论文从理论的角度出发,对目标检测的域自适应问题进行了深入的研究,基于H-divergence的对抗训练提出了DA Faster R-CNN,从图片级和实例级两种角度进行域对齐,并且加入一致性正则化来学习域不变的RPN。从实验来看,论文的方法十分有效,这是一个很符合实际需求的研究,能解决现实中场景多样,训练数据标注有限的情况。
来源:晓飞的算法工程笔记 公众号
论文: Domain Adaptive Faster R-CNN for Object Detection in the Wild

Introduction
目前,目标检测算法在公开数据上有很好的表现,但在现实世界环境中通常会有许多特殊的挑战,比如视角、物体外观、背景、光照以及图片质量的不同,使得测试数据和训练数据存在较大的跨偏移问题。

以自动驾驶为例,不同的公开数据集里的图片存在较大的差异,域偏移问题会导致明显的检测器性能下降。尽管收集更多的训练图片能解决域偏移的影响,但显然这不是最好的方案。
为了解决上面的问题,论文提出Domain Adaptive Faster R-CNN,最小化图片级别域偏移(图片尺寸、图片风格、光照等)以及实例级域偏移(目标外表、目标尺寸等),每个模块学习一个域分类器并且通过对抗训练学习域不变的特征,并且加入分类器的一致性正则化来保证RPN学习到域不变的proposal。
论文的主要贡献如下:
- 从概率角度对跨域目标检测中的域偏移问题进行理论分析。
- 设计了两个域自适应模块来消除图片级别和实例级别的域差异。
- 提出一致性正则化来学习域不变RPN。
- 将提出的模块集成到Faster R-CNN中,进行端到端的训练。
Distribution Alignment with H-divergence
论文设计了H-divergence度量两个不同分布的样本集,定义$x$为特征向量,$x_{\mathcal{S}}$为源域样本$x_{\mathcal{T}}$为目标域样本,$h:x\to \{0,1\}$为域分类器,预测源域样本$x_{\mathcal{S}}$为0,预测目标域样本$x_{\mathcal{T}}$为1。假设$\mathcal{H}$为一组域分类器,则H-divergence的定义为:
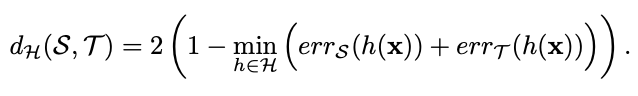
$err_{\mathcal{S}}$和$err_{\mathcal{T}}$为$h(x)$在源域和目标域样本的预测误差,上述的公式意味着域距离$d_{\mathcal{H}}(\mathcal{S},\mathcal{T})$与域分类器的错误率成反比,若最好的域分类器的错误率越高,则源域和目标域的距离越近。
在神经网络中,定义网络$f$产生特征向量$x$,为了进行域对齐,需要网络$f$产生能够减小域距离$d_{\mathcal{H}}(\mathcal{S},\mathcal{T})$的特征向量,即最小化公式:

上述的公式可以通过对抗训练进行优化,论文采用gradient reverse
layer(GRL)进行实现,训练主干特征最大化域分类误差并且训练域分类器最小域分类误差进行对抗训练,最终得出鲁棒的特征。
Domain Adaptation for Object Detection
A Probabilistic Perspective
目标检测问题可表示为后验概率$P(C, B|I)$,$I$为图片,$B$为目标的bbox,$C\in \{1,\cdots,K\}$为目标类别。定义目标检测的样本的联合分布为$P(C,B,I)$,其中源域和目标域的分布是不一样的$P_{\mathcal{S}}(C,B,I) \neq P_{\mathcal{T}}(C,B,I)$
Image-Level Adaptation
根据贝叶斯公式,目标检测的联合分布可定义为

定义目标检测为covariate shift假设,设定域间的条件概率$P(C, B|I)$是一样的,域分布偏移主要来自于$P(I)$分布的不同。在Faster R-CNN中,$P(I)$即从图片提取的特征,所以要解决域偏移问题,就要控制$P_{\mathcal{S}}(I)=P_{\mathcal{T}}(I)$,保证不同域的图片提取的特征一致。
Instance-Level Adaptation
另一方面,目标检测的联合分布也可以定义为
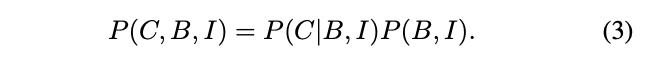
基于covariate shift假设,设定域间的条件概率$P(C|B,I)$是一样的,域分布偏移主要来自于$P(B,I)$分布的不同,而$P(B,I)$即图像中bbox区域特征,所以为了解决域偏移问题,需要控制$P_{\mathcal{S}}(B,I)=P_{\mathcal{T}}(B,I)$,保证不同域的图片提取的相同目标的bbox特征不变。
需要注意的是,目标域是没有标注信息的,只能通过$P(B,I)=P(B|I)P(I)$获取,$P(B|I)$为bbox预测器,这样就需要RPN具备域不变性,为此,论文再添加了Joint Adaptation。
Joint Adaptation
考虑到$P(B,I)=P(B|I)P(I)$,而分布$P(B|I)$是域不变且非零的,因此有
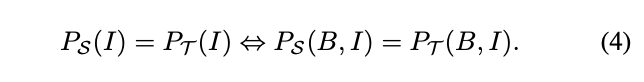
若域间的图片级特征的分布是一样的,实例级特征的分布也应该是一样的。但实际中很难达到完美的$P(B|I)$,首先$P(I)$分布很难完美地对齐,导致$P(B|I)$的输入有偏,其次bbox是从源域学习而来的,会存在一定地偏差。
为此,论文使用一致性正则化来消除$P(B|I)$的偏置,使用域分类器$h(x)$来进行源域和目标域的判断。定义域标签为$D$,图像级分类器可看为预测$P(D|I)$,实例级的分类器可看为预测$P(D|B,I)$。根据贝叶斯理论,得到

其中,$P(B|I)$是域不变的bbox预测器,而$P(B|D,I)$为域相关的bbox预测器。由于目标域没有标注的bbox,所以实际仅学习到域相关的bbox预测器$P(B|D,I)$。但可以通过强制两种分类器的一致性$P(D|B,I)=P(D|I)$,使得$P(B|D,I)$逼近$P(B|I)$。
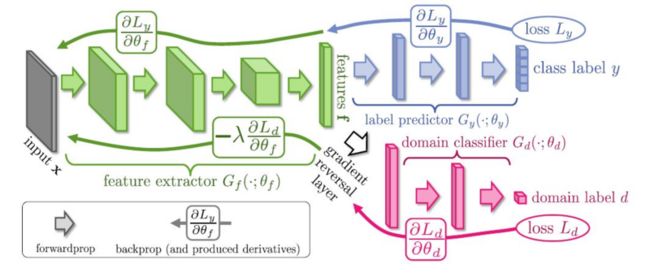
Domain Adaptation Components
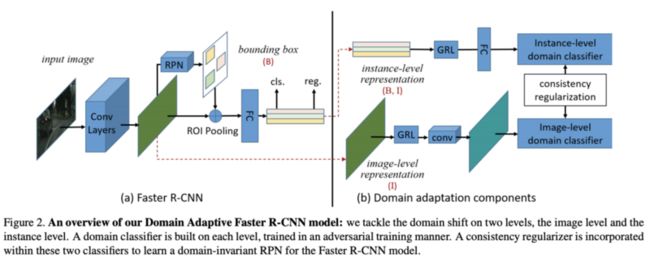
DA Faster R-CNN的架构如图2所示,包含两个域自适应模块以及一致性正则化模块,自适应模块加入GRL(gradient reverse layer)进行对抗训练,每个模块包含一个域分类器,最终的损失函数为
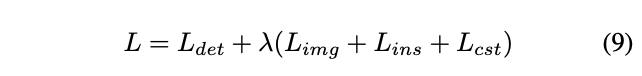
Image-Level Adaptation
为了消除图片级域分布不匹配,使用patch-based域分类器对特征图的每个特征点进行分类,每个特征点实际对应原图的一片区域$I_i$,这样特征点域分类器就等同于预测了每个图像中每个patch的域标签,这样的好处在于:
- 图片级表达的对齐通常能有助于消除整图带来的偏移。
- 由于目标检测算法的batch size通常很小,path-based能够提高域分类器的训练样本数。
定义$D_i$为第$i$个训练图片的域标签,$\phi_{u,v}(I_i)$为特征图上的一个激活值,$p^{(u,v)}_i$为域分类器的一个输出,则图片级自适应损失为

为了对齐域分布,需要同时优化域分类器最小化域分类损失以及优化主干网络的参数最大化域分类损失进行对抗训练,论文采用GRL进行实现,使用梯度下降来训练域分类器,回传梯度给主干时将梯度置为反符号。
Instance-Level Adaptation
实例级特征对齐有助于减少实例的局部差异,比如外表,大小,视角等。跟图片级特征对齐类似,定义$p_{i,j}$为第$i$个图片的第$j$个proposal,实例级的自适应损失为
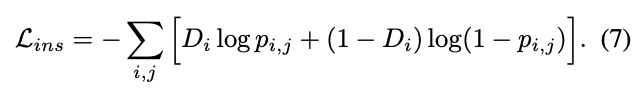
同样的,在域分类器前添加GRL模块进行对抗训练。
Consistency Regularization
如前面的分析,强制域分类器的一致性有助于学习鲁棒的跨域bbox预测器,加入一致性正则化。由于图片级域分类器是对特征值进行分类的,取平均输出作为图片级概率,一致性正则化为
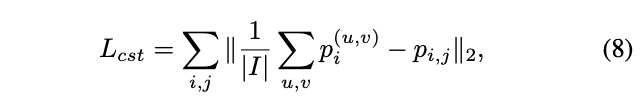
其中$|I|$为特征图的点数,$||\cdot||$为$\mathcal{l}_2$距离。
Experiments
Learning from Synthetic Data
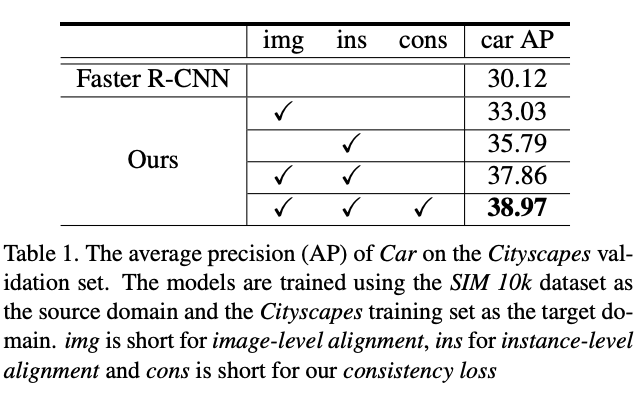
SIM 10k是从GTAV中截取画面进行标注的数据集,Cityscapes为真实图片,这里对比从生成图片到真实图片的域转移。
Driving in Adverse Weather
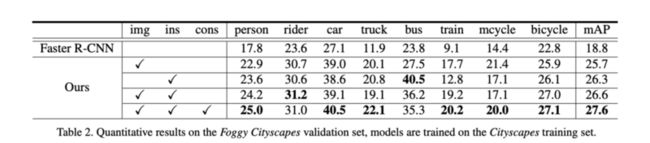
Foggy Cityscapes通过生成雾来模拟真实场景,这里对比天气带来的域转移。
Cross Camera Adaptation
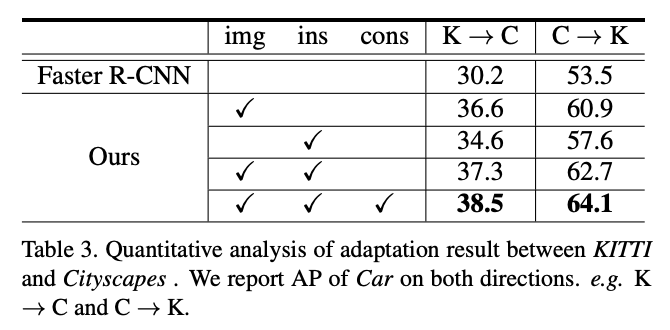
这里对比两个不同的训练数据集的域对齐。
Error Analysis on Top Ranked Detections

每个模块都能提升一定的准确率,而图片级对齐的背景错误率较高,这可能由于图片级对齐对RPN的提升更直接。
Image-level v.s. Instance-level Alignment
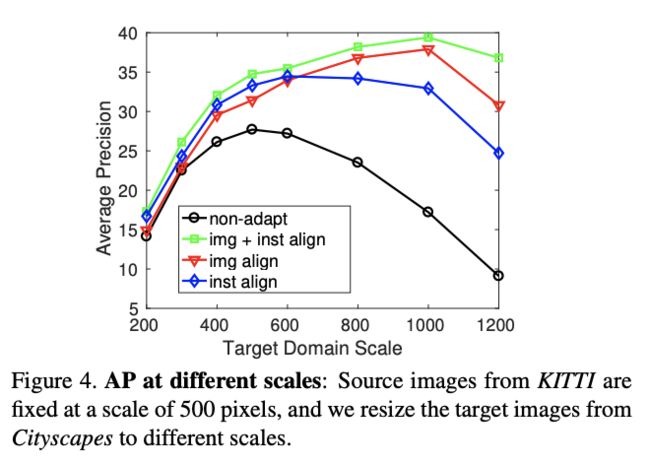
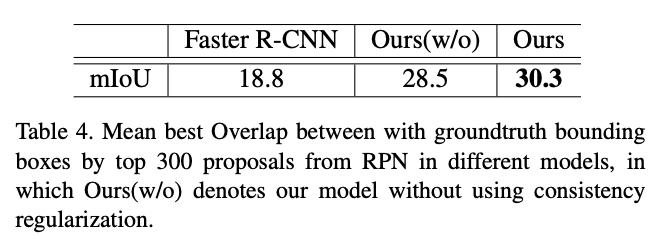
Consistency Regularization
CONCLUSION
论文从理论的角度出发,对目标检测的域自适应问题进行了深入的研究,基于H-divergence的对抗训练提出了DA Faster R-CNN,从图片级和实例级两种角度进行域对齐,并且加入一致性正则化来学习域不变的RPN。从实验来看,论文的方法十分有效,这是一个很符合实际需求的研究,能解决现实中场景多样,训练数据标注有限的情况。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
