CNCC 2018技术论坛——知识图谱赋能数字经济
本周五报名参加了在杭州举办的CNCC 2018大会,听取了关于知识图谱的技术论坛——知识图谱赋能数字经济。共有6位专家讲者带来了精彩的主题报告,以及一个小时的Panel环节。本博客将整理总结分享专家的报告,供大家参考。
1、周傲英:数据是催生数字经济的新动能——兼谈知识图谱的作用
数字经济是什么?新动能是什么?
数字经济最早在20年前提出,代表的是数字化,2016年G20峰会上,数字经济被再次提出,数字经济发展的根本是互联网。数字经济是一种新的经济形态,数字经济的基本特征有3点:
- 以数据资源为重要生产要素,以现代信息网络为主要载体;
- 以信息通信技术融合应用,全要素数字化转型为推动力;
- 促进公平与效率更加统一。
具体解释是:同农业经济时代中农药、化肥、种子,工业时代中厂房、石油、机器是生产必不可少的要素一样,在数字经济时代,数据是最重要的生产要素。现代信息网络就是指互联网,即数字经济发生在互联网上。融合应用指“互联网+”,传统行业与互联网合二为一,融合的推动力是全部要素的数字化。
数字经济将带来重大的时代转型:生产方式变革,生产关系再造,经济结构重组,生活方式巨变。
农 业 经 济 ⟶ 工 业 经 济 ⟶ 数 字 经 济 农业经济\longrightarrow工业经济\longrightarrow数字经济 农业经济⟶工业经济⟶数字经济
与数字经济密切相关的是“互联网+”,互联网“+”传统经济=数字经济。“+”表示融入与引领,更表示升级换代,创新发展,互联网是传统经济的画龙点睛之笔。因此,“互联网+”(Internet Plus)的真正含义是转型(Paradigm Shift),代表着换套路,包括思维方式的改变以及由此带来的业务逻辑的改变。
这里面最本质的是互联网,如今互联网已经深刻地改变世界。互联网为什么能改变世界,首先是因为互联网改变了人与人之间的关系:1)人和人之间的连接方式(people connection),anyone, anywhen, anywhere; 2)注重用户体验(user experience);3)行为数据在线收集和使用(behavior data),互联网的主要特征是免费,免费使用的背后是个人数据的不断收集,这些数据其实就是个人隐私,正如李彦宏所说:“中国人愿意用自己的隐私换取服务的便利”,可以说我们用我们的隐私数据换取了互联网的蓬勃发展。人是社会关系的总和,人和人之间的关系变了,人就变了,世界也就变了。其次是互联网契合了人性最本质的述求——平等,有了平等就会有民主(徳先生),同时用数据用算法说话,就有了科学(赛先生)。最后,互联网对中国意味着重要机遇,我们有中国梦的内因以及全球化的外因。
互联网企业靠互联网经济赚钱,从最开始的流量变现,粉丝(眼球)经济,到数据变现,靠精准广告/营销/推荐,往后将是分享经济(租赁经济,节俭经济),是互联网应该推从的,是互联网经济的下半场。互联网时代做的是连接,以打破信息不对称为幌子造就了更大的信息不对称,因此,下一步要做的是去中心化。总结互联网的发展脉络如下:
互联网—>大数据—>互联网+ —>创业创新—>供给侧改革—>分享经济—>人工智能—>区块链
分享经济最典型的是共享单车,分享经济的要旨是盘活闲置的资源,提高效率,是市场经济和人类文明的高级阶段。目前文明还没达到这个高度,需要发展新技术来建立信任,区块链的作用就在此。
大数据是将数据汇集、关联、使用起来,与数据大小关系不大,大数据是说数据很重要,其重要程度堪比引发第二次工业革命的交流电。互联网时代讲大数据是因为互联网真正将数据用起来了,互联网企业本质是大数据企业。数据是新动能(new power),是催生数字经济的新动能。知识图谱是非结构化数据处理的有效手段,把数据变成知识最终形成智慧,推动数字经济向纵深发展。
2、周国栋——语言理解与知识图谱
知识图谱/语言理解是实现数字经济必不可少的一种机制或工具,认知科学的关键是解决语言机制问题,自然语言理解是人工智能皇冠上的明珠,同时也是实现人工智能的拦路虎。人工智能发展三个阶段中的前两个阶段:计算智能(能存会写)、感知智能(能听会说,能看会认)已经基本实现,但第三个阶段认知智能(能理解会思考)还很遥远。要解决这个问题需要我们对人类的认知有一定的了解,而自然语言是我们窥探认知的很好的突破口。自然语言是人类思维和交际的一个符号系统,是一个并行的音形义相结合的结构系统,是人类对现实世界的认知反应。包含三方面的东西:1)语言是有结构的,乔姆斯基语言体系,目前我们还只是实现了乔姆斯基语言体系最简单的。2)语言是声音、形式和意义相结合的符号系统,有时用声音代表语义(香菇代表想哭),有时用形状代表语义(囧),以上两点形式主义语言学研究比较多。3)语言是人类最重要的交际工具和信息载体,即考虑语言的功能与用途,代表是功能主义语言学。4)语言是人类对现实世界认知的结果,是认知过程的产物。
自然语言理解的根本任务是篇章理解,自然语言由字、词、短语由下到上逐层构造而成,自然语言理解是一个非常困难的过程,为了解决这个问题,可以将自然语言理解分为三个阶段:词汇级、句子级和篇章级,主要工作分别对应结构解析、浅层语义解析和深层语用理解。人类理解自然语言通常是在篇章级进行的,即不能断章取义。目前篇章理解才刚刚入门,目前研究比较多的是连贯性和衔接性,连贯性即上下文是否通顺,逻辑上是否满足层次结构;衔接性即信息(事情1,事情2……)是否能衔接上,解决这两点的关键是弄清楚文章的结构。另一个研究比较多的是跨篇章性,跨篇章性指我们在弄清楚文章表面意思、逻辑结构后,理解文章需要一些背景知识,这时就需要知识图谱(概念、实体及其关系)。连贯性、衔接性和跨篇章性大体上从形式上理解了文章的信息。但理解文章的意图还需要有语境(情景),这时就需要情景图谱,文章被不同文化的人接受则还需要文化图谱。
知识图谱是跨篇章信息的一种有效组织方式,深层意思的理解需要知识图谱,需要场景,需要领域知识(domain knowledge)。除了传统的实体-实体之间的关系,还需要事件知识图谱,甚至更抽象的场景图谱。
自然语言理解和知识图谱就像一对孪生兄弟,彼此相互需要,相互促进。
3、唐杰——Representation Learning for Big Network
知识图谱是用图模型建模知识,对图的挖掘与分析能够发现图中的隐藏知识,图嵌入(graph embedding),图卷积等表示学习是目前最火热的图挖掘、图计算手段,被广泛应用于知识图谱的分析。唐杰教授今天的报告就是关于大规模网络表示学习的进展。
从大规模网络数据中学出节点、边、子图的表示
互联网上用户以及用户行为形成了一个大规模的社交网络,网络中每个节点代表一个个体/实体,个体/实体之间有一种/多种相关性,比如好友关系,构成了网络的边。网络可以看作是静态图也可以看作是动态图,动态图考虑用户之间的交互构成的边,比如互发消息,随着时间的推移,这种边有时有有时没有。有了这种大规模的网络之后,希望从中能够挖掘一些pattern,然后用这些pattern做一些预测等。
社交网络可以从两个维度进行分析,一个是社交的角度,分别从网络中用户、关系(边)、结构展开研究;另一个是数据的角度,体现在数据的规模,数据的高度动态、流式数据(stream data)、异构,既有用户也有实体。网络中有三方面的东西要做表示学习:一是节点,怎么学出节点的低维映射,希望label相同的节点能够距离比较近,label不同的节点距离比较远;同样边和子图(subgraph)也要做表示学习。
表示学习最具代表性的是word2vec,对每一个单词学习一个表示。文本中单词最简单的表示是采用词袋模型(bag-of-words)将单词表示成一个高维向量(词汇表大小维),然后从高维向量做一个低维映射。回到网络的表示学习,最首要任务是建立网络节点的Context,最简单的是采用一度邻居,但是这会造成Context的不平衡,比如:微博大V的粉丝非常的多,但普通人的粉丝则比较的少。为了解决这个问题,KDD 2014年一篇文章提出了DeepWalk,从任意一个节点进行随机游走(random walk),这样就保证了每个节点的Context规模是一样的,剩下的工作就和word2vec类似。之后在此基础上,LINE算法引入了二阶相似度,PTE算法将异构网络和有监督信息结合进来,Node2vec算法则更好的考虑了网络中节点的关系,如朋友的朋友是朋友,以及朋友的朋友不是朋友。
那这些方法背后的本质是什么呢?我们能不能设置一个unify的方法把这些方法都统一起来。分析得到所有的方法都可以统一为矩阵的形式,结论如下:(具体分析在这里就不展开了,可以参考唐杰教授发表在WSDM 2018上的论文Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec)
| Algorithm | Matrix |
|---|---|
| DeepWalk | log ( v o l ( G ) ( 1 T ∑ r = 1 T ( D − 1 A ) r D − 1 ) − log b \log\Big(vol(G)\big(\frac{1}{T}\sum_{r=1}^T(D^{-1}A)^rD^{-1}\Big)-\log b log(vol(G)(T1∑r=1T(D−1A)rD−1)−logb |
| LINE | log ( v o l ( G ) D − 1 A D − 1 ) − log b \log(vol(G)D^{-1}AD^{-1})-\log b log(vol(G)D−1AD−1)−logb |
| PTE | log ( [ α v o l ( G w w ) ( D r o w w w ) − 1 A w w ( D c o l w w ) − 1 β v o l ( G d w ) ( D r o w d w ) − 1 A d w ( D c o l d w ) − 1 γ v o l ( G l w ) ( D r o w l w ) − 1 A l w ( D c o l l w ) − 1 ] ) − log b \log\Bigg(\begin{bmatrix}\alpha\: vol(G_{ww})(D_{row}^{ww})^{-1}A_{ww}(D_{col}^{ww})^{-1}\\ \beta\: vol(G_{dw})(D_{row}^{dw})^{-1}A_{dw}(D_{col}^{dw})^{-1}\\ \gamma\: vol(G_{lw})(D_{row}^{lw})^{-1}A_{lw}(D_{col}^{lw})^{-1}\\\end{bmatrix}\Bigg)-\log b log(⎣⎡αvol(Gww)(Drowww)−1Aww(Dcolww)−1βvol(Gdw)(Drowdw)−1Adw(Dcoldw)−1γvol(Glw)(Drowlw)−1Alw(Dcollw)−1⎦⎤)−logb |
| node2vec | log ( 1 2 T ∑ r = 1 T ( ∑ u X w , u P ‾ c , w , u r + ∑ u X c , u P ‾ w , c , u r ) ( ∑ u X w , u ) ( ∑ u X c , u ) ) − log b \log\Big(\frac{\frac{1}{2T}\sum_{r=1}^T(\sum_uX_{w,u}\underline{P}_{c,w,u}^r+\sum_uX_{c,u}\underline{P}_{w,c,u}^r)}{(\sum_uX_{w,u})(\sum_uX_{c,u})}\Big)-\log b log((∑uXw,u)(∑uXc,u)2T1∑r=1T(∑uXw,uPc,w,ur+∑uXc,uPw,c,ur))−logb |
表格中,左边是算法,右边是归一化的结果, log b \log b logb是一个标量,可以省略,因此所有的方法都在做矩阵分解,有了统一的矩阵形式,就可以设计一个unify的framework,做一个矩阵分解,所有的问题就都解决了。

用学出的表示做用户行为预测
为了测试模型在实际应用中的性能,模型被应用到了工业界数据的商品推荐中。在做商品推荐中,有一个Social Influence的概念:用户与用户之间存在影响力。因此对用户行为进行预测时需要考虑用户形成的网络,比如下面这幅图中预测 V 1 V_1 V1, V 2 V_2 V2是否会购买iPhone XS
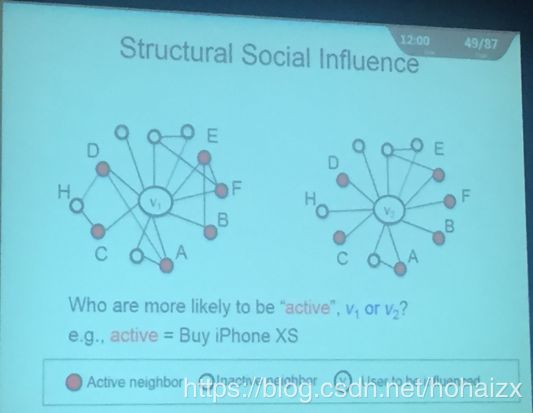
实际 V 2 V_2 V2买iPhone XS的概率要高于 V 1 V_1 V1,为什么呢? V 1 V_1 V1和 V 2 V_2 V2的区别在于, V 1 V_1 V1中多了几条边 B E BE BE, E F EF EF, A D AD AD,因此可以感性的解释:如果我们的六个朋友都购买了iPhone XS,并且他们互相不认识,从认知的角度上说,如果我们的大学同学、高中同学、初中同学、家人等都买了iPhone XS,那么我们很大程度上也会购买。在进入用户行为预测时,传统方法都会定义很多特征,特征选取的好坏会很大程度上决定模型的性能,解决这个问题的一个办法是将表示学习结合起来(具体见唐杰教授发表在KDD 2018上的论文DeepInf: Social Influence Prediction with Deep Learning):
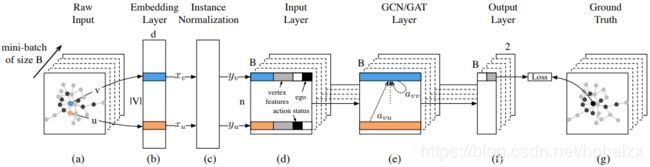
首先对拿到的网络进行表示学习,如蓝色所示,然后进行归一化,避免overfitting,接着就可以输入预测模型中,当然在具体应用中可以加一些工业界常用的特征,如:性别,年龄,最后做一个Convolution,实验结果在多个数据集上都有5%~10%的提高。模型也实际应用到了腾讯DNF,QQ飞车,王者荣耀等游戏的道具推荐上,点击率都有100%+的提升。
将用户反馈结合到网络中
在真实应用中,用户会给很多反馈,怎么从用户反馈中学习?因为大部分学习场景中标注数据往往不够,如用户喜不喜欢某个商品,这种问题通常是一个cold start(冷启动)的问题。在网站上设置一个机器人,向用户提出一些问题(用户不需要回答,只需要点赞或者叉掉),用以获得用户的反馈,该问题可以看作是一个计算问题:在什么时候对谁应该问什么问题。于是在NIPS 2018上唐杰教授发表了论文Bandit Learning with Implicit Feedback,定义了一个Examination-click bandit model。
虎嵩林——知识驱动的互联网变革
主要从系统的角度简述了知识在系统发展中扮演的角色,以及知识图谱在落地中的问题与尝试。
从互联网每天几十PB的数据,到移动互联网每天TB级的视频图像数据,到现在大热的物联网,数据规模一直在快速增长。数据规模的增长也会促进计算体系的变化,最早的计算结构是计算机+数据+算法在单机上构成了比较合理的程序,随着数据不断增加,需要越来越多的分布式计算能力,cluster开始扮演越来越重要的角色,可以认为cluster替代了计算机,另一方面对数据的管理也提出了更高的要求,在这个时期,对元数据给与了更大的重视,计算结构成为cluster+数据+元数据+算法。再后来,cluster也逐渐不能满足快速增长的数据要求,cloud开始大热,对元数据的管理也开始向语义、知识靠拢,算法上深度学习等开始流行,计算结构变成cloud+数据+元数据+算法。
而知识图谱的发展与重视,主要是机器学习存在的一些问题:1)深陷概率关联的泥潭而忽视了因果;2)缺背景、缺常识、缺推理,数据已经无法满足我们对外提供服务的需求,因此在算力和算法的支持下存在新动能的切换,即从数据驱动到知识驱动。有了知识,知识会对经济产生什么作用?价值增长点在哪里?不仅是是互联网改变人类的生活方式,更大的价值可能是对人类生产效率的提升。
当然,知识图谱在落地过程中也还存在一些问题,从技术的角度,知识图谱的构建过程可以分为:知识表示,知识抽取,知识融合,知识推理。在知识表示中,各种异构的知识如何表示:如图结构、生成式规则、流程等。知识抽取中,如何把社交、事件、实体等关系联合抽取。知识融合中,如何与现有的知识、规则融合。知识推理中,混合推理,多时态推理如何进行。
王昊奋——从人工智能到开放知识图谱:数字经济大潮下的新机遇
主要汇报OpenKG的一些工作。
知识图谱是工业界提出的一个概念,本质是大数据驱动下的知识工程的重述。伴随着AI的起起伏伏,知识图谱的发展也经历了以下阶段:

从50年代到70年代,主要是符号逻辑、神经网络和产生式规则;从70年代到90年代,是专家系统,以及以知识库+推理=智能而诞生的很多伟大系统;90年代初,万维网开始慢慢的孕育,产生了很多人工构建的知识库,本体也有哲学概念发展到计算机概念;2000年以后,伴随着互联网的快速发展,语义网开始慢慢成长,诞生了群智的代表维基百科;2006年之后,因为各种技术的成熟,大数据的出现,算力的提升,算法的提升,出现了各种人机协同的高质量知识库,以及以此为基础的应用。可以看见知识图谱的出现不是一蹴而就,而是多学科的融合,包括知识表示,自然语言处理,web,AI等各个方面。
在数字经济中知识图谱的主要应用是:KG辅助搜索KG4SEO,KG辅助问答KG4BOTS,KG辅助决策。因为深度学习的火热,深度学习常被用来和知识图谱比较,两者分别代表”术“和”数“。深度学习其实是一种归纳学习,对应于聪明的人,更多解决的是感知,识别,判断的问题;对于很多其他任务,通常是数据/知识驱动的,需要考虑机器是否足够知识渊博,更多关注的是认知智能时代的思考、语言和推理,这更多需要知识图谱带来的红利,因此,两者是相辅相成的。
接下来更多介绍的是OpenKG的一些东西,OpenKG=中文+开放+知识图谱,希望推动构建以中文为核心的最具影响力的开放域知识图谱。OpenKG 1.0的主要工作是收集各种各样的数据,收集各种各样的工具,形成很多的成员。但要建一个知识图谱,要怎么做还是不清楚,因此在OpenKG 2.0,形成了以下几件事情:1)cnSchema,是schema.org的一个同步版,同时包括一些微创新,提供可供参考的扩展的数据描述和接口定义标准;2)OpenBase,知识图谱众包平台,基于cnSchema和积累的工具、数据、粗知识等,通过众包机制形成细知识;3)OpenBot,图谱转化为对话机器人的平台工具。
加入Openbase成为贡献者或者了解更多关于Openbase的信息,可以参考其官网Openbase。