CVPR2020最佳目标检测 | AdderNet(加法网络)含论文及源码链接
点击蓝字关注我们

扫码关注我们
公众号 : 计算机视觉战队
扫码回复:加法网络,获取源码及论文链接
CVPR2020收录的结果已经早早公布,想必很多同学都有知晓一些,“计算机视觉战队”今天从中又挑选了一篇目标检测类的文献,和大家分享这篇文献中的新算法框架!
简要
与简单的加法运算相比,乘法运算具有更高的计算复杂度。深度神经网络中广泛使用的卷积正好是来度量输入特征和卷积滤波器之间的相似性,这涉及浮点值之间的大量乘法。现在作者提出了加法网络(AdderNets)来交换深度神经网络中的这些大规模乘法,特别是卷积神经网络(CNNs),以获得更简易的加法以降低计算成本。

在加法器网中,作者以滤波器与输入特征之间的L1范数距离作为输出响应。分析了这种新的相似性度量对神经网络优化的影响。为了获得更好的性能,通过研究全精度梯度开发了一种特殊的反向传播方法。然后,作者还提出了一种自适应学习率策略,根据每个神经元梯度的大小来增强加法网络的训练过程。

上图就是加法网络的特征可视化结果。
研究背景
虽然深度神经网络的二值化滤波器大大降低了计算成本,但原始识别精度往往无法保持。此外,二进制网络的训练过程不稳定,通常要求较慢的收敛速度和较小的学习速率。经典CNN中的卷积实际上是测量两个输入的相似性。研究人员和开发人员习惯于将卷积作为默认操作,从视觉数据中提取特征,并引入各种方法来加速卷积,即使存在牺牲网络能力的风险。但几乎没有人试图用另一种更有效的相似性度量来取代卷积。事实上,加法的计算复杂度要比乘法低得多。因此,作者有动机研究用卷积神经网络中的加法代替乘法的可行性。
相关工作
Network Pruning
网络剪枝主要通过移除冗余的权重来实现网络的压缩和加速。比如用奇异值分解(SVD)全连接层的权重矩阵、去除预训练中的部分权重、将filter变换到频域避免浮点计算。还有的通过去除冗余的filter、或者对channel进行选择这样冗余filter/channel后续的计算就无需考虑了。

Efficient Blocks Design
许多工作不是直接降低预先训练的神经网络的计算复杂度,而是集中在设计新的模块或操作来取代传统的卷积滤波器。Landola等人(Forrest N Iandola, Song Han, Matthew W Moskewicz,Khalid Ashraf, William J Dally, and Kurt Keutzer.Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size. 2017)引入了瓶颈结构,大大降低了CNN的计算成本。Howard等人(Andrew G Howard, Menglong Zhu, Bo Chen, DmitryKalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXivpreprint arXiv:1704.04861, 2017)设计了移动网络,它将传统的卷积滤波器分解为点和深度卷积滤波器,FLOPs要少得多。张等人(Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun.Shufflenet: An extremely efficient convolutional neural network for mobile devices. In CVPR, pages 6848–6856, 2018)组合群卷积和信道洗牌操作,以建立有效的神经网络与较少的计算。胡等人(Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, pages 7132–7141, 2018)提出了挤压和激励块,该模块通过建模信道之间的相互依赖关系来关注信道的关系,以稍微增加的计算成本来提高性能。吴等人(Bichen Wu, Alvin Wan, Xiangyu Yue, Peter Jin, SichengZhao, Noah Golmant, Amir Gholaminejad, Joseph Gonzalez, and Kurt Keutzer. Shift: A zero flop, zero parameteralternative to spatial convolutions. In CVPR, pages 9127–9135, 2018)提出了一种无参数的“移位”操作,该操作具有零失败和零参数,以取代传统滤波器,大大降低了CNN的计算和存储成本。钟等人 (Huasong Zhong, Xianggen Liu, Yihui He, Yuchun Ma, andKris Kitani. Shift-based primitives for efficient convolutionalneural networks. arXiv preprint arXiv:1809.08458, 2018)进一步将基于移位的原理推入信道移位、地址移位和快捷移位,以减少GPU上的推理时间,同时保持性能。Wang等人(Yunhe Wang, Chang Xu, Chunjing Xu, Chao Xu, andDacheng Tao. Learning versatile filters for efficient convolutional neural networks. In NeuriPS, pages 1608–1618, 2018)开发了多功能卷积滤波器,利用较少的计算和参数生成更有用的特征。
Knowledge Distillation
除了去除网络中的冗余连接,Hinton还提出了knowledge distillation的概念,借助teacher网络的学习能力来指导student网络完成复杂任务的学习,变种有多个teacher网络、对中间隐层的学习以及对不同teacher网络学到的特征整合成新的知识来帮助student网络的训练。
Adder Network

不同类别的CNN特征按其角度来划分。由于AdderNet使用L1范数来区分不同的类,因此AdderNet的特征倾向于聚集到不同的类中心。
对于CNN中的卷积运算,假定输入X,filter表示为F,卷积后输出的是二者的相似性度量,表述如下面公式:

实际上二者的相似性度量可以有多种途径,但都涉及到大量的乘法运算,这就增加了计算开销。因此作者通过计算L1距离完成输入和filter之间的相似性度量。而L1距离仅涉及到两个向量差的绝对值,这样输出就变成了如下:

我们注意到使用互相关运算还是L1距离都可以完成相似性度量,但二者的输出结果还是有一些差别的。通过卷积核完成输入特征图谱的加权和计算,结果可正可负;但adder filter输出的结果恒为负,为此作者引入了batch normalization将结果归一化到一定范围区间内从而保证传统CNN使用的激活函数在此依旧可以正常使用。虽然BN的引入也有乘法操作但计算复杂度已远低于常规卷积层。conv和BN的计算复杂度分别如下:

Optimization
神经网络利用反向传播来计算滤波器的梯度和随机梯度下降来更新参数。在CNN中,输出特征Y相对于滤波器F的偏导数被计算为:

但是在AdderNets中,Y相对于滤波器F的偏导数是:

但signSGD优化方法几乎不会选择到最陡的方向,而且随着维度增加效果会更差,因此本文使用如下公式进行梯度更新:

此外,如果使用full-precision gradient的更新方法,由于涉及到前层的梯度值很容易导致梯度爆炸,因此本文还通过使用HardTanh将输出限定在[-1,1]范围内。
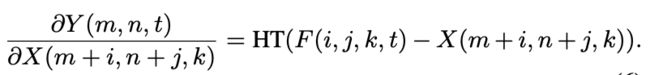
输出特征Y相对于输入特征X的偏导数计算为:

Adaptive Learning Rate Scaling
在传统的CNN中,假设权值和输入特征是独立的,服从正态分布,输出的方差大致可以估计为:

相反,对于AdderNets,输出的方差可以近似为:

AdderNets的输出具有较大方差,在更新时根据常规的链式法则会导致梯度比常规CNN更小,从而导致参数更新过慢。因此自然而然想到通过引入自适应学习率调整参数的更新learningrate组成:

包括神经网络的全局学习率和本地学习率,其中本地学习率表示为:
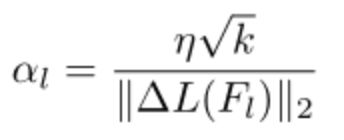
这样可以保证每层更新的幅度一致,最终AdderNet的训练过程表述为:

实验
在MNIST、CIFAR及ImageNet数据集山验证了AdderNet的有效性,随后进行了消融实验以及对提取的特征进行可视化。实验平台和框架:V100 Pytorch。
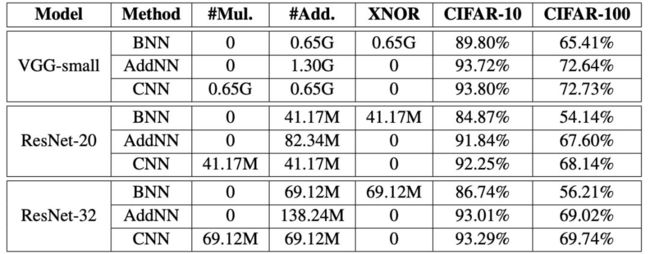
CIFAR-10和CIFAR-100 datasets分类结果
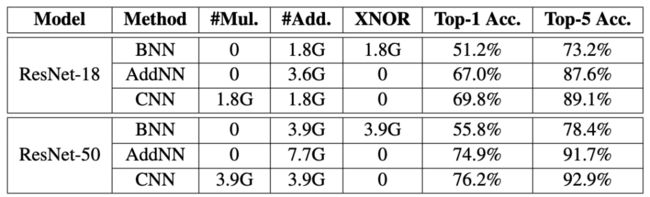
ImageNet datasets分类结果
AdderNet使用L1距离来度量输入与filter之间的关系,而不是使用卷积的互相关。因此需要探究一些AdderNet与CNN特征空间上的差异。因此就在MNIST数据集上搭建了LeNet++:6conv+1fc,每层神经元数目依次为:32,32,64,64,128,128,2。同样其中的conv层用add filter替换可视化结果如图1所示,CNN的可视化结果为右侧,相似度通过cosin计算得到的,因此分类通过角度进行的分类。左侧是AdderNet的可视化结果,可以看到不同种类的聚类中心不同,这也验证了AdderNet具有同CNN相似的辨别能力。
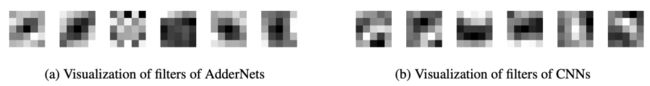
对filter的可视化结果如上图所示,虽然AdderNet和CNN用的度量矩阵不同,但都具有特征提取的能力。
Learning curve of AdderNets using different optimization schemes

权重分布的可视化
对LeNet-5-BN的第三层进行可视化,AdderNet权重更接近Laplace分布,CNN的权重近似高斯分布,分别对应L1-norm和L2-norm。

注:左边是AdderNet,右边是CNNs
扫码关注我们
公众号 : 计算机视觉战队
扫码回复:加法网络,获取源码及论文链接
