当深度学习遇上量化交易:图与知识图谱篇
当深度学习遇上量化交易:图与知识图谱篇
本文主要回顾三篇将图和知识图谱应用到量化交易上的文章。
©PaperWeekly 原创 · 原作者|桑运鑫
本文主要回顾三篇将图和知识图谱应用到量化交易上的文章。
使用Rolling Window分析探索用于股市预测的图神经网络
论文标题:Exploring Graph Neural Networks for Stock Market Predictions with RollingWindow Analysis
论文来源:NeurIPS 2019
论文链接:https://arxiv.org/abs/1909.10660
这篇文章指出除了从股票的历史交易数据中产生的各种指标,专业的投资者在选择股票时还会考虑与该股票相关的企业,比如供应商、消费者、股份持有者等,我们应该想办法将这些信息利用起来用于股价预测。那么到了需要建模这种图关系数据的时候,自然就轮到图神经网络出场了。
对于一个图而言,最重要的就是点的表示和边的构建。协相关矩阵被用以建模图中的关联:
e i ˉ = ∑ j N ( ϕ ( W T A i j + b ) d j × e j ) \bar{e_i}=\sum^N_j (\frac{\phi(W^T\mathbb{A}_{ij}+b)}{d_j}\times e_j) eiˉ=j∑N(djϕ(WTAij+b)×ej)
在点的方式方面,作者使用 LSTM 从原始的技术因子中生成结点的 embedding。
e i = RNN ( χ i ) e_i = \text{RNN}(\chi_i) ei=RNN(χi)
论文将企业间的关系分为下面七类。其中第一序列关系(first order)是两个企业间的直接关系,但这种关系是比较稀疏的,并且已经被股票投资者广泛使用了。第二序列关系则是将具有共同特点的两个企业连接起来。

这个公式最重要的改进就是加入了 e i T e j e^T_ie_j eiTej作为系数来表示两个企业之间关系的动态变化。因为两只股票最近在价格上的走势也接近,那么 e i T e j e^T_ie_j eiTej就越大,他们之间的关系也就越强。
论文中使用 Nikkei 225 market 上的 176 只股票,利用Nikkei Value Search dataset来抽取企业之间的关系。利用回报率 R t = p t − p t − 1 p t − 1 R_t = \frac{p_t-p_{t-1}}{p_{t-1}} Rt=pt−1pt−pt−1和夏普率 R t − R f σ \frac{R_t-R_f}{\sigma} σRt−Rf作为衡量指标。实验结果如下图所示。

实验证明了 customer-of 是企业间几种关系中最为重要的一种,对企业股价具有比较好的预测作用。具有这种关系的两家企业的股价在时序上具有比较好的相关性。此外,在不同的时间跨度上,不同的关系对于不同时期股价的预测作用不同。
从上图可以看出,customer-of 关系对于股价的预测作用在 1-day 时是最好的。此外,同一种关系在不同的跳数(hop)上预测作用的时间长短也是不同的,这是一个可以扩展的方向。(其实用模型做价格预测,一个比较普遍的共识是:短期价格变化预测反而不容易准确)
基于图卷积神经网络和公司关系整合的股价预测

论文标题:Incorporating Corporation Relationship via Graph Convolutional Neural Networks for Stock Price Prediction
论文来源:CIKM 2018
论文链接:https://dl.acm.org/doi/10.1145/3269206.3269269
与上篇论文的出发点相似的,这篇论文也将企业间的关系纳入考虑。但与之不同的是,这篇论文更多地将其作为一种数据增强的手段,而不是直接在图上进行股价预测。
文章使用如下方式建图:图中的每个点代表一个企业,他们之间的边代表两家企业间的持股关系,变得权重表示持股比例。之后提出两个模型利用图进行股价预测:Pipeline Prediction Model、Joint Prediction Model Based on GCN。

Pipline Prediction Model 使用 DeepWalk, node2vec 和 LINE 三种方法生成节点的 embedding。之后计算两个结点之间的 cos ( ⋅ ) \cos(\cdot) cos(⋅)相似度选出与目标公司最相似的 N N N家企业,把它们的特征取平均拼接到目标企业的特征向量上:
X X i ′ = ( x x i , t − d ′ , . . . , x x i , t − 2 ′ , x x i , t − 1 ′ ) XX'_i = (xx'_{i,t-d},...,xx'_{i,t-2},xx'_{i,t-1}) XXi′=(xxi,t−d′,...,xxi,t−2′,xxi,t−1′)
最后将 X X i ′ XX'_i XXi′输入到 LSTM 中进行预测:

Joint Prediction Model Based on GCN 则是用 LSTM 获得结点的向量表示,从前面构建的图中获取邻接矩阵,之后输入到一个三层的 GCN 中完成预测:
Y = softmax ( A ^ ReLU ( A ^ ReLU ( A ^ X ′ W ( 0 ) ) W ( 1 ) ) W ( 2 ) ) Y = \text{softmax}(\hat{A}\text{ReLU}(\hat{A}\text{ReLU}(\hat{A}X'W^{(0)})W^{(1)})W^{(2)}) Y=softmax(A^ReLU(A^ReLU(A^X′W(0))W(1))W(2))
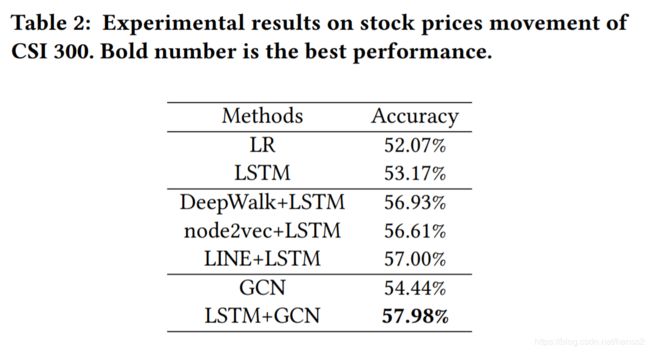
对 2017 年的 CSI 300 的验证结果表明 LSTM+GCN 的预测准确率更高(这里的评价指标选的相当不专业,一般来说我们要选择回报率以及能够排除掉整个市场趋势的一些指标来衡量模型的实际盈利能力)。在所有图表示学习的方法中,LINE 方法的表现更好:
用于股票预测的知识驱动的事件表征
论文标题:Knowledge-Driven Event Embedding for Stock Prediction
论文来源:COLING 2016
论文链接:https://www.aclweb.org/anthology/C16-1201/
在股票市场上,各种 event 对于股价是有较大影响的。这篇文章使用知识图谱来抽取 event embedding,之后用于股价预测。
对于event可以将其看作一个三元组 E = ( A , P , O ) E=(A,P,O) E=(A,P,O),其中 A A A是行动者(actor)或主体(subject), P P P是行动或谓语(predicate), O O O是被施加行为的客体。首先可以使用预训练的词向量做平均来分别表示 A , P , O A,P,O A,P,O,之后使用 neural tensor network (NTN) 来计算隐向量:
S 1 = g ( A , P ) = f ( A T T 1 1 : k P + W [ A P ] + b ) S_1 = g(A,P) = f(A^TT_1^{1:k}P + W \left[\begin{array}{c} A \\ P \end{array} \right] +b) S1=g(A,P)=f(ATT11:kP+W[AP]+b)
为了合理的训练,采用随机替换A中单词的方式来获得负样本(corrupted event tuple) E r = ( A r , P , O ) E^r = (A^r,P,O) Er=(Ar,P,O),损失函数如下:
L E = loss ( E , E r ) = max ( 0 , 1 − g ( E ) + g ( E r ) ) + λ ∣ ∣ Φ ∣ ∣ 2 2 L_E = \text{loss}(E,E^r)=\text{max}(0,1-g(E)+g(E^r))+\lambda||\Phi||^2_2 LE=loss(E,Er)=max(0,1−g(E)+g(Er))+λ∣∣Φ∣∣22

但上述方式训练出的 event embedding 存在两个的问题:
- 不能获取两个在语义或语法上相似事件的关系,如果两者没有相似的词向量;
- 同样地,有两个相似词向量的事件不一定是相关的。
这两个问题出现的原因是在训练 event embedding 的时候没有加入背景知识。而想要获取背景知识就要利用知识图谱,知识图谱中存在两种知识:关系知识(relational knowledge)和类别知识(categorical knowledge)。
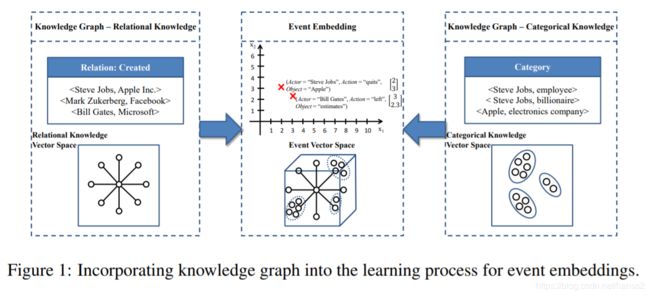
这两种关系同样可以使用简单的 NTN 网络来计算,其中 e 1 , e 2 e_1,e_2 e1,e2是两个实体, R R R是某种关系:
g ( e 1 , R , e 2 ) = μ R T f ( e 1 T H R [ 1 : k ] e 2 + V R [ e 1 e 2 ] + b R ) g(e_1,R,e_2) = \mu^T_R f(e^T_1H^{[1:k]}_Re_2 + V_R\left[\begin{array}{c} e_1 \\ e_2 \end{array} \right] +b_R ) g(e1,R,e2)=μRTf(e1THR[1:k]e2+VR[e1e2]+bR)
通过随机替换 e 2 ( i ) e^{(i)}_2 e2(i)获得负样本 e c ( i ) e^{(i)}_c ec(i),极小化如下的目标函数:
L k = ∑ i = i N ∑ m = 1 M max ( 0 , 1 − g ( T ( i ) ) + g ( T c ( i ) ) ) + λ ∣ ∣ Ω ∣ ∣ 2 2 L_{\mathcal{k}} = \sum^N_{i=i} \sum^M_{m=1} \text{max}(0,1-g(T^{(i)})+g(T^{(i)}_c))+\lambda||\Omega||^2_2 Lk=i=i∑Nm=1∑Mmax(0,1−g(T(i))+g(Tc(i)))+λ∣∣Ω∣∣22
最后将两个模型组合起来进行训练,就可以获得包含知识的event embedding。

目标函数为:
L = α L ϵ + ( 1 − α ) L k L = \alpha L\epsilon+ (1-\alpha)L_{\mathcal{k}} L=αLϵ+(1−α)Lk
实验从 Reuters News 和 Bloomberg News 抽取结构化事件,使用 YAGO 作为知识图谱,对标准普尔 500 指数和单个股票进行预测。使用Acc和MCC(Matthews Correlation Cofficient) 作为指标。结果如下:

总结
这三篇论文是近五年图神经网络和知识图谱在量化投资上的应用尝试,主要集中与挖掘企业之间的相关关系,但也存在一些问题,如三篇文章都没有很好的解决市场的动态性,企业间的关系是随时间不断变动的,并且使用一个静态的知识图谱或数据集来抽取关系是否会造成数据泄露的问题也没有指明。
因为相关的资料确实相当匮乏,原作者在 GitHub 上新建了一个 repo 用于收集、整理相关的研究论文、书籍、数据、网站等,欢迎 star:https://github.com/sangyx/deep-stock