还想看更多文章的朋友可以访问我的个人博客
散列表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value) 的思想其实很简单,就是把Key(任意长度)通过一个固定的算法函数,即所谓的哈希函数转换成一个整型数字(固定长度),然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
散列算法。
根据 key(数据特征) 计算出对应数据的存储位置的算法叫做散列算法(position=hash(key);,又称哈希算法。
散列算法需要满足一下条件:
- 对输入值进行运算后,应得到固定长度的计算结果;
- 对于不同的输入值,得到的结构可能相同。
- 散列函数的输出值尽量接近均匀分布。
- x的微小变化可以使f(x)发生非常大的变化,即所谓“雪崩效应”(Avalanche effect)。
例如:
除法散列法
公式:
f(x) = x % N(N为常数,不大于数组的长度)
取关键字被某个不大于散列表表长 L 的数 N 除后所得的余数为散列地址。对 N 的选择很重要,一般取"素数"或 L,若 N 选的不好,容易产生同义词
平方散列法
公式:
index = (value * value) >> 28(右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取下标。
斐波那契散列法
公式:
index = (value * num) >> 28(此处的num为特定的乘数,其余与平方散列法相同)
在上述“平方散列法”中,需要以 value 的值作为乘数,有没有可能用特定的数值作为乘数。
- 对于16位整数而言,这个乘数是
40503。 - 对于32位整数而言,这个乘数是
2654435769。 - 对于64位整数而言,这个乘数是
11400714819323198485.
哈希冲突
哈希重复,也就是两个不同输入通过哈希函数运算所得到的地址值相同的情况。哈希冲突是无法避免的,因此,哈希算法的选择直接决定了哈希冲突发送的概率;同时必须要对哈希冲突进行处理。
开放寻址法
开放寻址法,即把所有的元素都存放在散列表中,也就是每个表项包含动态集合的一个元素(元素可以为NULL)。
- 在开放寻址法中,当要插入一个元素时,可以连续地检查散列表的各个项(连续检查是可以通过不同的算法获得偏移位),直到找到一个空槽来放置这个元素为止。
- 当查找一个元素时,要检查所有的表项,直到找到所需的元素,或者最终发现元素不在表中。
- 在开放寻址法中,对散列表元素的删除操作执行起来比较困难。当我们从槽 i 中删除关键字时,不能仅将此位置元素置空。因为这样做的话,会导致在无法判断此位置是否有元素。应该用个特殊的值表示该元素已经删除。
公式:
Hi=(H(key) + di) % m, [ i = 1, 2,…,k * (k <= m-1) ]
其中H(key)为散列函数,m为散列表长;di为增量序列,可有下列三种取法:
线性探测再散列
公式:di = 1,2,3,…,m-1
线性再散列法是最简单的处理冲突的方案。插入数据时,当发生冲突,算法会自动从该空间的位置向后遍历哈希表,直到找到下一个空间为空的位置。(这样会导致相同hash的数据重复存放,且会占用其他hash所对应的空间。)查询数据时,算法会先定位到该hash所对应的位置空间上,若是没找到匹配数据则会从该位置继续向后遍历哈希表,直到找到:
- 对应的数据,返回对应数据。
- 空的空间,并返回所对应的值为空。
- 遍历结束也未出现上两种情况,返回未找到,并表示该哈希表是满的。
线性探测法处理冲突的但存在下列缺点:
- 处理溢出需另编程序。一般可另外设立一个溢出表,专门用来存放上述哈希表中放不下的记录。此溢出表最简单的结构是顺序表,查找方法可用顺序查找。
- 按上述算法建立起来的哈希表,删除工作非常困难。如果将此元素删除,查找的时会发现空槽,则会认为要找的元素不存在。只能标上已被删除的标记,否则,将会影响以后的查找。
- 线性探测法很容易产生堆聚现象。所谓堆聚现象,就是存入哈希表的记录在表中连成一片。按照线性探测法处理冲突,如果生成哈希地址的连续序列愈长 ( 即不同关键字值的哈希地址相邻在一起愈长 ) ,则当新的记录加入该表时,与这个序列发生冲突的可能性愈大。因此,哈希地址的较长连续序列比较短连续序列生长得快,这就意味着,一旦出现堆聚 ( 伴随着冲突 ) ,就将引起进一步的堆聚。
二次探测再散列
公式:di = 1^2, -1^2, 2^2, -2^2, 3^2,…,±(k)^2, (k <= m/2)
伪随机探测再散列
公式:di = pseudo-random
随机探测的基本思想是:将线性探测的步长从常数改为随机数,即令: hash = (hash + RN) % m ,其中 RN 是一个随机数。在实际程序中应预先用随机数发生器产生一个随机序列,将此序列作为依次探测的步长。这样就能使不同的关键字具有不同的探测次序,从而可以避 免或减少堆聚。基于与线性探测法相同的理由,在线性补偿探测法和随机探测法中,删除一个记录后也要打上删除标记。
拉链法
最常见的实现方案如下,可称之为“数组链表法”。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。结合两者的特性的数据结构便是寻址,插入删除代价都相对均衡的哈希表。其中大致结构如下:
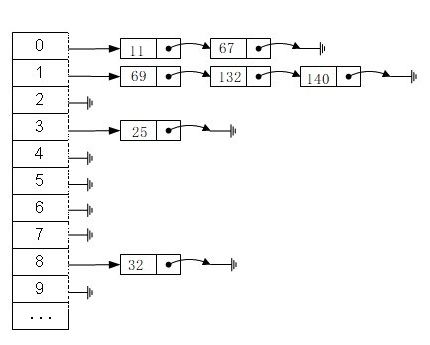
从上图的结构中可以看出,左边的连续存储结构为数组,而数组的每个空间都存放一个指向链表头部的指针。需要按元素的特征将数据分配到不同的链表中去。而将元素特征转换为数组下标的方法就是“散列法”。(例如 Java中的 HashTable、HashMap 都是使用“拉链法”实现)。
拉链法的优点:
- 拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- 由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- 开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
- 在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
拉链法的缺点
指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
本篇文章是写于 2017.08.07 的学习笔记,那时正是酷暑,稍稍坐一会就汗流浃背。别家空调压缩机排出的热气通过门下的缝隙灌入我的房间,使我的室温甚至高于窗外艳阳下的温度,挥汗写下这篇学习笔记。正因如此,我也知道肯定错误百出,望大家多加指正。