论文阅读笔记-ClusType: Effective Entity Recognition and Typing by Relation Phrase-Based Clustering
作者
Xiang Ren, Ahmed El-Kishky, Chi Wang, Fangbo Tao, Clare R. Voss, Heng Ji, Jiawei Han
单位
University of Illinois at Urbana-Champaign,
Microsoft Research, Redmond,
Rensselaer Polytechnic Institute,
Army Research Laboratory, Adelphi
关键词
Entity Recognition and Typing,
Relation Phrase Clustering
文章来源
KDD, 2015
问题
远程监督方法在特定领域的实体抽取方面存在领域扩展性差、实体歧义问题以及上下文稀缺三大问题,本文主要研究如何改进这三个问题。
模型
针对上述的三个问题,本文提出了各自对应的解决思路:只使用浅层的分析方法例如POS等解决领域独立性问题;对entity mention(token span in the text document which refers to a real-world entity)应用词形和上下文联合建模来解决歧义问题;挖掘relation phrase和entity mention的共现情况,利用relation phrase前后实体(主语和宾语)的类别来找到相同的关系,进而辅助实体类型的推断。基于上述的思路,本文提出了ClusType的方法。
ClusType的问题定义如下:给定一个特定领域的文档集合,一个实体类型集合以及一个知识库,主要完成三个任务:第一,从文档集合中抽取出候选的entity mention集合;第二,将一部分entity mention链接到知识库,作为种子entity mention集合;第三,对于剩余未完成知识链接的entity mention集合,预测每一个entity mention的对应实体类别。
根据任务的定义,整个框架也分为三个部分,分别解决这三个任务。
本文方案的具体思路如下:
1、构建关系图
关系图的基本样式如下:
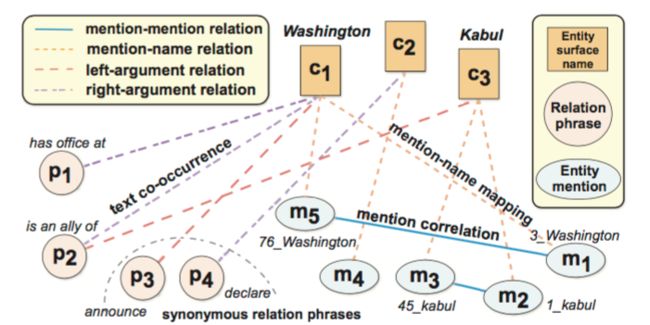
图当中的节点主要分为三种:entity mention, surface name, relation phrase.
图中的边的类型也有三种:entity mention和surface name的关系、surface name和relation phrase在语料中的共现情况、entity mention和entity mention的关系,表现entity mention之间的相似程度。这三个关系均是通过邻接矩阵的形式表示。
关于三种要素的确定,relation phrase的确定主要参考开放域抽取的方法,entity mention的确定方法也比较简单:首先找到固定长度的一个频繁词串集;为集合中每一个词串计算两两之间的得分,得分越高证明越需要合并;在合并的过程中,利用贪心算法,从得分最高开始合并,直到所有得分均低于某一阈值。
2、种子集合的生成
这里利用了dbpedia-spotlight工具进行entity mention到知识库的映射,只选取置信度得分高于0.8的作为有效输出。
3、实体类型推断
目标函数如下:

公式共分为三部分:
第一部分遵循实体关系共现假设:如果一个surface name经常在relation phrase前后出现,那么它的类型应该同relation phrase前后实体的类型相关。
第二部分遵循两个假设。
假设一:如果两个relation phrase相似,那么他们前后实体的类型也应该相似;
假设二:判断两个relation phrase相似的特征为词形、上下文和其前后实体的类型。
因此,第二部分的作用在于根据两个假设建模一个基于joint non-negative matrix factorization的multi-view clustering.
第三部分就是建模entity mention对应实体类别、entity mention之间的关系以及引入种子集合的监督,利用一个entity mention的surface name和relation phrase对应的关系类别推断关系类型,同时考虑到相似entity mention的一致性以及对于种子集合的预测误差函数。
相关工作
本文主要借鉴两方面的工作,一部分是远距离监督的方法,另一部分是开放关系抽取。
远距离监督的工作主要有:
1、N. Nakashole, T. Tylenda, and G. Weikum. Fine-grained semantic typing of emerging entities. In ACL, 2013.
2、T. Lin, O. Etzioni, et al. No noun phrase left behind: de- tecting and typing unlinkable entities. In EMNLP, 2012.
3、X. Ling and D. S. Weld. Fine-grained entity recognition. In AAAI, 2012.
开放关系抽取的工作主要有:
1、A. Fader, S. Soderland, and O. Etzioni. Identifying relations for open information extraction. In EMNLP, 2011.
简评
本文通过对于远程监督方法的缺陷分析,提出了一种基于关系短语的实体识别方法。同时,还提出了一个领域无关的生成relation phrase和entity mention。通过将关系短语的聚类和实体类型的识别联合建模,可以在解决实体歧义和上下文问题上发挥很大的作用,而且可以根据entity mention的surface name和relation phrase预测关系类型。同时,我个人认为,将实体识别和关系识别进行联合建模可以起到一个相互促进的作用,而且可以很好的避免在这两个任务当中引入深度语法分析的工具如依存、句法分析等,减少误差积累和领域依赖性。未来两种任务结合依旧是一个很好的研究方向和热点。