TensorFlow Serving部署Bert-BiLSTM+CRF(NER)模型并提供服务
命名实体识别项目参考:https://github.com/macanv/BERT-BiLSTM-CRF-NER
和https://github.com/yumath/bertNER
特此感谢上述两个项目的贡献者!
项目上只说了如何去训练的,但是使用TensorFlow Serving进行部署,翻遍全网没有找到合适的资料,遂自己分析模型,按照模型的架构分析输入输出然后导出。
此模型的导出比较耗时,自己要分析模型的输入和输出,并做好对应关系,才能完整的导出模型并成功提供服务。
项目训练结束后结构如下:
一、模型序列化导出
1、这里模型的导出翻遍了网上所有的资料,均无法完整的导出使用,这里需要自己去分析模型的结构,然后写输入和输出即可。
分析过程:首先看predict.py文件,里面的预测函数main()
首先加载config配置文件

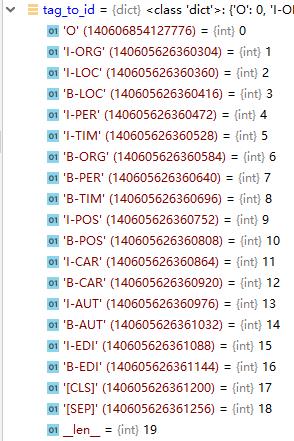
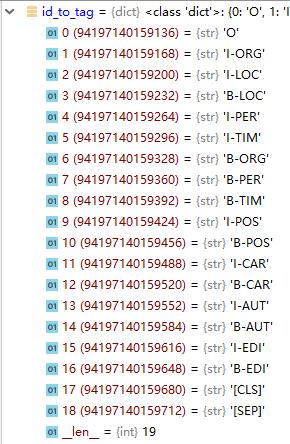
然后需要读取pickle文件,里面保存的是tag和id的对应关系
下面就是创建模型了,这里没有什么好解释的,模型的创建需要将ckpt文件加载,将配置文件加载进来等
def create_model(session, Model_class, path, config, logger):
# create model, reuse parameters if exists
model = Model_class(config)
ckpt = tf.train.get_checkpoint_state(path)
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
logger.info("Reading model parameters from %s" % ckpt.model_checkpoint_path)
#saver = tf.train.import_meta_graph('ckpt/ner.ckpt.meta')
#saver.restore(session, tf.train.latest_checkpoint("ckpt/"))
model.saver.restore(session, ckpt.model_checkpoint_path)
else:
logger.info("Created model with fresh parameters.")
session.run(tf.global_variables_initializer())
return model
到此,模型创建成功,下面开始预测了,我们主要分析的代码在预测这里
,主要是走model.evalute_line函数
![]()
此函数有三个输入:sess,input_from_line函数的输出,id_to_tag,id_to_tag上面已经有了,主要是input_from_line函数的输出:
def input_from_line(line, max_seq_length, tag_to_id):
"""
Take sentence data and return an input for
the training or the evaluation function.
"""
string = [w[0].strip() for w in line]
# chars = [char_to_id[f(w) if f(w) in char_to_id else '']
# for w in string]
char_line = ' '.join(string) # 使用空格把汉字拼起来
text = tokenization.convert_to_unicode(char_line)
tags = ['O' for _ in string]
labels = ' '.join(tags) # 使用空格把标签拼起来
labels = tokenization.convert_to_unicode(labels)
ids, mask, segment_ids, label_ids = convert_single_example(char_line=text,
tag_to_id=tag_to_id,
max_seq_length=max_seq_length,
tokenizer=tokenizer,
label_line=labels)
import numpy as np
segment_ids = np.reshape(segment_ids,(1, max_seq_length))
ids = np.reshape(ids, (1, max_seq_length))
mask = np.reshape(mask, (1, max_seq_length))
label_ids = np.reshape(label_ids, (1, max_seq_length))
return [string, segment_ids, ids, mask, label_ids]
input_from_line函数主要做了这么一件事情,就是将输入的内容进行tokenizer,这里tokenizer使用的是bert里面的内容
tokenizer = tokenization.FullTokenizer(vocab_file='chinese_L-12_H-768_A-12/vocab.txt',
do_lower_case=True)
此函数返回五个内容

这里面就有我们模型需要的内容,这里要重点观察一下数据
2、下面看一下evaluate_line函数
def evaluate_line(self, sess, inputs, id_to_tag):
trans = self.trans.eval(sess)
lengths, scores = self.run_step(sess, False, inputs)
batch_paths = self.decode(scores, lengths, trans)
tags = [id_to_tag[idx] for idx in batch_paths[0]]
return bio_to_json(inputs[0], tags[1:-1])
此函数有三个输入:分别是sess,上一步的五个内容(input_from_line),id_to_tag
这里模型有关的就是self.run_step(sess,False,inputs)这一句
然后点进run_step方法里面:
def run_step(self, sess, is_train, batch):
"""
:param sess: session to run the batch
:param is_train: a flag indicate if it is a train batch
:param batch: a dict containing batch data
:return: batch result, loss of the batch or logits
"""
feed_dict = self.create_feed_dict(is_train, batch)
if is_train:
global_step, loss, _ = sess.run(
[self.global_step, self.loss, self.train_op],
feed_dict)
return global_step, loss
else:
lengths, logits = sess.run([self.lengths, self.logits], feed_dict)
return lengths, logits
这里就比较清晰了,可以看到和模型预测有关的是sess.run([self.lengths, self.logits], feed_dict)
可以看到,模型的输入是feed_dict,模型的返回是self.lengths, self.logits,这里我们基本上确定了,模型的输入和输出了,但是这里有个坑,后面再说
3、看一下feed_dict如何创建出来的
def create_feed_dict(self, is_train, batch):
"""
:param is_train: Flag, True for train batch
:param batch: list train/evaluate data
:return: structured data to feed
"""
_, segment_ids, chars, mask, tags = batch
feed_dict = {
self.input_ids: np.asarray(chars),
self.input_mask: np.asarray(mask),
self.segment_ids: np.asarray(segment_ids),
self.dropout: 1.0,
}
if is_train:
feed_dict[self.targets] = np.asarray(tags)
feed_dict[self.dropout] = self.config["dropout_keep"]
return feed_dict
可以看到,feed_dict的创建输入有四个值,也就是evaluate_line函数里的inputs
将inputs里面的内容进行array转化,然后赋值给了三个参数,分别是:self.input_ids,self.input_mask,self.segment_ids,self.dropout,这里就很明显了,模型的输入就是上面这四个参数。
4、看一下模型的输出
lengths, logits = sess.run([self.lengths, self.logits], feed_dict)
表面上可以看到模型的输出是两个lengths和logits两个,但是这里有一个坑,因为我们需要对命名实体出来的结果做crf运算,在我们这里就是解码,decode
trans = self.trans.eval(sess)
lengths, scores = self.run_step(sess, False, inputs)
batch_paths = self.decode(scores, lengths, trans)
原始预测方法里面,对模型返回的lengths进行了解码
def decode(self, logits, lengths, matrix):
"""
:param logits: [batch_size, num_steps, num_tags]float32, logits
:param lengths: [batch_size]int32, real length of each sequence
:param matrix: transaction matrix for inference
:return:
"""
# inference final labels usa viterbi Algorithm
paths = []
small = -1000.0
start = np.asarray([[small]*self.num_tags +[0]])
for score, length in zip(logits, lengths):
score = score[:length]
pad = small * np.ones([length, 1])
logits = np.concatenate([score, pad], axis=1)
logits = np.concatenate([start, logits], axis=0)
path, _ = viterbi_decode(logits, matrix)
paths.append(path[1:])
return paths
可以看到解码函数里面最重要的就是path, _ = viterbi_decode(logits, matrix)这一句话,这里面有一个很重要的输入,就是matrix,也就是上一段代码中的trans = self.trans.eval(sess)
这里我花了不少时间找trans这个值,其实最后才发现是自己的问题
我们可以看trans从哪里来
def loss_layer(self, project_logits, lengths, name=None):
"""
calculate crf loss
:param project_logits: [1, num_steps, num_tags]
:return: scalar loss
"""
with tf.variable_scope("crf_loss" if not name else name):
small = -1000.0
# pad logits for crf loss
start_logits = tf.concat(
[small * tf.ones(shape=[self.batch_size, 1, self.num_tags]), tf.zeros(shape=[self.batch_size, 1, 1])], axis=-1)
pad_logits = tf.cast(small * tf.ones([self.batch_size, self.num_steps, 1]), tf.float32)
logits = tf.concat([project_logits, pad_logits], axis=-1)
logits = tf.concat([start_logits, logits], axis=1)
targets = tf.concat(
[tf.cast(self.num_tags*tf.ones([self.batch_size, 1]), tf.int32), self.targets], axis=-1)
self.trans = tf.get_variable(
"transitions",
shape=[self.num_tags + 1, self.num_tags + 1],
initializer=self.initializer)
log_likelihood, self.trans = crf_log_likelihood(
inputs=logits,
tag_indices=targets,
transition_params=self.trans,
sequence_lengths=lengths+1)
return tf.reduce_mean(-log_likelihood)
trans的来源其实很简单,代码中可以看到trans在loss_layer层里面定义着,它的初始化牵扯到很多的内容,最开始我的做法是将上面的代码都进行了重写,自己构造一个trans,但是结果一直不对,这里我也花了不少时间,后来我想到,正常来讲,模型序列化的时候,loss层是不用管的,那么trans应该在模型内部,这里就是一个正确的解决办法
5、看一下ckpt模型的结构
def get_origin_structure():
checkpoint_path = "/data/guoyin/ChineseNERTFServing/ckpt/ner.ckpt-43428"
# Read data from checkpoint file
reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path)
var_to_shape_map = reader.get_variable_to_shape_map()
# Print tensor name and values
for key in var_to_shape_map:
print("tensor_name: ", key)
# print(reader.get_tensor(key))
我们可以看到,模型由很多层,大概有180多层,但是有一层很重要
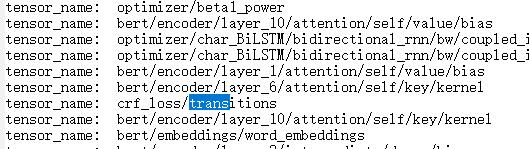
这里有我们想要的内容,因为根据模型里面的定义
self.trans = tf.get_variable(
"transitions",
shape=[self.num_tags + 1, self.num_tags + 1],
initializer=self.initializer)
self.trans就等于crf_loss/transitions里面的内容
至此,模型的导出基本就确定下来了
6、下面是模型导出的代码
# encoding=utf-8
import tensorflow as tf
import sys
import pdb
import os
from tensorflow.python import pywrap_tensorflow
from model import Model
from train import FLAGS, load_config
save_path = '/data/guoyin/ChineseNERTFServing/ckpt/ner.ckpt-43428'
def build_and_saved_model():
config = load_config(FLAGS.config_file)
model = Model(config)
session = tf.Session()
session.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess = session, save_path = save_path)
trans_model_save_path = '/data/guoyin/ChineseNERTFServing/trans_model/1'
builder = tf.saved_model.builder.SavedModelBuilder(trans_model_save_path)
# 将输入张量与名称挂钩
inputs = {
'input_ids': tf.saved_model.utils.build_tensor_info(model.input_ids),
'input_mask': tf.saved_model.utils.build_tensor_info(model.input_mask),
'segment_ids': tf.saved_model.utils.build_tensor_info(model.segment_ids),
'Dropout': tf.saved_model.utils.build_tensor_info(model.dropout)
}
outputs = {
'lengths': tf.saved_model.utils.build_tensor_info(model.lengths),
'logits': tf.saved_model.utils.build_tensor_info(model.logits),
'trans': tf.saved_model.utils.build_tensor_info(model.trans)
}
#签名定义
ner_signature_def = tf.saved_model.signature_def_utils.build_signature_def(
inputs=inputs,
outputs=outputs,
method_name = tf.saved_model.signature_constants.PREDICT_METHOD_NAME
)
builder.add_meta_graph_and_variables(
session,
[tf.saved_model.tag_constants.SERVING],
signature_def_map={
'ner_def':ner_signature_def
}
)
builder.save()
# 查看导出的模型的结构
def get_model_structure():
export_dir = '/data/guoyin/ChineseNERTFServing/trans_model/1/'
sess = tf.Session()
meta_graph_def = tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.SERVING], export_dir)
signature = meta_graph_def.signature_def
print(signature['ner_def'])
if __name__ == "__main__":
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# build_and_saved_model()
get_origin_structure()
可以查看导出的模型的结构
inputs {
key: "Dropout"
value {
name: "Dropout:0"
dtype: DT_FLOAT
tensor_shape {
unknown_rank: true
}
}
}
inputs {
key: "input_ids"
value {
name: "input_ids:0"
dtype: DT_INT32
tensor_shape {
dim {
size: -1
}
dim {
size: -1
}
}
}
}
inputs {
key: "input_mask"
value {
name: "input_mask:0"
dtype: DT_INT32
tensor_shape {
dim {
size: -1
}
dim {
size: -1
}
}
}
}
inputs {
key: "segment_ids"
value {
name: "segment_ids:0"
dtype: DT_INT32
tensor_shape {
dim {
size: -1
}
dim {
size: -1
}
}
}
}
outputs {
key: "lengths"
value {
name: "Sum:0"
dtype: DT_INT32
tensor_shape {
dim {
size: -1
}
}
}
}
outputs {
key: "logits"
value {
name: "project/Reshape:0"
dtype: DT_FLOAT
tensor_shape {
dim {
size: -1
}
dim {
size: -1
}
dim {
size: 19
}
}
}
}
outputs {
key: "trans"
value {
name: "crf_loss/transitions:0"
dtype: DT_FLOAT_REF
tensor_shape {
dim {
size: 20
}
dim {
size: 20
}
}
}
}
method_name: "tensorflow/serving/predict"
导出的模型

二、本地测试导出的模型
# encoding=utf-8
import tensorflow as tf
import pickle
from loader import input_from_line
import numpy as np
from numpy import random,mat
import os
from tensorflow.contrib.layers.python.layers import initializers
from tensorflow.contrib.crf import viterbi_decode
from utils import bio_to_json
from tensorflow.contrib.crf import crf_log_likelihood
# 这里是本地测试导出的pb模型的代码
def convert(sentence):
maps_path = '/data/guoyin/ChineseNERTFServing/maps.pkl'
with open(maps_path, "rb") as f:
tag_to_id, id_to_tag = pickle.load(f)
return input_from_line(sentence,150,tag_to_id)
def predict(feed_dict,signature):
ids_tensor_name = signature['ner_def'].inputs['input_ids'].name
mask_tensor_name = signature['ner_def'].inputs['input_mask'].name
segment_tensor_name = signature['ner_def'].inputs['segment_ids'].name
Dropout_tensor_name = signature['ner_def'].inputs['Dropout'].name
lengths_tensor_name = signature['ner_def'].outputs['lengths'].name
logits_tensor_name = signature['ner_def'].outputs['logits'].name
trans_tensor_name = signature['ner_def'].outputs['trans'].name
input_ids = sess.graph.get_tensor_by_name(ids_tensor_name)
input_mask = sess.graph.get_tensor_by_name(mask_tensor_name)
segment_ids = sess.graph.get_tensor_by_name(segment_tensor_name)
Dropout = sess.graph.get_tensor_by_name(Dropout_tensor_name)
lengths = sess.graph.get_tensor_by_name(lengths_tensor_name)
logits = sess.graph.get_tensor_by_name(logits_tensor_name)
trans = sess.graph.get_tensor_by_name(trans_tensor_name)
# 注意,这里的feed_dict要和模型里面的键值一样,否则会报错的
lengths,logits, trans = sess.run([lengths,logits,trans], feed_dict={input_ids:feed_dict['input_ids'],
input_mask:feed_dict['input_mask'],
segment_ids:feed_dict['segment_ids'],
Dropout:feed_dict['dropout']})
return lengths, logits, trans
def create_feed_dict(batch):
"""
:param is_train: Flag, True for train batch
:param batch: list train/evaluate data
:return: structured data to feed
"""
_, segment_ids, chars, mask, tags = batch
feed_dict = {
'input_ids': np.asarray(chars),
'input_mask': np.asarray(mask),
'segment_ids': np.asarray(segment_ids),
'dropout': 1.0,
}
return feed_dict
def decode(logits, lengths, matrix, num_tags):
"""
:param logits: [batch_size, num_steps, num_tags]float32, logits
:param lengths: [batch_size]int32, real length of each sequence
:param matrix: transaction matrix for inference
:return:
"""
# inference final labels usa viterbi Algorithm
paths = []
small = -1000.0
start = np.asarray([[small]*num_tags +[0]])
for score, length in zip(logits, lengths):
score = score[:length]
pad = small * np.ones([length, 1])
logits = np.concatenate([score, pad], axis=1)
logits = np.concatenate([start, logits], axis=0)
path, _ = viterbi_decode(logits, matrix)
paths.append(path[1:])
return paths
if __name__ == "__main__":
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 构造转移矩阵
maps_path = '/data/guoyin/ChineseNERTFServing/maps.pkl'
with open(maps_path, "rb") as f:
tag_to_id, id_to_tag = pickle.load(f)
sentence = '重庆市南川中学副校长张竞说,寒假放假前高三年级还有10%左右的内容没复习完,学校开学受疫情影响延期不少,“老师们压力比较大,怕耽误复习进度。”'
sentences = sentence.split('。')
batch = convert(sentences[0])
batch_size = tf.shape(batch[2])[0]
export_dir = '/data/guoyin/ChineseNERTFServing/trans_model/1/'
sess = tf.Session()
sess.run(tf.global_variables_initializer())
feed_dict = create_feed_dict(batch)
meta_graph_def = tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.SERVING], export_dir)
signature = meta_graph_def.signature_def
lengths, logits, trans = predict(feed_dict=feed_dict,signature=signature)
print(type(lengths))
print(type(logits))
print(type(trans))
#这里需要转换为矩阵
matrix = mat(trans)
batch_paths = decode(logits=logits, lengths=lengths, matrix=matrix, num_tags=len(tag_to_id))
tags = [id_to_tag[idx] for idx in batch_paths[0]]
result = bio_to_json(batch[0], tags[1:-1])
print(result['entities'])
其实模型的输入和输出确定以后,那么这里要做的就是前处理和后处理了,这些都可以参考源代码书写即可
有一个点需要注意:matrix = mat(trans)
输出结果:
[{'word': '重庆市', 'start': 0, 'end': 3, 'type': 'LOC'}, {'word': '南川中学', 'start': 3, 'end': 7, 'type': 'ORG'}, {'word': '副校长', 'start': 7, 'end': 10, 'type': 'POS'}, {'word': '张竞', 'start': 10, 'end': 12, 'type': 'PER'}]
结果完全正确,说明模型的导出正确
三、docker部署模型
将导出的模型迁移到/root/serving_model/serving/tensorflow_serving/servables/tensorflow/testdata/nermodel下面
然后部署模型:
docker run --runtime=nvidia -p 8509:8501 -p 8508:8500 --mount
type=bind,source=/root/serving_model/serving/tensorflow_serving/servables/tensorflow/testdata/nermodel,target=/models/nermodel
-e CUDA_VISIBLE_DEVICES=1 -e MODEL_NAME=nermodel -t tensorflow/serving:latest-gpu --per_process_gpu_memory_fraction=0.1 &
四、本地测试grpc调用模型
# encoding=utf-8
import pickle
import grpc
import numpy as np
from numpy import mat
import tensorflow as tf
from tensorflow.contrib.util import make_tensor_proto
import time
from utils import bio_to_json
from tensorflow.contrib.crf import viterbi_decode
from loader import input_from_line
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
def convert(sentence):
maps_path = '/data/guoyin/ChineseNERTFServing/maps.pkl'
with open(maps_path, "rb") as f:
tag_to_id, id_to_tag = pickle.load(f)
return input_from_line(sentence,150,tag_to_id)
def decode(logits, lengths, matrix, num_tags):
"""
:param logits: [batch_size, num_steps, num_tags]float32, logits
:param lengths: [batch_size]int32, real length of each sequence
:param matrix: transaction matrix for inference
:return:
"""
# inference final labels usa viterbi Algorithm
paths = []
small = -1000.0
start = np.asarray([[small]*num_tags +[0]])
for score, length in zip(logits, lengths):
score = score[:length]
pad = small * np.ones([length, 1])
logits = np.concatenate([score, pad], axis=1)
logits = np.concatenate([start, logits], axis=0)
path, _ = viterbi_decode(logits, matrix)
paths.append(path[1:])
return paths
server = '192.168.1.99:8508'
channel = grpc.insecure_channel(server)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'nermodel'
request.model_spec.signature_name = 'ner_def'
start = time.perf_counter()
# 这里是向模型里面输入数据
sentence = '重庆市南川中学副校长张竞说,寒假放假前高三年级还有10%左右的内容没复习完,学校开学受疫情影响延期不少,“老师们压力比较大,怕耽误复习进度。”'
string, segment_ids, ids, mask, label_ids = convert(sentence)
request.inputs['input_ids'].CopyFrom(make_tensor_proto(ids, dtype=np.int32))
request.inputs['input_mask'].CopyFrom(make_tensor_proto(mask, dtype=np.int32))
request.inputs['segment_ids'].CopyFrom(make_tensor_proto(segment_ids, dtype=np.int32))
request.inputs['Dropout'].CopyFrom(make_tensor_proto(np.float32(1.0)))
response = stub.Predict(request, 30.0)
end = time.perf_counter()
# # 这里是后处理,包括解码等过程
maps_path = '/data/guoyin/ChineseNERTFServing/maps.pkl'
with open(maps_path, "rb") as f:
tag_to_id, id_to_tag = pickle.load(f)
# 句子最大长度
max_seq_len = 150
lengths = response.outputs['lengths'].int_val
logits = response.outputs['logits'].float_val
trans = response.outputs['trans'].float_val
lengths = np.reshape(lengths, (1,))
logits = np.reshape(logits, (max_seq_len,len(tag_to_id)))
logits = logits[np.newaxis, :]
trans = np.reshape(trans, (len(tag_to_id) +1, len(tag_to_id) +1))
matrix = mat(trans)
batch_paths = decode(logits=logits, lengths=lengths, matrix=matrix, num_tags=len(tag_to_id))
tags = [id_to_tag[idx] for idx in batch_paths[0]]
result = bio_to_json(string, tags[1:-1])
print("预测耗时{0}秒".format(str(end-start)))
print(result['entities'])
上面的代码就是本地调用TensorFlow Serving上部署的模型
这里要注意的地方就是,模型输出的lengths/logits/trans都是array类型的,不能直接进行解码,需要reshape。
lengths = np.reshape(lengths, (1,))
logits = np.reshape(logits, (max_seq_len,len(tag_to_id)))
logits = logits[np.newaxis, :]
trans = np.reshape(trans, (len(tag_to_id) +1, len(tag_to_id) +1))
然后就可以正常解码
![]()
以上就是正常输出的结果
五、出错的地方
如果报错:tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm.
有三个原因:第一个就是cuda和cuDNN版本与tensorflow不兼容导致
第二个就是显卡驱动太旧
如果以上都没有问题,那么就是第三个原因:开了多个TensorFlow,都要使用GPU,也会出现这个问题,我这里出现这个问题,是因为其中一块GPU上我已经部署了一个serving项目,程序如果再次调用这块GPU就会出现上述错误
六、分析过程学到的知识
这个过程学到的知识就是:任何模型的架构都要看懂,不需要每一个函数都扣得很清楚,但是总体结构和流程要很熟练。其实TensorFlow Serving需要的模型就是SavedModel格式的,这个在TensorFlow官网写的很清楚

savedmodel格式的文件有三个重要的内容:就是输入(inputs)、输出(outputs)和method_name。
输入和输出都是tensor格式。最后一个是模型的名字,一般都是tensorflow/serving/predict即可
那么同样的思路,我们需要在要部署的任何模型中找到输入和输出即可。
学到最大的知识点就是要学会自己分析自己模型的架构,因为谷歌和百度都没有任何人会对你的模型有做导出现成的方案。
参考:
https://www.bbsmax.com/A/gAJGpAYX5Z/