深入理解计算机系统-之-数值存储(一)-CPU大端和小端模式详解
大端与小端
在嵌入式开发中,大端(Big-endian)和小端(Little-endian)是一个很重要的概念。
MSB与LSB
最高有效位(MSB)指二进制中最高值的比特。在16比特的数字音频中,其第1个比特便对16bit的字的数值有最大的影响。例如,在十进制的15,389这一数字中,相当于万数那1行(1)的数字便对数值的影响最大。比较与之相反的“最低有效位”(LSB)。
LSB(Least Significant Bit),意为最低有效位;MSB(Most Significant Bit),意为最高有效位
若MSB=1,则表示数据为负值,若MSB=0,则表示数据为正。
MSB高位前导,LSB低位前导。
谈到字节序的问题,必然牵涉到两大CPU派系。那就是Motorola的PowerPC系列CPU和Intel的x86系列CPU。PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。那么究竟什么是big endian,什么又是little endian呢?
其实big endian是指低地址存放最高有效字节(MSB)
而little endian则是低地址存放最低有效字节(LSB)。
MSDN中关于LE和BE的解释
Byte Ordering Byte ordering Meaning
big-endian The most significant byte is on the left end of a word.
little-endian The most significant byte is on the right end of a word.
这里这个最重要的字节可以解释成值的最高位,如果换成是钱的话就是最值钱的那一位
Big endian machine: It thinks the first byte it reads is the biggest.
Little endian machine: It thinks the first byte it reads is the littlest.
比如我有1234元人民币,最值钱的是1000元,最不值钱的是4元,那么这个1就是最重要的字节
下面我们详细讲下大小端模式的问题
端模式(Endian)
端模式(Endian)的这个词出自Jonathan Swift书写的《格列佛游记》。这本书根据将鸡蛋敲开的方法不同将所有的人分为两类,从圆头开始将鸡蛋敲开的人被归为Big Endian,从尖头开始将鸡蛋敲开的人被归为Littile Endian。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。在计算机业Big Endian和Little Endian也几乎引起一场战争。在计算机业界,Endian表示数据在存储器中的存放顺序。
大端
大端(Big-endian)模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中
这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这种存放方式符合人类的正常思维
小端
小端(Little-endian)模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
总结
采用大小模式对数据进行存放的主要区别在于在存放的字节顺序,大端方式将高位存放在低地址,小端方式将高位存放在高地址。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。到目前为止,采用大端或者小端进行数据存放,其孰优孰劣也没有定论。
有的处理器系统采用了小端方式进行数据存放,如intel芯片是小端(修改分区表时要注意)。
有的处理器系统采用了大端方式进行数据存放,如IBM半导体和Freescale的PowerPC处理器以及一些常见的单片机芯片。不仅对于处理器,一些外设的设计中也存在着使用大端或者小端进行数据存放的选择。
特别的intel x86的CPU使用的是LE(Windows中称为“主机字节序”),而SocksAddr中使用的则是BE(就是“网络字节序”),所以在使用网络编程时需要使用htns,htnl,nths,nthl来倒字节序。
因此在一个处理器系统中,有可能存在大端和小端模式同时存在的现象。这一现象为系统的软硬件设计带来了不小的麻烦,这要求系统设计工程师,必须深入理解大端和小端模式的差别。大端与小端模式的差别体现在一个处理器的寄存器,指令集,系统总线等各个层次中。
示例分析
假如现有一32位int型数0x12345678,
那么
其MSB(Most Significant Byte,最高有效字节)为0x12,
其LSB (Least Significant Byte,最低有效字节)为0x78
| 地址偏移 | 大端模式 | 小端模式 |
|---|---|---|
| 0x00 | 12(OP0) | 78(OP3) |
| 0x01 | 34(OP1) | 56(OP2) |
| 0x02 | 56(OP2) | 34(OP1) |
| 0x03 | 78(OP3) | 12(OP0) |
也可以看下面这个图
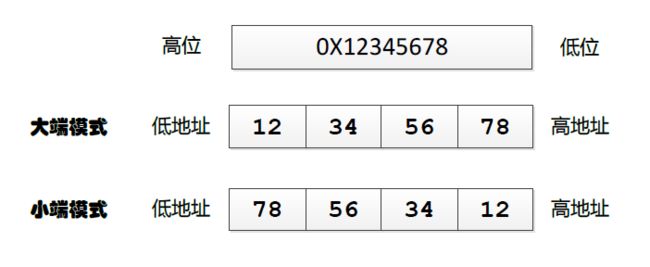
我们可以看到看到
大端(Big-endian)模式下数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,特别的MSB最高有效字节为0x12存放在低字节
小端(Little-endian)模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,,特别的LSB最高有效字节为0x78存放在低字节
填写数据时我们可以发现
BE big-endian 大端模式
最直观的字节序
地址低位存储值的高位
地址高位存储值的低位
为什么说直观,不要考虑对应关系
只需要把内存地址从左到右按照由低到高的顺序写出
把值按照通常的高位到低位的顺序写出
两者对照,一个字节一个字节的填充进去LE little-endian 小端模式
最符合人的思维的字节序
地址低位存储值的低位
地址高位存储值的高位
怎么讲是最符合人的思维的字节序,是因为从人的第一观感来说
低位值小,就应该放在内存地址小的地方,也即内存地址低位
反之,高位值就应该放在内存地址大的地方,也即内存地址高位
程序分析

如何编写程序测试看CPU使用的是大端模式还是小端模式
下面这段代码可以用来测试一下你的编译器是大端模式还是小端模式:
#include我们把他封装成函数的形式
//返回值:大端返回1,小段返回0
int check_end()
{
int i = 0x12345678;
char *c = (char *)&i;
return (*c == 0x12);
}也可以
//返回值:大端返回1,小段返回0
int CheckEnd()
{
union
{
int a;
char b;
}u;
u.a = 1;
if (u.b == 1)
return 0;
else
return 1;
}参考
深入浅出大端和小端