MySQL 亿级数据需求的优化思路(二),100亿数据,1万字段属性的秒级检索
最近在研究亿级数据的时候,无意中看到了一个关于写58同城的文章
https://blog.csdn.net/admin1973/article/details/55251499?from=timeline
其实上面讲的version+ext的方式以及压缩json的思路,对于我来讲都可以看得懂,想得通,其实最感兴趣的还是他们那个E-Search架构,然后开始进行实验和研究其算法。

上图是从那篇文章里扒出来的图,是由他们58几个牛人写的,并维护的。
按照我的理解一步一步的进行逻辑剖析,有误的话希望大婶们及时评论改正。
分析思路开始:
| tid | uid | time | cateid | ext |
| 1 | 1 | 123 | 招聘 | {"job":"driver","salary":8000,"location":"bj"} |
| 2 | 1 | 345 | 房产 | {"rent":1000,"location":"dl","acreage":120} |
| 3 | 1 | 567 | 二手 | {"type":"iphone","money",200} |
这个是文章里提到的数据表结构,ext存这比较多可扩展的属性。然后E-Search就是要对这些属性进行快速的查询搜索。
里面提到了Searcher1 Searcher2,就是一个个用于建立索引用的表。
比如房产:
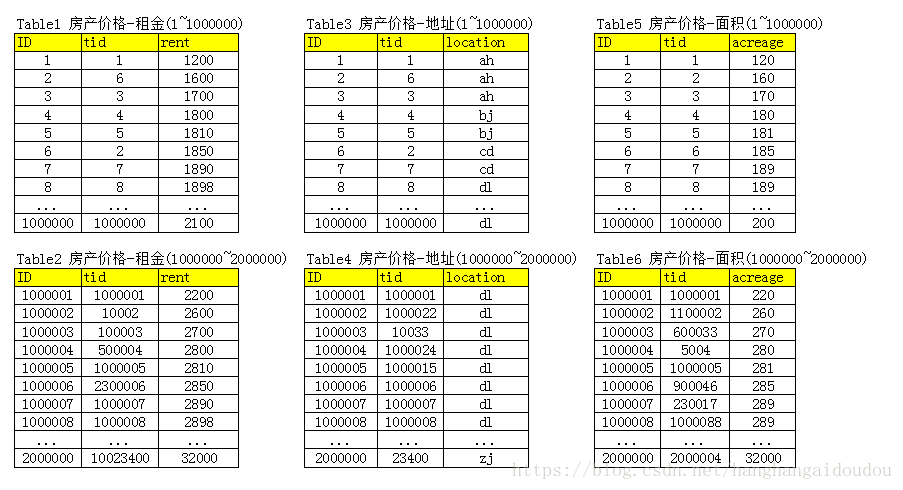
房产现在里面有三个字段,每一个字段对应一张表或多张表,因为字段数据到一定数量的时候,可能单台服务器的存储空间不够了,所以需要分库分表。分表可以按照Hash算法,然后切割成单台服务器可以容下的数量范围,在超过一定冗余范围,就要增加一台冗余服务器,继续分库分表。上面的例子,按照每张表存储100万数据的方式存储。
里面提到merger服务,合并层,并且强调了,增加机器就可以扩容,同时也说明了服务启动时可以加载索引数据到内存,请求访问时从内存中load数据,访问速度很快。
那这个merger要做些什么呢?应该怎么做呢?
好了,现在分析业务需求,咱们模拟一个场景和一个查询需求,分析一下整体是怎么工作的。
在看了58同城网站时候,发现了几个特点。
一、有分页,但是没有一共多少条的分析和统计
二、检索条件是可以随意的设定,有很多的条件可以进行添加
然后我们沿着我们的表设计开始进行模拟一个搜索过程。
那么,我们假设几个查询条件
价格:1700~2500
地址:大连 (dl)
面积:190平米以内
按照价格从低到高进行排序
分页每页10条
按照以上的查询条件,我们分别在这六张表上进行搜索。
租金:Table1 2000条,Table2 500条,一共2500条
地址:Table3 999993条,Table4 8条,一共 1000001条
面积:Table5 5000条
下一步,当然就要把这些条件查询的结果进行合并,就是所谓的merger要做的事。
首先,要知道排序要用价格从低到高进行排序,我们知道查询结果就是按照索引进行排序好的排序文件,大小就是12345这样从低到高进行索引的。那就从Table1开始循环,因为是and关系,只要数据既符合地址的条件,又符合面积的条件,就算合格一条,只要累积满足了10条,就可以返回了。这个时候,其他的条件加载在内存里,但怎么比较比较快呢?
这时候,就涉及到Hash算法了,比如Java有个HashMap,我们可以把其他数据全部加载到HashMap里,然后Table1每循环一次要用containsKey方法,与其他的表进行确认一下是否存在,由于Hash算法速度很快,就可以很快的凑出来前10条。
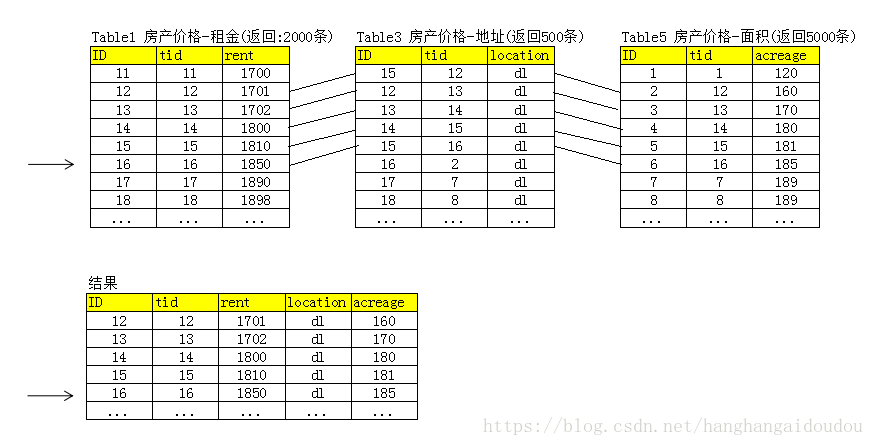
这个时候,第一页的结果就完成了。
那么,就要问了,第二页,第三页,第四页怎么办?
在我们循环Table1的时候,会有一个循环的游标位置,index,比如凑了10条,游标游到了25才凑齐返回,那我们就把这个25一同返回,作为下一页的起点。
由于系统不需要统计一共查询多少结果,所以我们依次往下迭代就可以了。
前台得到了25这个游标,那么,下一页直接从Table1结果25在往后开始循环寻找条件符合的数据,凑成10条,并且返回index ,依次往后进行。
其他问题总结:
一、索引表冗余问题
就像那个文章所说的,系统不要求一致性,所以每次有新的数据插入,在插入Ext表之后,分别给到searcher的索引表里,进行更新索引,当某个字段索引表空间不够了,增加冗余服务器,进行切分数据以保证重建索引速度及存放空间能力。
二、merger服务冗余问题
由于merger服务与索引表在同一服务器上,当表控件需要增加的时候,merger服务也随着增加,同时要保证这台服务器的内存能够可以实现单表最大数据存储计算能力。
三、EXT数据的冗余问题
直接就按照UID的增加,如果单台服务器不够,直接增加
四、100亿数据导入问题
有个100亿的数据问题,要求从Oracle数据库导入到MySql下。要求原系统不能停,还要求最后的数据是一致的。这个思路就是,把MySql进行分库分表规划好后,进行导数据,并且业务系统在不停的情况下产生的新的操作,同时更新Oracle和MySql,最后就可以实现两个库的一致性。