前言
数据科学部为想从事大数据方向学习的小伙伴总结了一下大数据的学习路线,供大家学习参考。由于大数据是一个基础门槛较高就业前景较好的学习方向。所以打算学习大数据的小伙伴要加油啦!
大数据学习路线:
首先我要了解大数据处理流程:
第一步:数据收集
第二部:数据存储
第三步:数据分析
第四步:数据应用
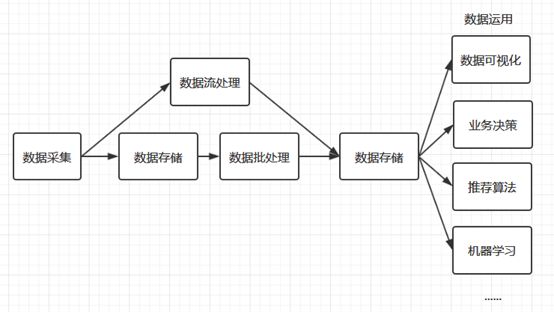
数据收集
大数据处理的第一步是数据的收集。现在的中大型项目通常采用微服务架构进行分布式部署,所以数据的采集需要在多台服务器上进行,且采集过程不能影响正常业务的开展。基于这种需求,就衍生了多种日志收集工具,如 Flume 、Logstash等,它们都能通过简单的配置完成复杂的数据收集和数据聚合。
数据存储
收集到数据后,下一个问题就是:数据该如何进行存储?我们通常熟知的就是把数据存入MySQL、Oracle等传统的关系型数据库,这些传统的数据库的特点是能够快速存储结构化的数据,并支持随机访问。但大数据的数据结构通常是半结构化(如日志数据)、甚至是非结构化的(如视频、音频数据),为了解决海量半结构化和非结构化数据的存储,衍生了 Hadoop HDFS 、KFS、GFS 等分布式文件系统,它们都能够支持结构化、半结构和非结构化数据的存储,并可以通过增加机器进行横向扩展。
分布式文件系统完美地解决了海量数据存储的问题,但是一个优秀的数据存储系统需要同时考虑数据存储和访问两方面的问题,比如你希望能够对数据进行随机访问,这是传统的关系型数据库所擅长的,但却不是分布式文件系统所擅长的,那么有没有一种存储方案能够同时兼具分布式文件系统和关系型数据库的优点,基于这种需求,就产生了 HBase、MongoDB。
数据分析
大数据处理最重要的环节就是数据分析,数据分析通常分为两种:批处理和流处理。
批处理:对一段时间内海量的离线数据进行统一的处理,对应的处理框架有 Hadoop MapReduce、Spark、Flink 等;
流处理:对运动中的数据进行处理,即在接收数据的同时就对其进行处理,对应的处理框架有 Storm、Spark Streaming、Flink Streaming 等。
批处理和流处理各有其适用的场景,时间不敏感或者硬件资源有限,可以采用批处理;时间敏感和及时性要求高就可以采用流处理。随着服务器硬件的价格越来越低和大家对及时性的要求越来越高,流处理越来越普遍,如股票价格预测和电商运营数据分析等。
数据应用
数据分析完成后,接下来就是数据应用的范畴,这取决于你实际的业务需求。比如你可以将数据进行可视化展现,或者将数据用于优化你的推荐算法,这种运用现在很普遍,比如短视频个性化推荐、电商商品推荐、头条新闻推荐等。当然你也可以将数据用于训练你的机器学习模型,这些都属于其他领域的范畴,都有着对应的框架和技术栈进行处理,这里就不一一赘述。
学习路线
学习大数据门槛相对较高,首先要有一定的语言基础
1.java
大数据框架大多采用 Java 语言进行开发,并且几乎全部的框架都会提供 Java API 。Java 是目前比较主流的后台开发语言,所以网上免费的学习资源也比较多。
2.scala
Scala 是一门综合了面向对象和函数式编程概念的静态类型的编程语言,它运行在 Java 虚拟机上,可以与所有的 Java 类库无缝协作,著名的 Kafka 就是采用 Scala 语言进行开发的。
为什么需要学习 Scala 语言 ? 这是因为当前最火的计算框架 Flink 和 Spark 都提供了 Scala 语言的接口,使用它进行开发,比使用 Java 8 所需要的代码更少,且 Spark 就是使用 Scala 语言进行编写的,学习 Scala 可以帮助你更深入的理解 Spark。
Linux基础
通常大数据框架都部署在 Linux 服务器上,所以需要具备一定的 Linux 知识。
构建工具
这里需要掌握的自动化构建工具主要是 Maven。Maven 在大数据场景中使用比较普遍,主要在以下三个方面:
1.管理项目 JAR 包,帮助你快速构建大数据应用程序;
2.不论你的项目是使用 Java 语言还是 Scala 语言进行开发,提交到集群环境运行时,都需要使用 Maven 进行编译打包;
3.大部分大数据框架使用 Maven 进行源码管理,当你需要从其源码编译出安装包时,就需要使用到 Maven。
框架学习
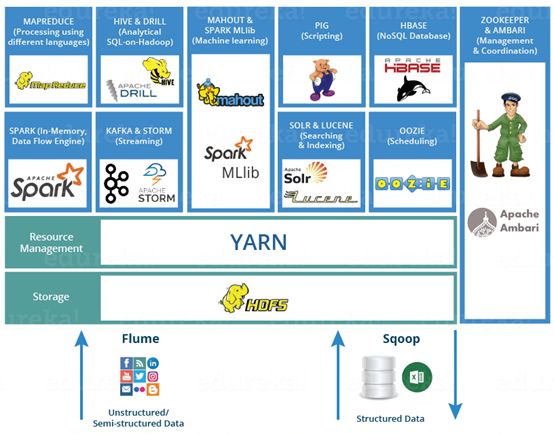
我们对框架进行简单的分类总结:
日志收集框架:Flume 、Logstash、Kibana
分布式文件存储系统:Hadoop HDFS
数据库系统:Mongodb、HBase
分布式计算框架:
-
批处理框架:Hadoop MapReduce
-
流处理框架:Storm
-
混合处理框架:Spark、Flink
查询分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
集群资源管理器:Hadoop YARN
分布式协调服务:Zookeeper
数据迁移工具:Sqoop
任务调度框架:Azkaban、Oozie
集群部署和监控:Ambari、Cloudera Manager
上面列出的都是比较主流的大数据框架,社区都很活跃,学习资源也比较丰富。建议从 Hadoop 开始入门学习,因为它是整个大数据生态圈的基石,其它框架都直接或者间接依赖于 Hadoop 。接着就可以学习计算框架,Spark 和 Flink 都是比较主流的混合处理框架,Spark 出现得较早,所以其应用也比较广泛。 Flink 是当下最火热的新一代的混合处理框架,其凭借众多优异的特性得到了众多公司的青睐。两者可以按照你个人喜好或者实际工作需要进行学习。
开发工具
这里推荐一些大数据常用的开发工具:
Java IDE:IDEA 和 Eclipse 都可以。从个人使用习惯而言,更倾向于 IDEA ;
VMware Workstation:在学习过程中,你可能经常要在虚拟机上搭建服务和集群。
MobaXterm:大数据的框架通常都部署在服务器上,这里推荐使用 MobaXterm 进行连接。同样是免费开源的,支持多种连接协议,支持拖拽上传文件,支持使用插件扩展;
Translate Man:一款浏览器上免费的翻译插件 (谷歌和火狐均支持)。它采用谷歌的翻译接口,准确性非常高,支持划词翻译,可以辅助进行官方文档的阅读。