1. openrestry的安装
OpenResty = Nginx + Lua,是⼀一个增强的Nginx,可以编写lua脚本实现⾮非常灵活的逻辑
(1)安装开发库依赖
yum install -y pcre-devel openssl-devel gcc curl
(2)配置yum的依赖源
yum install yum-utils yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
(3)安装OpenResty
yum install openresty
安装过程中出现问题的解决办法
cd /etc/yum.repos.d yum install wget wget https://openresty.org/package/centos/openresty.repo vi openresty.repo 将https改成http(改两个地方) yum install openresty
(4)openresty的默认安装⽬目录
/usr/local/openresty
(5)启动openresty(Nginx)
/usr/local/openresty/nginx/sbin/nginx
(6)通过浏览器器查看nginx的⻚页⾯面
2. 使用nginx+lua将日志数据写入指定文件中
需求:访问某个地址,nginx页面只显示1*1像素的空图片,然后将日志记录到指定的文件中去
(1)创建存放日志的目录并设置权限
mkdir /logs
chmod o+w /logs
为什么要设置权限呢,因为往logs的access.log文件写日志数据的用户是nobody,如下
![]()
(2)vi nginx.conf
location /log.gif{ #伪装成gif文件 default_type 'image/gif'; #关闭access_log access_log off; # 使用lua将nginx接受的参数写入到日志文件中 log_by_lua_file 'conf/log.lua'; #返回空图片 empty_gif; }
(3)在nginx的conf⽬目录下创建⼀一个log.lua⽂文件
vi /usr/local/openresty/nginx/conf/log.lua
log.lua脚本内容如下
-- 引⼊入lua所有解析json的库 local cjson = require "cjson" -- 获取请求参数列列表 local request_args_tab = ngx.req.get_uri_args() -- 使⽤用lua的io打开⼀一个⽂文件,如果⽂文件不不存在,就创建,a为append模式 local file = io.open("/logs/access.log", "a") -- 定义⼀一个json对象 local log_json = {} -- 将参数的K和V迭代出来,添加到json对象中 for k, v in pairs(request_args_tab) do log_json[k] = v end -- 将json写⼊入到指定的log⽂文件,末尾追加换⾏行行 file:write(cjson.encode(log_json), "\n") -- 将数据写⼊入 file:flush()
(4)在浏览器上请求feng05/log.gjf,能发现数据写入了/logs/access.log

上诉做法存在一个问题:如果一直往一个⽂件中写入数据,这个日志文件会过大,造成读写效率变低,现在按照小时生成文件
log.lua脚本内容修改如下所示
-- 引⼊入lua⽤用来解析json的库 local cjson = require "cjson" -- 获取请求参数列列表 local request_args_tab = ngx.req.get_uri_args() -- 获取当前系统时间 local time = os.date("%Y%m%d%H",unixtime) -- 使⽤用lua的io打开⼀一个⽂文件,如果⽂文件不不存在,就创建,a为append模式 local path = "/mylog/access-" .. time .. ".log" local file = io.open(path, "a") -- 定义⼀一个json对象 local log_json = {} -- 将参数的K和V迭代出来,添加到json对象中 for k, v in pairs(request_args_tab) do log_json[k] = v end -- 将json写⼊入到指定的log⽂文件,末尾追加换⾏行行 file:write(cjson.encode(log_json), "\n") -- 将数据写⼊入 file:flush()
这样就会按照时间滚动生成日志文件了
3. 使用flume将本地磁盘中的日志数据采集到的kafka中去
此处数据采集的架构为flume+kafka(taildir+kafkachannel), 这样既能实现负载均衡又能使用高可用
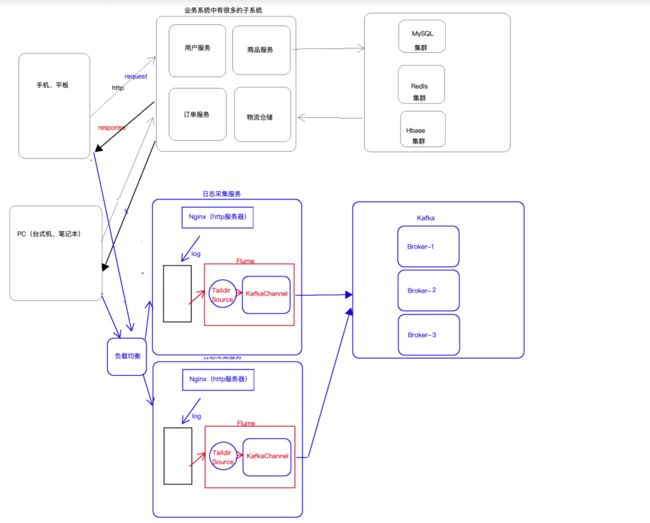
flume采集数据的配置文件如下所示:nginx-kafka.conf


a1.sources = r1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.positionFile = /root/taildir_position.json //此处表示taildir采集的记录,即偏移量 a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /log/access-.*\.log a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = feng05:9092,feng06:9092,feng07:9092 a1.channels.c1.kafka.topic = access12 a1.channels.c1.parseAsFlumeEvent = false a1.sources.r1.channels = c1
运行flume进行采集,数据即可采集至kafka中,命令如下
/usr/apps/apache-flume-1.9.0-bin/bin/flume-ng agent -n a1 -c conf \ -f myconf/nginx-kafka.conf \ -Dflume.root.logger=INFO,console /usr/apps/kafka_2.11-2.4.0/bin/kafka-console-consumer.sh --bootstrap-server feng05:9092 --topic access --from-beginning