alloc_page分配内存空间--Linux内存管理(十七)
| 日期 | 内核版本 | 架构 | 作者 | GitHub | CSDN |
|---|---|---|---|---|---|
| 2016-09-29 | Linux-4.7 | X86 & arm | gatieme | LinuxDeviceDrivers | Linux内存管理 |
1 前景回顾
在内核初始化完成之后, 内存管理的责任就由伙伴系统来承担. 伙伴系统基于一种相对简单然而令人吃惊的强大算法.
Linux内核使用二进制伙伴算法来管理和分配物理内存页面, 该算法由Knowlton设计, 后来Knuth又进行了更深刻的描述.
伙伴系统是一个结合了2的方幂个分配器和空闲缓冲区合并计技术的内存分配方案, 其基本思想很简单. 内存被分成含有很多页面的大块, 每一块都是2个页面大小的方幂. 如果找不到想要的块, 一个大块会被分成两部分, 这两部分彼此就成为伙伴. 其中一半被用来分配, 而另一半则空闲. 这些块在以后分配的过程中会继续被二分直至产生一个所需大小的块. 当一个块被最终释放时, 其伙伴将被检测出来, 如果伙伴也空闲则合并两者.
内核如何记住哪些内存块是空闲的
分配空闲页面的方法
影响分配器行为的众多标识位
内存碎片的问题和分配器如何处理碎片
2 内存分配API
2.1 内存分配器API
就伙伴系统的接口而言, NUMA或UMA体系结构是没有差别的, 二者的调用语法都是相同的.
所有函数的一个共同点是 : 只能分配2的整数幂个页.
因此,接口中不像C标准库的malloc函数或bootmem和memblock分配器那样指定了所需内存大小作为参数. 相反, 必须指定的是分配阶, 伙伴系统将在内存中分配 2order 页. 内核中细粒度的分配只能借助于slab分配器(或者slub、slob分配器), 后者基于伙伴系统
| 内存分配函数 | 功能 | 定义 |
|---|---|---|
| alloc_pages(mask, order) | 分配 2order 页并返回一个struct page的实例,表示分配的内存块的起始页 | NUMA-include/linux/gfp.h, line 466 UMA-include/linux/gfp.h?v=4.7, line 476 |
| alloc_page(mask) | 是前者在order = 0情况下的简化形式,只分配一页 | include/linux/gfp.h?v=4.7, line 483 |
| get_zeroed_page(mask) | 分配一页并返回一个page实例,页对应的内存填充0(所有其他函数,分配之后页的内容是未定义的) | mm/page_alloc.c?v=4.7, line 3900 |
| __get_free_pages(mask, order) __get_free_page(mask) |
工作方式与上述函数相同,但返回分配内存块的虚拟地址,而不是page实例 | |
| get_dma_pages(gfp_mask, order) | 用来获得适用于DMA的页. | include/linux/gfp.h?v=4.7, line 503 |
在空闲内存无法满足请求以至于分配失败的情况下,所有上述函数都返回空指针(比如alloc_pages和alloc_page)或者0(比如get_zeroed_page、__get_free_pages和__get_free_page).
因此内核在各次分配之后都必须检查返回的结果. 这种惯例与设计得很好的用户层应用程序没什么不同, 但在内核中忽略检查会导致严重得多的故障
内核除了伙伴系统函数之外, 还提供了其他内存管理函数. 它们以伙伴系统为基础, 但并不属于伙伴分配器自身. 这些函数包括vmalloc和vmalloc_32, 使用页表将不连续的内存映射到内核地址空间中, 使之看上去是连续的.
还有一组kmalloc类型的函数, 用于分配小于一整页的内存区. 其实现将在以后分别讨论。
2.2 内存分配API统一到alloc_pages接口
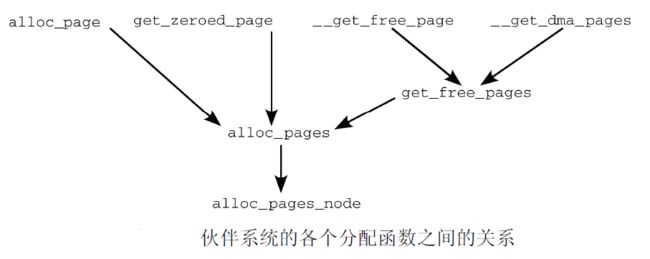
通过使用标志、内存域修饰符和各个分配函数,内核提供了一种非常灵活的内存分配体系.尽管如此, 所有接口函数都可以追溯到一个简单的基本函数(alloc_pages_node)
分配单页的函数alloc_page和__get_free_page, 还有__get_dma_pages是借助于宏定义的.
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L483
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L500
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask), 0)`
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L503
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA, (order))get_zeroed_page的实现也没什么困难, 对__get_free_pages使用__GFP_ZERO标志,即可分配填充字节0的页. 再返回与页关联的内存区地址即可.
// http://lxr.free-electrons.com/source/mm/page_alloc.c?v=4.7#L3900
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
EXPORT_SYMBOL(get_zeroed_page);__get_free_pages调用alloc_pages完成内存分配, 而alloc_pages又借助于alloc_pages_node
__get_free_pages函数的定义在mm/page_alloc.c?v=4.7, line 3883
// http://lxr.free-electrons.com/source/mm/page_alloc.c?v=4.7#L3883
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
/*
* __get_free_pages() returns a 32-bit address, which cannot represent
* a highmem page
*/
VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0);
page = alloc_pages(gfp_mask, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);在这种情况下, 使用了一个普通函数而不是宏, 因为alloc_pages返回的page实例需要使用辅助
函数page_address转换为内存地址. 在这里,只要知道该函数可根据page实例计算相关页的线性内存地址即可. 对高端内存页这是有问题的
这样, 就完成了所有分配内存的API函数到公共的基础函数alloc_pages的统一
另外所有体系结构都必须实现的标准函数clear_page, 可帮助alloc_pages对页填充字节0, 实现如下表所示
| x86 | arm |
|---|---|
| arch/x86/include/asm/page_32.h?v=4.7, line 24 | arch/arm/include/asm/page.h?v=4.7#L14 arch/arm/include/asm/page-nommu.h |
2.2 alloc_pages函数分配页
既然所有的内存分配API函数都可以追溯掉alloc_page函数, 从某种意义上说,该函数是伙伴系统主要实现的”发射台”.
alloc_pages函数的定义是依赖于NUMA或者UMA架构的, 定义如下
#ifdef CONFIG_NUMA
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L465
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
#else
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L476
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#endifUMA结构下的alloc_pages是通过alloc_pages_node函数实现的, 下面我们看看alloc_pages_node函数的定义, 在include/linux/gfp.h?v=4.7, line 448
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L448
/*
* Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE,
* prefer the current CPU's closest node. Otherwise node must be valid and
* online.
*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}它只是执行了一个简单的检查, 如果指定负的结点ID(不存在, 即NUMA_NO_NODE = -1), 内核自动地使用当前执行CPU对应的结点nid = numa_mem_id();, 然后调用__alloc_pages_node函数进行了内存分配
__alloc_pages_node函数定义在include/linux/gfp.h?v=4.7, line 435), 如下所示
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L435
/*
* Allocate pages, preferring the node given as nid. The node must be valid and
* online. For more general interface, see alloc_pages_node().
*/
static inline struct page *
__alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES);
VM_WARN_ON(!node_online(nid));
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}内核假定传递给改alloc_pages_node函数的结点nid是被激活, 即online的.但是为了安全它还是检查并警告内存结点不存在的情况. 接下来的工作委托给__alloc_pages, 只需传递一组适当的参数, 其中包括节点nid的备用内存域列表zonelist.
现在__alloc_pages函数没什么特别的, 它直接将自己的所有信息传递给__alloc_pages_nodemask来完成内存的分配
// http://lxr.free-electrons.com/source/include/linux/gfp.h?v=4.7#L428
static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist)
{
return __alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);
}2.3 伙伴系统的心脏__alloc_pages_nodemask
内核源代码将__alloc_pages_nodemask称之为”伙伴系统的心脏”(`the ‘heart’ of the zoned buddy allocator“), 因为它处理的是实质性的内存分配.
由于”心脏”的重要性, 我将在下文详细介绍该函数.
__alloc_pages_nodemask函数定义在include/linux/gfp.h?v=4.7#L428
3 选择页
我们先把注意力转向页面选择是如何工作的。
3.1 内存水印标志
还记得之前讲过的内存水印么
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])内核需要定义一些函数使用的标志,用于控制到达各个水印指定的临界状态时的行为, 这些标志用宏来定义, 定义在mm/internal.h?v=4.7, line 453
3.2 zone_watermark_ok函数检查标志
设置的标志在zone_watermark_ok函数中检查, 该函数根据设置的标志判断是否能从给定的内存域分配内存. 该函数定义在mm/page_alloc.c?v=4.7, line 2820
// http://lxr.free-electrons.com/source/mm/page_alloc.c?v=4.7#L2820
bool zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, unsigned int alloc_flags)
{
return __zone_watermark_ok(z, order, mark, classzone_idx, alloc_flags,
zone_page_state(z, NR_FREE_PAGES));
}而__zone_watermark_ok函数则完成了检查的工作, 该函数定义在mm/page_alloc.c?v=4.7, line 2752
// http://lxr.free-electrons.com/source/mm/page_alloc.c?v=4.7#L2752
/*
* Return true if free base pages are above 'mark'. For high-order checks it
* will return true of the order-0 watermark is reached and there is at least
* one free page of a suitable size. Checking now avoids taking the zone lock
* to check in the allocation paths if no pages are free.
*/
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int classzone_idx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & ALLOC_HARDER);
/* free_pages may go negative - that's OK
* free_pages可能变为负值, 没有关系 */
free_pages -= (1 << order) - 1;
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
/*
* If the caller does not have rights to ALLOC_HARDER then subtract
* the high-atomic reserves. This will over-estimate the size of the
* atomic reserve but it avoids a search.
*/
if (likely(!alloc_harder))
free_pages -= z->nr_reserved_highatomic;
else
min -= min / 4;
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
if (!(alloc_flags & ALLOC_CMA))
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return false;
/* If this is an order-0 request then the watermark is fine */
if (!order)
return true;
/* For a high-order request, check at least one suitable page is free
* 在下一阶,当前阶的页是不可用的 */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
if (alloc_harder)
return true;
/* 所需高阶空闲页的数目相对较少 */
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
}
return false;
}我们知道zone_per_state用来访问每个内存域的统计量. 在上述代码中, 得到的是空闲页的数目.
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);在解释了ALLOC_HIGH和ALLOC_HARDER标志之后(将最小值标记降低到当前值的一半或四分之一,使得分配过程努力或更加努力),
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (likely(!alloc_harder))
free_pages -= z->nr_reserved_highatomic;
else
min -= min / 4;该函数会检查空闲页的数目free_pages是否小于最小值与lowmem_reserve中指定的紧急分配值min之和.
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return false;如果不小于, 则代码遍历所有小于当前阶的分配阶, 其中nr_free记载的是当前分配阶的空闲页块数目.
/* For a high-order request, check at least one suitable page is free */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
if (alloc_harder)
return true;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
}如果内核遍历所有的低端内存域之后,发现内存不足, 则不进行内存分配.
3.3 get_page_from_freelist函数
http://blog.csdn.net/yuzhihui_no1/article/details/50776826
http://bbs.chinaunix.net/thread-3769001-1-1.html
get_page_from_freelist是伙伴系统使用的另一个重要的辅助函数. 它通过标志集和分配阶来判断是否能进行分配。如果可以,则发起实际的分配操作. 该函数定义在mm/page_alloc.c?v=4.7, line 2905
这个函数的参数很有意思, 之前的时候这个函数的参数只能用复杂来形容
static struct page *
get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order,
struct zonelist *zonelist, int high_zoneidx, int alloc_flags,
struct zone *preferred_zone, int migratetype) 但是这仍然不够, 随着内核的不段改进, 所支持的特性也越多, 分配内存时需要参照的标识也越来越多, 那难道看着这个函数的参数不断膨胀么, 这个不是内核黑客们所能容忍的, 于是大家想出了一个解决方案, 把那些相关联的参数封装成一个结构
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac)这个封装好的结构就是struct alloc_context, 定义在mm/internal.h?v=4.7, line 103
/*
* Structure for holding the mostly immutable allocation parameters passed
* between functions involved in allocations, including the alloc_pages*
* family of functions.
*
* nodemask, migratetype and high_zoneidx are initialized only once in
* __alloc_pages_nodemask() and then never change.
*
* zonelist, preferred_zone and classzone_idx are set first in
* __alloc_pages_nodemask() for the fast path, and might be later changed
* in __alloc_pages_slowpath(). All other functions pass the whole strucure
* by a const pointer.
*/
struct alloc_context {
struct zonelist *zonelist;
nodemask_t *nodemask;
struct zoneref *preferred_zoneref;
int migratetype;
enum zone_type high_zoneidx;
bool spread_dirty_pages;
};| 字段 | 描述 |
|---|---|
| zonelist | 当perferred_zone上没有合适的页可以分配时,就要按zonelist中的顺序扫描该zonelist中备用zone列表,一个个的试用 |
| nodemask | 表示节点的mask,就是是否能在该节点上分配内存,这是个bit位数组 |
| preferred_zone | 表示从high_zoneidx后找到的合适的zone,一般会从该zone分配;分配失败的话,就会在zonelist再找一个preferred_zone = 合适的zone |
| migratetype | 迁移类型,在zone->free_area.free_list[XXX] 作为分配下标使用,这个是用来反碎片化的,修改了以前的free_area结构体,在该结构体中再添加了一个数组,该数组以迁移类型为下标,每个数组元素都挂了对应迁移类型的页链表 |
| high_zoneidx | 是表示该分配时,所能分配的最高zone,一般从high–>normal–>dma 内存越来越昂贵,所以一般从high到dma分配依次分配 |
| spread_dirty_pages |
zonelist是指向备用列表的指针. 在预期内存域没有空闲空间的情况下, 该列表确定了扫描系统其他内存域(和结点)的顺序.
随后的for循环所作的基本上与直觉一致, 遍历备用列表的所有内存域,用最简单的方式查找一个适当的空闲内存块
首先,解释ALLOC_*标志(__cpuset_zone_allowed_softwall是另一个辅助函数, 用于检查给定内存域是否属于该进程允许运行的CPU).
zone_watermark_ok接下来检查所遍历到的内存域是否有足够的空闲页,并试图分配一个连续内存块。如果两个条件之一不能满足,即或者没有足够的空闲页,或者没有连续内存块可满足分配请求,则循环进行到备用列表中的下一个内存域,作同样的检查. 直到找到一个合适的页面, 在进行try_this_node进行内存分配
如果内存域适用于当前的分配请求, 那么buffered_rmqueue试图从中分配所需数目的页
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
bool fair_skipped = false;
bool apply_fair = (alloc_flags & ALLOC_FAIR);
zonelist_scan:
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* Distribute pages in proportion to the individual
* zone size to ensure fair page aging. The zone a
* page was allocated in should have no effect on the
* time the page has in memory before being reclaimed.
*/
if (apply_fair) {
if (test_bit(ZONE_FAIR_DEPLETED, &zone->flags)) {
fair_skipped = true;
continue;
}
if (!zone_local(ac->preferred_zoneref->zone, zone)) {
if (fair_skipped)
goto reset_fair;
apply_fair = false;
}
}
/*
* When allocating a page cache page for writing, we
* want to get it from a zone that is within its dirty
* limit, such that no single zone holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the zone's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* This may look like it could increase pressure on
* lower zones by failing allocations in higher zones
* before they are full. But the pages that do spill
* over are limited as the lower zones are protected
* by this very same mechanism. It should not become
* a practical burden to them.
*
* XXX: For now, allow allocations to potentially
* exceed the per-zone dirty limit in the slowpath
* (spread_dirty_pages unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* zones are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of zones in the
* dirty-throttling and the flusher threads.
*/
if (ac->spread_dirty_pages && !zone_dirty_ok(zone))
continue;
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (zone_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
ret = zone_reclaim(zone, gfp_mask, order);
switch (ret) {
case ZONE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case ZONE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone:
page = buffered_rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
}
}
/*
* The first pass makes sure allocations are spread fairly within the
* local node. However, the local node might have free pages left
* after the fairness batches are exhausted, and remote zones haven't
* even been considered yet. Try once more without fairness, and
* include remote zones now, before entering the slowpath and waking
* kswapd: prefer spilling to a remote zone over swapping locally.
*/
if (fair_skipped) {
reset_fair:
apply_fair = false;
fair_skipped = false;
reset_alloc_batches(ac->preferred_zoneref->zone);
z = ac->preferred_zoneref;
goto zonelist_scan;
}
return NULL;
}4 分配控制
如前所述, __alloc_pages_nodemask是伙伴系统的心脏. 我们已经处理了所有的准备工作并描述了所有可能的标志, 现在我们把注意力转向相对复杂的部分 : 函数__alloc_pages_nodemask的实现, 这也是内核中比较冗长的部分
之一. 特别是在可用内存太少或逐渐用完时, 函数就会比较复杂. 如果可用内存足够,则必要的工作会很快完成,就像下述代码
4 分配控制
如前所述, __alloc_pages_nodemask是伙伴系统的心脏. 我们已经处理了所有的准备工作并描述了所有可能的标志, 现在我们把注意力转向相对复杂的部分 : 函数__alloc_pages_nodemask的实现, 这也是内核中比较冗长的部分
之一. 特别是在可用内存太少或逐渐用完时, 函数就会比较复杂. 如果可用内存足够,则必要的工作会很快完成,就像下述代码
4.1 函数源代码注释
__alloc_pages_nodemask函数定义在include/linux/gfp.h?v=4.7#L428