimator_imp.evaluate(eval_input, steps=None) print(result)
输出
{'accuracy': 0.94292855, 'average_loss': 0.2078176, 'loss': 2909.4463, 'global_step': 1000}
完整代码:
import tensorflow.compat.v1 as tf import numpy as np tf.compat.v1.disable_eager_execution() # 导入sklearn库中fetch_openml函数,下载MNIST数据集 from sklearn.datasets import fetch_openml mnist = fetch_openml('mnist_784') print(mnist.keys()) print(mnist.data.shape) print(mnist.target.shape) from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42) y_train = y_train.astype(int) y_test = y_test.astype(int) batch_size = len(X_train) # 查看训练样本子集、训练样本标签子集、测试样本子集、测试样本标签子集的形状 print(X_train.shape, y_train.shape, X_test.shape, y_test.shape) from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42) y_train = y_train.astype(int) y_test = y_test.astype(int) batch_size = len(X_train) # 查看训练样本子集、训练样本标签子集、测试样本子集、测试样本标签子集的形状 print(X_train.shape, y_train.shape, X_test.shape, y_test.shape) ## 导入MinMaxScaler from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # 训练样本子集 X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) # 测试样本子集 X_test_scaled = scaler.fit_transform(X_test.astype(np.float64)) feature_columns = [tf.feature_column.numeric_column('x', shape = X_train_scaled.shape[1:])] estimator = tf.estimator.DNNClassifier( feature_columns=feature_columns, hidden_units=[300, 100], n_classes=10, model_dir = './train/DNN') # 训练模型 train_input = tf.estimator.inputs.numpy_input_fn( x={"x": X_train_scaled}, y=y_train, batch_size=50, shuffle=False, num_epochs=None) estimator.train(input_fn = train_input,steps=1000) # 评估模型 eval_input = tf.estimator.inputs.numpy_input_fn( x={"x": X_test_scaled}, y=y_test, shuffle=False, batch_size=X_test_scaled.shape[0], num_epochs=1) result = estimator.evaluate(eval_input, steps=None) print(result) estimator_imp = tf.estimator.DNNClassifier( feature_columns = feature_columns, hidden_units = [300, 100], dropout = 0.3, n_classes = 10, optimizer=tf.train.ProximalAdagradOptimizer( learning_rate=0.01, l1_regularization_strength=0.01, l2_regularization_strength=0.01 ), model_dir = './train/DNN1') estimator_imp.train(input_fn = train_input, steps=1000) result = estimator_imp.evaluate(eval_input, steps=None) print(result)
执行结果:
{'accuracy': 0.94292855, 'average_loss': 0.2078176, 'loss': 2909.4463, 'global_step': 1000}
减少过拟合的参数设置,并没有提高模型的精度,第一个模型的准确率为97%,而L2正则化模型的准确率为94%。你可以尝试使用不同的值,看看它如何影响准确度。
小结
本篇教程中,我们学习了如何构建一个神经网络。神经网络需要:
- 隐藏层的数量
- 每个隐藏层内神经元的数量
- 激活函数
- 优化器
- 输出的分类数量
在TensorFlow中,你可以使用tf.estimator.DNNClassifier训练一个神经网络来解决分类问题,需要设置的参数如下:
- feature_columns=feature_columns,
- hidden_units=[300, 100]
- n_classes=10
- model_dir
可以使用不同的优化器来改进模型。我们学习了如何使用Adam Grad优化器和学习率,并设置了防止过度拟合的控制参数。