哪些数据可以放进缓存?记录生产环境一次缓存评估的过程

作者 l 会点代码的大叔(CodeDaShu)
当项目中引入了 Redis 做分布式缓存,那么就会面临这样的问题:
哪些数据应该放到缓存中?依据是什么?
缓存数据是采用主动刷新还是过期自动失效?
如果采用过期自动失效,那么失效时间如何制定?
正好这两周我们项目做了相关的评估,把过程记录下来和大家分享分享;当然过程中用到了很多“笨办法”,如果你有更好的办法,也希望能分享给我。
01
项目背景
我们的项目是一个纯服务平台,也就是只提供接口服务,并没有操作页面的,项目的接口日调用量大约在 200 万次,高峰期也就 1000 万出头,因为大部分接口是面向内部系统的,所以大部分请求集中在工作日的 9 点到 21 点,高峰期的时候系统的 QPS 在 300-400 之间。
因为我们项目数据存储使用的是 MongoDB,理论上支撑这个量级的 QPS 应该是绰绰有余,但是我有这么几点观察和考虑:
MongoDB 中虽然是整合好的数据,但是很多场景也不是单条查询,夸张的时候一个接口可能会返回上百条数据,回参报文就有两万多行(不要问我能不能分页返回......明确告诉你不能);
MongoDB 中虽然是整合好的数据,但是很多场景也不是单条查询,夸张的时候一个接口可能会返回上百条数据,回参报文就有两万多行(不要问我能不能分页返回......明确告诉你不能);
目前项目 99.95% 的接口响应时间都在几十到几百毫秒,基本可以满足业务的需要,但是还是有 0.05% 的请求会超过 1s 响应,偶尔甚至会达到 5s、10s;
观察这些响应时间长的请求,大部分时间消耗在查询 MongoDB 上,但是当我将请求报文取出,再次手动调用接口的时候,依然是毫秒级返回;MongoDB 的配置一般,时刻都有数据更新,而且我观察过,响应时间长的这些接口,那个时间点请求量特别大;
MongoDB 查询偶尔会慢的原因我我还在确认,我现在能想到的原因比如:大量写操作影响读操作、锁表、内存小于索引大小等等,暂时就认为是当时那一刻 MongoDB 有压力;我观察过,响应时间长的这些接口,那个时间点请求量特别大,这一点就不在这里具体分析了。
虽然一万次的请求只有四五次响应时间异常,但是随着项目接入的请求越来越大,保不齐以后量变产生质变,所以还是尽量将危机扼杀在摇篮里,所以果断上了 Redis 做分布式缓存。
02
接口梳理
下一步就是对生产环境现有接口进行统计和梳理,确定哪些接口是可以放到缓存中的,所以首先要对每一个接口的调用量有大概的统计,因为没有接入日志平台,所以我采用了最笨的办法,一个一个接口的数嘛。
把工作日某一天全天的日志拉下来,我们四台应用服务器,每天的日志大概 1 个G,还好还好;
通过 EditPlus 这个工具的【在文件中查找】的功能,查询每个接口当天的调用量,已上线 30 个接口,有几分钟就统计出来了,反正是一次性的工作,索性就手动统计了;
一天也调不了几次的接口,就直接忽略掉了,我基本上只把日调用量上万的接口都留下来,进行下一步的分析。
03
字典表、配置类的数据
这一类的数据是最适合放在缓存中的,因为更新频率特别低,甚至有时候 insert 了之后就再也不做 update ,如果这类数据的调用量比较大,是一定要放到 Redis 中的;
至于缓存策略,可以在更新的时候双写数据库和 Redis,也可以采用自动失效的方式,当然这个失效时间可以放得比较长一些;针对我们项目,我采用的是半夜 12 点统一失效的策略,第一因为我们系统这类数据,是夜间通过 ETL 抽取过来的,每天同步一次,第二就是我们不怕缓存雪崩,没有那么大的访问量,夜间更没有什么访问量了。
04
明显是热点数据的数据
有一类数据,很明显就是热点数据;
我们就有一个接口,虽然是业务数据,不过数据总量只有几千条,但是每天的调用量大约在 40 万,而且更新频率不是很高,这类数据放入 Redis 中也就再适合不过了;至于缓存策略么,因为数据也是从其他系统同步过来的,根据数据同步的时间,我们最终采用一个小时的失效时间。
05
其余数据的评估
其实前两种数据很容易就能评估出来,关键是这类数据的评估:
我们有一个接口日调用量 20-30 万,量不大,但是查询和处理逻辑比较复杂;
基础数据量太大,无法把所有数据都放入 Redis 中;
无法把基础数据直接放入 Redis 中,因为有多重查询维度(条件);
无法确定每条数据的调用频率是怎么样的,最悲观的结果,每条数据当天只调用一次,这样就没有缓存的必要了。
但是咱也不能一拍脑袋就说:“调用量挺大的,直接放到 Redis 中吧”,或者“不好评估,算了吧,别放缓存了”,做任何一个决定还是需要有依据的,于是我是这样做的:
Step 1.
把该接口当天的所有日志都找出来
几十个日志文件肯定不能一个一个翻,要么就自己写个程序把需要的数据扒出来,但是考虑到这个工作可能只做一次,我还是尽量节省一些时间吧。
依然使用 EditPlus 这个工具的【在文件中查找】的功能,在查询结果框中【复制所有内容】,花了两分钟,就把 24 万条日志找出来了。
 o 该接口查询到 24 万条数据
o 该接口查询到 24 万条数据
Step 2.
把数据导入到数据库中进行下一步分析
每一条日志大概是这样的:
XXXX.log"(64190,95):2020-3-17 16:44:10.092 http-nio-8080-exec-5 INFO 包名.类名 : 请求参数:args1={"字段1":"XXX","字段2":"YYY"}
日志里面我只需要三个内容:请求报文中的字段 1 和字段 2,以及调用时间;怎么摘出来?写个程序?当然没问题,但是我懒呀,几分钟能做好的事情为什么话花几十分钟呢?而且这工作是一次性的,于是:
全文替换:[ 2020-3-17 ] 替换成 [ /t2020-3-17 ] ,也就是在时间戳前面加一个 tab;
全文替换:[ {"字段1":" ] 替换成 [ /t ] ;
全文替换:[ ","字段2":" ] 替换成 [ /t ] ;
全文替换:[ "} ] 替换成 [ ],也就是替换成空 ;
全选复制,粘贴到 excel 中,excel 自动按照 tab 换列;
删除不需要的列,只留字段 1 和字段 2 的内容,以及时间戳;
这几步操作用不了一分钟。
 o 从日志拆出来的三个字段
o 从日志拆出来的三个字段
Step 3.
调用频率分析
当把数据进入到数据库中,就根据我们的需要进行分析了;我们主要想知道,相同的入参会不会重复调用?每次调用间隔的时间是多少?一个 SQL 搞定:
select 字段1 , 字段2, count(1) 调用次数, (MIDNIGHT_SECONDS(max(UPDATETIME)) - MIDNIGHT_SECONDS(min(UPDATETIME)))/60 调用间隔时间,处理成了分钟
from TABLE
group by 字段1 , 字段2
having count(1) > 2
with ur ;
当然调用间隔时间的统计,这里统计的不精确,具体我不解释了,你们细品...
总之吧,全天 24 万的调用量,其中 10 万只调用了一次,14 万的数据会在短时间内重复调用,有一些数据甚至会在几分钟之内重复查询几十次,所以这个接口还是比较适合放入到 Redis 中的。
Step 4.
数据怎么存?
再说说我们的数据用什么格式保存到 Redis 中,一图胜千言:
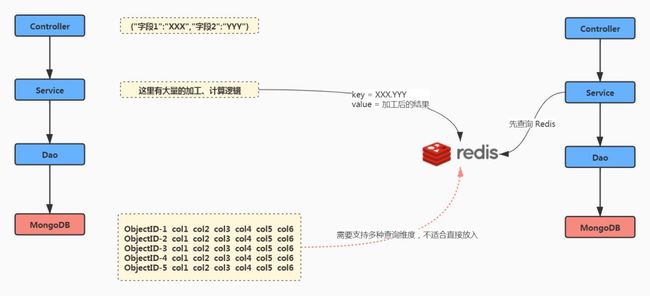 o 将加工结果保存到 Redis 中
o 将加工结果保存到 Redis 中
至于缓存更新策略嘛,我们依然使用设置失效时间的方式,根据数据同步的时间和调用统计结果,这个时间设置成 15 分钟比较合适。
可以看到在这个评估过程中,我所有操作都保持了“能偷懒就偷懒”这个好习惯,保持高效,善用工具,节约不必要的时间,全部过程花了两个小时,其中大部分时间是在数据导入,几乎用了一个半小时,还好在这个过程中我还能做其他的工作。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:

长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢