PyTorch学习笔记(19) ——NIPS2019 PyTorch: An Imperative Style, High-Performance Deep Learning Library
0. 前言
波兰小哥Adam Paszke从15年的Torch开始,到现在发表了关于PyTorch的Neurips2019论文(令我惊讶的是只中了Poster?而不是Spotlight?)。中间经历了漫长的过程。这里,把原文进行翻译放出来,以供读者了解这几个问题:
- 为什么要设计PyTorch?
- PyTorch与之前的深度学习framework的区别是什么?
- PyTorch有什么设计准则?
- 是什么导致了PyTorch在研究者社区的流行?
相信读者在看完下面的译文,就能了解这4点乃至更多的疑问了。

1. Abstract (摘要)
深度学习框架通常在易用性和速度只能2选其1, 很难兼顾. PyTorch是一个兼具易用性和速度的机器学习库: 提供了交互式和pythonic的编程风格,容易debug,并与一些流行的科学计算库保持兼容和风格一致. 同时, 还能保持efficient和支持硬件加速.
本文中,我们详细的介绍了实现PyTorch的原则以及这些原则如何反应在架构设计中. 在PyTorch中, 每个aspect都是一个完全由用户控制的常规Python程序. 我们还解释了runtime的核心组件的设计以及其是如何达成compelling performance的.
我们在一个常见benchmark上验证了PyTorch的独立子系统的efficiency和整体的速度.
2. Introduction(介绍)
随着deep learning在近些年的流行,有很多的机器学习工具出现: 如Caffe, CNTK, Tensorflow, Theano, 这些框架都是创建一个静态数据流图,使得操作可以重复的作用于批数据(batch data). 这种静态图的方式,理论上可以提升性能(performance)和可扩展性(scalability).
然而,这种静态图的框架难以debug,使用成本高(对用户有更高的要求),计算类型的灵活性受到限制.
Chainer, Torch和DyNet等框架意识到了在深度学习框架中, 动态eager执行的价值, 即实现了define-by-run的方法(定义即执行), 但是问题是性能不佳,或者使用的语言不够expressive, 折现值了他们的应用.
然而, 随着小心的工程实现和设计选择, dynamic eager execution的实现可以没有太多的性能损失.
PyTorch, 1个由自动微分赋能, 并支持GPU加速的动态执行Tensor计算Python库. 与现有的最快的DL框架的速度相当的情况下, 在research community中, 得到了广泛的使用. ICLR2019就有296篇提交文章提到了PyTorch.
3. Background(背景)
在科学计算领域, 有4个主流趋势在深度学习中变得越来越重要.
① 基于数组的编程array-based programming
从1960s发展起来的DSL(domain specific languages), 如APL, MATLAB, R, Julia等, 将多维数组转换为由完整数学原语(primitive)(或算子operator)支持的first-class object来操作.
类似Numpy, Torch, Eigen, Lush等的出现, 使得**基于数组的编程(array-based programming)**在Python、Lisp、c++和Lua等通用语言中变得富有成效(productive)。
② 自动微分(automatic differentiation)
自动微分(automatic differentiation) 的发展使得计算derivatives的完全自动化(fully automate)成为可能. 在允许使用高效的基于梯度的优化方案下, 显著降低了实验不同机器学习方法的难度.
autograd这个包推广了这种技术在NumPy数组中的使用,像Chainer, DyNet, Lush, Jax等框架中也使用了类似的方法.
③ 开源生态
随着免费软件的飞速发展, 科学社区慢慢开始从闭源(closed propritary, 以MATLAB为代表)走向开源Python生态(open-source Python ecosystem), 像Numpy, Scipy和Pandas这些包就得到了广泛的使用,因为他们能满足大多数数值分析的需要, 包括并不限于: 数据集处理, 统计分析,绘图等.
此外, 开放, 互操作性(interoperability)和灵活性,使得开源软件的社区非常活跃, 人们在上面可以很快的交流并解决新出现的问题,这也是闭源软件无法比拟的优势(人多力量大).
像Python这样的大型生态系统的网络效应使其成为研究者启动研究的基本技能. 因此, 从2014年起,大多数的DL框架都涵盖了Python接口.
④ hardware accelerators(硬件加速器)
hardware accelerators(硬件加速器), 随着硬件的发展和商用, 如GPU, 提供了deep learning所需的算力. 如cuDNN等特定库, 提供了一系列高性能, 可重用的深度学习kernel. Caffe, Torch7和Tensorflow都使用了这些硬件加速器的特性来加速计算.
PyTorch基于这些趋势, 提供了array-based的编程模型(GPU+auto differentiation赋能), 集成在Python生态环境中.
4. Design principles(设计原则)
PyTorch的成功是源于将前人的想法编织到1个平衡速度和易用性的设计中. 我们的选择背后有四个主要原则:
- ① Be Pythonic
数据科学家对Python语言比较熟悉, 包括其编程模型和工具. 而PyTorch应该是这个生态系统中的一流成员。它遵循通常建立的保持接口简单和一致的设计目标,最理想的是使用一种符合python语言习惯的方式来做事情.
PyTorch与标准的画图,调试以及数据处理模块自然地集成到一起.
- ② Put researchers first
PyTorch试图让模型编写,数据加载和优化变得尽可能的简单和高效. 机器学习内部的复杂性应该在PyTorch内部库中进行处理, 对用户隐藏.
同时, 对外提供的API要没有副作用( free of side-effects)和意想不到的性能骤降(unexpected
performance cliffs).
- ③ Provide pragmatic performance
为了更有用, PyTorch需要呈现令人信服的性能,与此同时不能增加使用的复杂度和门槛. 用10%的性能去换1个简单的多的使用模型的方式是可接受的, 但是用100%的性能去换是不能接收的. 因此, PyTorch的确实为了保证性能而增加了使用的复杂度. 额外的, 我们为研究人员提供了工具, 使得他们可以手动控制其代码的执行过程, 这对他们找到自己代码的性能瓶颈提供了很大的帮助.
- ④ Worse is better
在给定的工程资源的条件下,其它条件相同时, 由于PyTorch内部实现的简洁性而节省下来的时间,对研究者来说,可以被用来实现其它feature, 并跟随AI领域的最新进展.
因此, it is better to have a simple but slightly incomplete solution than a comprehensive but complex and hard to maintain design.
5. Usability centric design(易用性为中心的设计)
- 5.1 Deep learning models are just Python programs
在相当短的时间内, 机器学习就从单独的数字识别发展到了自动打星际争霸战胜职业玩家的程度.
这其中, 神经网络的发展非常非常迅速, 从简单的feed forward layers变成由很多loop和recursive组成的复杂结构.
为了支持这种变态的复杂度(后面还可能更复杂), PyTorch放弃了基于图元编程(graph-metaprogramming)的方法的潜在好处,从而保留了Python的命令式编程模型。
这种方式是由Chainer和Dynet率先使用的,PyTorch将这种方式延伸到深度学习workflow的所有方面: 定义层结构, 组成模型, 加载数据, 跑优化器, 并行训练等.
这种方式使得任何新的神经网络架构都可以很容易的通过PyTorch实现.
List1展示了一个完整的模型是如何通过2d卷积,矩阵乘法,dropout以及softmax来创建的,

此外, 作者还以GAN的训练为例, 说明"everthing is just a program"的哲学.
在最基础的GAN中需要设计2个独立的模型(生成器和判别器),2个损失函数, 对rigid的APIs,这会使得设置变得非常复杂. 而在PyTorch中, 一切都变得简单起来.

由于PyTorch程序是动态执行的, 那么Python的所有特性在PyTorch中都可以使用: 比如 print语句, 标准debugger, 常见的可视化工具如matplotlib等.
用户不需要等待编译后再执行, 他们可以很容易的获取模型的中间输出来判断模型是否正确工作.
- 5.2 Interoperability and extensibility 互操作性和可扩展性
简单且高效的 互操作性(Interoperability) 是PyTorch的最高优先级目标之一, 因为这可以使得PyTorch使用Python语言丰富的生态库.
因此,PyTorch允许与外部库进行双向数据交换(bidrectional exchange of data).
比如说,允许通过torch.from_numpy()和.numpy()2个方法,将numpy array和PyTorch tensors进行互相转换. 类似的功能也可用于交换使用DLPack[29]格式存储的数据。
需要注意: 这些例子中,都不涉及数据拷贝(without any data copying)
即: 对象只描述如何解析内存区域(通过stride), 数据本身对应的内存不变化,或者说不频繁的变化.
所以, 这些操作的代价非常小, 无论数组的大小, 所需的时间都是常数.
此外, PyTorch内部的许多关键部分都是为了**可扩展性(extensible)**而特殊设计.
举例, 自动微分系统使得用户可以增加自己的自定义的可微分函数(custom differentiable function).
通过继承torch.autograd.Function类, 实现forward和backward成员函数即可.
这些内容的实际工作,完全取决于定义这些方法的人本身, 比如, 很多人, 使用python内置的包来进行data loading的操作.
DataLoader类使用符合这个接口的对象,并在数据上提供一个迭代器(iterator),负责对 固定的CUDA内存(pinned CUDA memory) 进行变换、批处理、并行化和管理,以提高吞吐量(improve throughput)。
此外, 用户可以随意的替换PyTorch中任何不满足其需要或性能要求的组件. 他们都被设计为完全可替换的(completely interchangeable),
而且, PyTorch非常小心,不强加任何特定的解决方案。
- 5.3 Automatic differentiation 自动微分
由于基于梯度的优化对深度学习非常重要,PyTorch必须可以自动的计算被用户定义的模型的梯度, 而这些模型可能是任意的Python程序.
然而, Python是一门动态语言, 即Python允许在runtime(运行时)修改信息和行为. 这使得ahead of time的source2source的微分变得非常麻烦.
PyTorch用 运算符重载(operator overloading approach) 的方法,其在每次执行computed function时, 都构建对该function的representation.
在PyTorch现在的实现中, 实现了reverse-mode的automatic differentiation. 其计算一个标量输出关于多变量输出(multivariate)的梯度.
同样地, PyTorch也可以很容易的扩展到forward-mode的automatic differentiation(通过使用array-level dual number): 数组级对偶数.
另一个在PyTorch中有趣且不常见的特征是: 可以对发生变化的Tensor进行微分(inplace操作).
为了保证安全, PyTorch为Tensor实现了1个版本控制系统(versioning system), 这个系统可以使得我们追踪Tensor的修改历程并保证我们总是在使用我们所期待的数据.
1个有意思的tradeoff是当我们可以使用像copy-on-write这种技术,我们并没有选择这条路(not go down this path),
就性能而言(performance-wise), 用户重写代码以确保不执行任何副本通常是有益的. 自此, 当大多数的mutation是良性且可以自动处理时, 真正复杂的情况会导致一个用户错误,这让他们知道他们可能想要重构程序.
这使得我们有效的避免引入subtle且难以寻找的performance cliffs.
6. Performance focused implementation(聚焦性能的实现)
基于Python解释器来跑深度学习算法是臭名昭著的有挑战性的事情: 比如, GIL的存在,使得在给定的时间(at any given time)内,任意数量的并发线程中只有一个正在运行。
基于静态图的解决方案通过将计算求解 deferring to 自定义的解释器来回避这个问题.(sidestep this problem)
PyTorch用不同的方式来解决这个问题, 通过对执行过程的每个aspect进行小心的优化, 同时让用户可以容易的使用额外的优化策略.
- 6.1 高效的C++内核
尽管与Python生态集成的非常好, 但是, PyTorch的大部分代码都是用C++来完成的(为了达到更好的性能).
libtorch: 实现了tensor的数据结构, GPU or CPU的运算符(operator), 以及基本的并行原语(parallel primitives). 此外, 它还提出了自动微分系统, 包括大多数内置函数的梯度公式(gradient formulas for most built-in functions).
这确保了由核心PyTorch操作符组成的函数的导数的计算完全在多线程求值程序中执行( executed entirely in a multithreaded
evaluator ), 这不需要持有Python的GIL锁.
此外, 我们通过使用YAML源meta-data文件来binding C++和python (PYBIND11_MODULE, https://blog.csdn.net/g11d111/article/details/104407384).
这种方法的一个有趣的副作用是,它允许我们的社区快速创建到多种其他语言的绑定,从而产生诸如NimTorch、hasktorch等项目。
随着PyTorch 1.0的发布, 我们可以使用通过Python来定义的模型, 用TorchScript引擎来运行这个模型(完全抛开Python).
- 6.2 Separate control and data flow 独立的控制和数据流
PyTorch在其控制(即程序分支、循环)和数据流(即张量和对其执行的操作)之间保持严格的分离。其中, control flow由Python解析, 并在CPU上执行优化后的C++代码, 并在设备上产生一个操作符调用的线性序列(linear sequence of operator invocations). 这些运算符既可以在CPU上执行,也可以在GPU上执行.
PyTorch通过利用CUDA stream机制来异步执行运算符: 将CUDA内核调用(kernel invocations)排进GPU硬件的FIFO队列中. 这使得系统可以同时在CPU上执行Python代码和在GPU上执行Tensor运算.
由于Tensor运算通常会消耗大量的时间, 这使得我们可以在一个有相当大overhead(开销)的解释型语言(Python)中达到/挖掘出GPU的巅峰性能. 需要注意的是, 这个机制对用户几乎是不可见的. 除非他们需要实现自己的multi-stream原语, 否则所有的CPU-GPU同步都由PyTorch库来处理。
PyTorch可以利用类似的机制在CPU上进行异步执行Tensor运算. 然而, 跨线程通信和同步会抵消(negate)这种性能增益.
- 6.3 Custom caching tensor allocator 自定义的缓存分配器
几乎所有的运算符都必须在执行过程中动态分配output tensor以保存结果. 因此, 对dynamic memory allocator(动态内存分配)的调优就变得极度重要. PyTorch可以靠[1-3]这种优化库解决在CPU上的这种动态内存分配的问题. 但是, GPU上的如cudaFree的惯例模式可能会阻塞直到所有的之前的GPU队列里的工作完成.
为了避免性能瓶颈, PyTorch实现了custom allocator: 增量的构建了CUDA memory的缓存(cache), 并将cache重分配给后面的allocation, 而绕开了CUDA原生的API. 这种增量的分配对互操作性(interoperability)同样非常重要, 因为提前占用所有GPU内存会阻止用户使用其他支持GPU的Python包。
为了进一步的提升其有效性, 我们的custom allocator针对深度学习使用的特定内存模式进行了调优(tuned). 比如:
-
将每个分配(allocation)都rounds up为512字节的倍数, 以避免碎片问题(avoid fragmentation issues) .
-
对每一个CUDA stream都维护一个独立的内存池.
这种设计叫做one-pool-per-stream. one-pool-per-stream设计似乎是有限制的,因为分配结果是每个流碎片化,但实际上PyTorch几乎从不使用多个流。众所周知,以一种让CUDA内核协同共享GPU的方式来编写CUDA内核是非常困难的,因为精确的调度是由硬件控制的。在实践中,CUDA kernel编写人员通常求助于结合多个任务的单片内核.
Data loading和distributed computing utilities是单一流设计的例外,它们小心地插入额外的同步以避免与分配器(allocator)的不良交互.
随着one-pool-per-stream这种设计容易受到某些特殊情况的影响, 但是在实际代码中,它几乎从不显示不需要的行为。我们的大多数用户并不知道它的存在。
- 6.4 Multiprocessing 多进程
由于GIL锁的存在, Python默认的实现是不能多线程并行执行的. 为了缓解这个问题, Python社区提出了标准的multiprocessing模块, 这个模块包含了一系列的utilities来使得用户容易的从父进程派发出子进程并进行进程间通信.
然而, 这种实现使用与 磁盘上持久性(on-disk persistence) 相同的序列化形式, 对处理大数组来说效率很低. 因此, 我们将multiprocessing扩展到torch中,
这个扩展是将tensor数据通过shared memory传给其它进程,而非通过communication channel进行传递.
这个设计极大的提高了性能并使得进程隔离性变弱, 即使得多进程的编程模型更像常规的多线程模型一样.
用户可以很容易地在独立的gpu上实现大量的并行程序,但是稍后会使用all-reduce的原语来同步梯度。
这个系统的另一个独特的特性是它透明地处理CUDA张量的共享,使得像Hogwild这样的技术易于实现
- 6.5 Reference counting 引用计数
用户通常的设计是跑满显存, 提升batch size以加速训练. 因此, 为了达到更高的性能, PyTorch需要将内存视为scarce resource来进行小心管理.
GC有好的 摊消性能(amortized performance), 因此可以用来管理tensor memory.
runtime 周期性的分析系统的状态, 枚举所有的used objects并释放其它对象. 但是,由于延迟释放, 会导致程序总体上使用更多的内存. 由于GPU内存的有限性, 这些overheads是不可接受的.
Torch7使用Lua的GC,而PyTorch使用引用计数机制来计算每个tensor的计数, 一旦一个tensor的计数为零,就立即释放底层内存.
需要说明的是, PyTorch既track libtorch库的内部引用, 也track用户Python code中的外部引用(通过Python自己的引用计数机制) . 这使得当tensor不再被用到的时候即被释放掉, 很高效.
我们只能保证在Cpython和Swift这种用引用计数的语言上能够达到desired performance. 而在pypy和lua上不行.
7. Evaluation 评估
本节, 我们将PyTorch与其它常用的深度学习库进行比较. 可以达到PyTorch能够达到competitve的性能.
所用设备是2个Intel Xeon E5-2698 v4 和1个Quadro GP100 GPU。
Note:这里我只列出Benchmark和Adoption,关于显存管理和异步数据流,请参看原文。
-
7.1 Asynchronous dataflow (略)
-
7.2 Memory management (略)
-
7.3 Benchmarks
这里, 与3个流行的graph-based的深度学习框架(CNTK, MXNet and TensorFlow),1个define-by-run的框架(Chainer)以及生产优先平台(PaddlePaddle)进行比较,
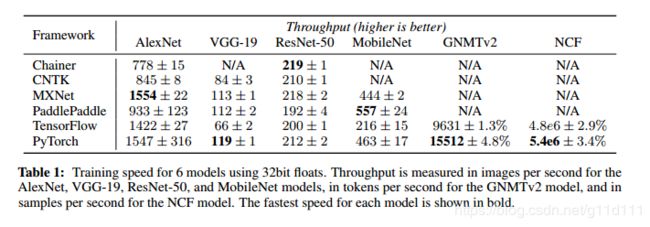
由上表可以看出,PyTorch的性能是最快的框架的17%以内。我们将这个结果归因于这样一个事实: 即这些工具将大部分计算工作转移到同一个版本的cuDNN和cuBLAS库中。
- 7.4 Adoption
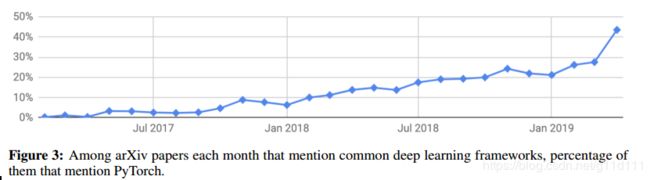
为了分析PyTorch的易用性和影响,我们分析了自2017年1月份最初发布的PyTorch在arXiv e-Prints上面的被提到的次数。
下图可以看出,PyTorch在全部的深度学习工具和框架中的提到比率逐步上涨,已经逼近50%大关。注意:一篇文章我们只记1次。
8. Conclusion and future work 结论
PyTorch由于兼顾了易用性和高效计算性的特点, 在深度学习研究社区里非常流行. 在未来, 我们想要继续提高PyTorch的速度和可扩展性(可伸缩性).
最明显的是, 我们开始聚焦PyTorch JIT: 使得PyTorch程序可以在Python解释器外执行, 以获得更好的效率和优化.
同样, 我们还打算通过提供高效的数据并行原语和基于远程过程调用(RPC)的模型并行化python库来改进对分布式计算的支持。
参考资料
[1] Emery D. Berger, Kathryn S.
A scalable memory allocator for multithreaded applications.
[2] S. Ghemawat and P. Menage. Tcmalloc: Thread-caching malloc.
[3] J. Evans. A scalable concurrent malloc(3) implementation for freebsd.