最近真的好累啊,心累,很多事想快点做完,但是每个人都有拖延症,叠加到我这一层都不知道拖延到什么时候了。好多事总想着要是可以我自己全部搞定就好了。为什么有些人就是不能早定启动计划呢?心累。

写代码吧,这是唯一能“消遣”的方式了。
看到传智播客课件上有给学员留一些爬虫作业,嘿嘿,自己决定做做看。
今天做 “爬取拉勾网爬虫工程师职位”。
更新:元旦快乐!元旦终于能过个双休,好好陪姐姐和麻麻,顺便学学爬虫吧(▽)
第一次爬动态页面,一时不知道该怎么下手,好在拉勾是爬虫工程师常用来练手的地方,攻略挺多,哈哈。整体思路如下:
- 构造并获取请求
- 解析所需要的数据
- 以Excel形式保存在本地。
1.构造并获取请求:
由于拉勾采用异步加载技术,之前用的很简单的获取静态页面的方式就不行了。需要通过抓包获得数据包,再从数据包里解析所需要的数据。
打开拉勾网,查找关键字“爬虫工程师”,打开谷歌浏览器贤者模式-network,如下:
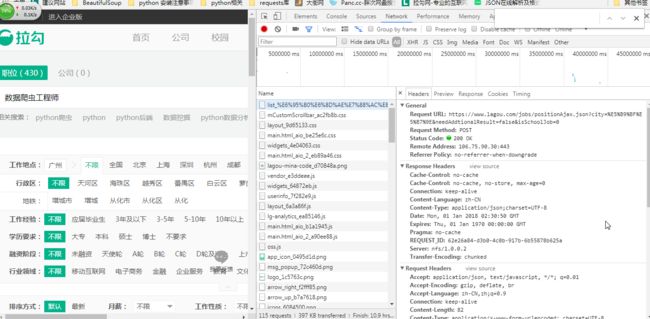
监听器中看到的数据有很多,css, png, js......我们需要的数据包均不在以上列出来的类型里,我们的关注点主要是在xhr类型的文件中,关于什么是xhr本渣也不是很懂,只知道它是Ajax对象,而Ajax是目前前端广泛应用的一种技术,关于Ajax的更多信息暂不做详细了解。
过滤xhr类型的数据流,我们可以直接选择 >>>谷歌浏览器-Network-XHR获取:

这就获得了所有的XHR文件,这时候我们看看获得的是不是需要的数据,逐个点开-Preview:

这里我点开第一个数据包,其他的类似操作。可以看到,这个数据包里确实包含我们需要的信息,那问题来了,我要如何才能拿到这个数据包呢?
一开始我哧吭哧吭地采用之前很简单的传入UA, Cookies, 然后
requests.get(url, header = headers, cookies = cookies)
甚至连浏览器的监听都没看,这样拿到的只是拉勾网首页的静态页面上的数据,根本拿不到想要的数据。于是仔细看浏览器的监听,之前抓到的XHR数据包的Headers如下:

关注点有两个:
Request URL和Request Method,这里对应可以知道获取这个数据包的链接以及方法。
继续往下看:

form data是我们发起post时必要的参数
然后我又哧吭哧吭地开始码代码了:
# -*- coding: utf-8 -*-
import requests
def get_js(page, job_name):
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0'
headers = {
'Cookie': "user_trace_token=20171218074035-ade4d2dc-e383-11e7-9def-525400f775ce; LGUID=20171218074035-ade4d6be-e383-11e7-9def-525400f775ce; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; JSESSIONID=ABAAABAACBHABBIC9F4C6647BF37CF4EDC0DB33759D67C9; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _putrc=21717327F1B053B4; _gid=GA1.2.1846682322.1514773610; _ga=GA1.2.2062218679.1513554042; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1513554041,1514544070,1514608259,1514773610; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1514773651; LGSID=20180101102652-3a420853-ee9b-11e7-b956-525400f775ce; LGRID=20180101102732-52342eb9-ee9b-11e7-9fc4-5254005c3644; SEARCH_ID=7275bd67bfd7481fb9033dab8abc11f3; index_location_city=%E5%B9%BF%E5%B7%9E",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
}
data = {'first': 'true',
'pn': page,
'kd': job_name
}
response = requests.post(url, data, headers=headers)
print(response.text)
结果:

其实在浏览器中直接输入网址:
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0'
结果:
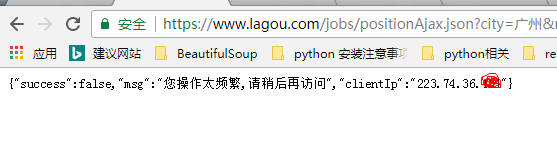
也是一样的。小白如我黑人问号脸了很久,开始找答案,偶然间看到XX培训机构的视频中提到过的一个点,浏览器header中referer防止重定向,其实自己之前也听到过referer,它是规定了当前的链接只能由某一个链接转到,不能直接跳转;不过到这里,才切实体会到其在反爬中的作用。
至此,整体的获取数据的代码如下:
# -*- coding: utf-8 -*-
# https://www.lagou.com/jobs/list_python?px=default&city=%E5%8C%97%E4%BA%AC#filterBox
import requests,json,xlwt
def get_js(page, job_name):
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0'
headers = {
'content-type': "multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW",
'Accept': "application/json, text/javascript, */*; q=0.01",
'Accept-Encoding': "gzip, deflate, br",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Content-Length': "82",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Cookie': "user_trace_token=20171218074035-ade4d2dc-e383-11e7-9def-525400f775ce; LGUID=20171218074035-ade4d6be-e383-11e7-9def-525400f775ce; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; JSESSIONID=ABAAABAACBHABBIC9F4C6647BF37CF4EDC0DB33759D67C9; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _putrc=21717327F1B053B4; _gid=GA1.2.1846682322.1514773610; _ga=GA1.2.2062218679.1513554042; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1513554041,1514544070,1514608259,1514773610; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1514773651; LGSID=20180101102652-3a420853-ee9b-11e7-b956-525400f775ce; LGRID=20180101102732-52342eb9-ee9b-11e7-9fc4-5254005c3644; SEARCH_ID=7275bd67bfd7481fb9033dab8abc11f3; index_location_city=%E5%B9%BF%E5%B7%9E",
'Host': "www.lagou.com",
'Origin': "https://www.lagou.com",
'Referer': "https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E7%88%AC%E8%99%AB%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
'X-Anit-Forge-Code': "0",
'X-Anit-Forge-Token': "None",
'X-Requested-With': "XMLHttpRequest",
'Cache-Control': "no-cache",
'Postman-Token': "2311c5f1-5e34-dc58-d976-e26148708846"
}
data = {'first': 'true',
'pn': page,
'kd': job_name
}
response = requests.post(url, data, headers=headers)
2.解析数据
刚刚我们从拉勾上获取了响应的数据包,这里我们还是要回去看浏览器中捕捉到的信息,谷歌浏览器-NETWORK-XHR-第一个XHR包-Preview:
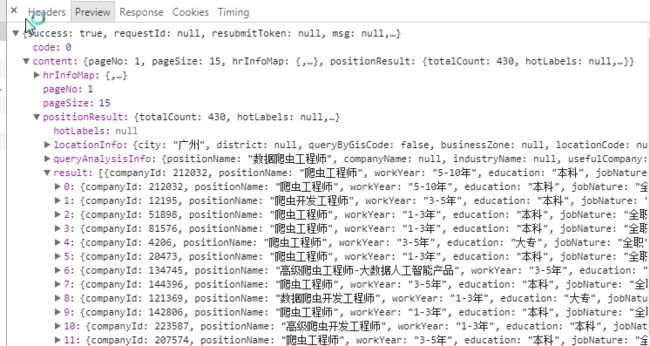
我们要获得的数据,对应的路径为:content-positionResult-result-0(一直到14)
这里0-14可以点开看,就是每个职位的具体信息:

这些json类型的数据,解析起来很方便,类似于键值对的形式,只要我们取其中的键就能获取值。不过首先我们需要对上面get_js(page, job_name)函数做点补充,让它直接拿到json数据。直接上代码吧
def parse_js(json_info):
#定义一个空列表,用以存放我们想要提取的数据
info_list = []
for info in json_info:
#将要的数据通通放到空列表中
info_list.append(info['companyFullName'])
info_list.append(info['companyShortName'])
info_list.append(info['companyId'])
info_list.append(info['positionName'])
info_list.append(info['salary'])
info_list.append(info['workYear'])
info_list.append(info['education'])
info_list.append(info['industryField'])
info_list.append(info['financeStage'])
info_list.append(info['companySize'])
info_list.append(info['city'])
return info_list
然后将数据保存下来就行了。代码如下:
def main():
# 先定义一个空列表,这个列表才是我们真正会写进Excel的列表
real_list = []
# 这里写入 Excel 我用 xlwt 这个库
book = xlwt.Workbook()
sheet1 = book.add_sheet('crwalerposition.xls', cell_overwrite_ok=True)
# 先做个表头
proformlist = ['公司全称', '公司简称', '公司代号', '职位名称', '薪水区间', '工作年限', '教育程度', '行业性质', '目前状况', '公司规模', '上班地点']
j = 0
for pro in proformlist:
sheet1.write(0, j, pro)
j += 1
i_list = []
page = 1
while page < 26:
i_list = i_list + parse_js(get_js(str(page), "爬虫工程师"))
print("得到第%r页数据" % page)
page += 1
# time.sleep(5)
# print(i_list)
for k in range(0, len(i_list), 11):
# 将大列表以11为切割的单位,切割成小列表,方便后面操作。这里感觉有点吃力不讨好了。。。
new_list = i_list[k: k + 11]
real_list.append(new_list)
m = 1
for list in real_list:
n = 0
for info in list:
sheet1.write(m, n, info)
n += 1
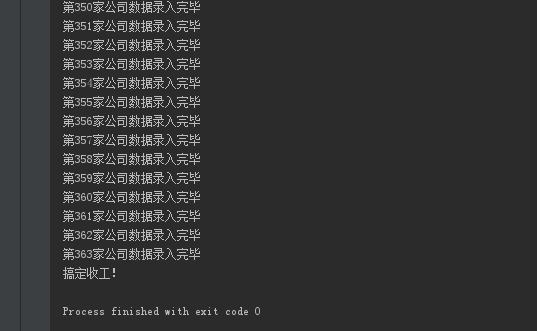
print("第%r家公司数据录入完毕" %m )
m += 1
print("搞定收工!" )
book.save('python_job_info_in_all.xls')
main()
关于保存,我摸了很久。一开始的思路是,将"保存"这件事封装成一个函数,这样,获取,解析和保存都能单独作为一个函数,再编写一个main函数,用for循环遍历所有的20多个页面将,并对以上函数调用就OK。然而当我执行代码的时候,数据总是只能拿到两页数据而已。
为什么只能拿到两页数据?明明有二十几页的呀?这时候新手的不自信就出现了:肯定是我的代码出现了某种问题,而且这个问题应该在外人看来很简单。我仔细把重头代码看几遍,试着将解析的列表打印出来看,显示确实只有那么多数据,排除是写入文件的问题。
那就是获取数据出现问题咯?被ban了?爬取太快?可是我每一次重新跑代码都可以得到数据呀,数据也不多不少就只有那么多,两页。我用了随机ua, time.sleep,差点就上代理ip了,结果还是没,卵,用!!还是偶然的机会,再回去看拉勾网的时候才注意到,我爬的数据和我看的页面根本不一样!!尼玛坑爹,不知道什么时候手抖把查询城市选为不限了,而一开始我只打算爬取广州地区的数据的!!广州本地的爬虫工程师职位确实只有两页。。。。。。(可怜== 本来自己就菜,工作机会还这么少。。。)
下面是全部完整代码:
# -*- coding: utf-8 -*-
# https://www.lagou.com/jobs/list_python?px=default&city=%E5%8C%97%E4%BA%AC#filterBox
import requests,json,xlwt
import time,random
def get_js(page, job_name):
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false&isSchoolJob=0'
#随机ua列表
UA_list = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6"
]
UA = random.choice(UA_list)
#构造请求参数
headers = {
'content-type': "multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW",
'Accept': "application/json, text/javascript, */*; q=0.01",
'Accept-Encoding': "gzip, deflate, br",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Content-Length': "82",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Cookie': "user_trace_token=20171218074035-ade4d2dc-e383-11e7-9def-525400f775ce; LGUID=20171218074035-ade4d6be-e383-11e7-9def-525400f775ce; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; JSESSIONID=ABAAABAACBHABBIC9F4C6647BF37CF4EDC0DB33759D67C9; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _putrc=21717327F1B053B4; _gid=GA1.2.1846682322.1514773610; _ga=GA1.2.2062218679.1513554042; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1513554041,1514544070,1514608259,1514773610; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1514773651; LGSID=20180101102652-3a420853-ee9b-11e7-b956-525400f775ce; LGRID=20180101102732-52342eb9-ee9b-11e7-9fc4-5254005c3644; SEARCH_ID=7275bd67bfd7481fb9033dab8abc11f3; index_location_city=%E5%B9%BF%E5%B7%9E",
'Host': "www.lagou.com",
'Origin': "https://www.lagou.com",
'Referer': "https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E7%88%AC%E8%99%AB%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=",
'User-Agent': UA,
'X-Anit-Forge-Code': "0",
'X-Anit-Forge-Token': "None",
'X-Requested-With': "XMLHttpRequest",
'Cache-Control': "no-cache",
'Postman-Token': "2311c5f1-5e34-dc58-d976-e26148708846"
}
data = {'first': 'true',
'pn': page,
'kd': job_name
}
response = requests.post(url, data, headers=headers)
json_info = response.json()['content']['positionResult']['result']
return json_info #此处return的是一个列表类型
def parse_js(json_info):
#定义一个空列表,用以存放我们想要提取的数据
info_list = []
for info in json_info:
#将要的数据通通放到空列表中
info_list.append(info['companyFullName'])
info_list.append(info['companyShortName'])
info_list.append(info['companyId'])
info_list.append(info['positionName'])
info_list.append(info['salary'])
info_list.append(info['workYear'])
info_list.append(info['education'])
info_list.append(info['industryField'])
info_list.append(info['financeStage'])
info_list.append(info['companySize'])
info_list.append(info['city'])
return info_list
def main():
# 先定义一个空列表,这个列表才是我们真正会写进Excel的列表
real_list = []
# 这里写入 Excel 我用 xlwt 这个库
book = xlwt.Workbook()
sheet1 = book.add_sheet('crwalerposition.xls', cell_overwrite_ok=True)
# 先做个表头
proformlist = ['公司全称', '公司简称', '公司代号', '职位名称', '薪水区间', '工作年限', '教育程度', '行业性质', '目前状况', '公司规模', '上班地点']
j = 0
for pro in proformlist:
sheet1.write(0, j, pro)
j += 1
i_list = []
page = 1
while page < 26:
i_list = i_list + parse_js(get_js(str(page), "爬虫工程师"))
print("得到第%r页数据" % page)
page += 1
# time.sleep(5)
# print(i_list)
for k in range(0, len(i_list), 11):
# 将大列表以11为切割的单位,切割成小列表,方便后面操作。这里感觉有点吃力不讨好了。。。
new_list = i_list[k: k + 11]
real_list.append(new_list)
m = 1
for list in real_list:
n = 0
for info in list:
sheet1.write(m, n, info)
n += 1
print("第%r家公司数据录入完毕" %m )
m += 1
print("搞定收工!" )
book.save('python_job_info_in_all.xls')
main()

总结:
1.异步请求,抓包要学会删选。今天试着抓一些淘宝的评论,哇,那数据简直哗哗的,都不知道自己要的数据在哪个数据包里。告诉自己,学会抓包、学会用抓包工具!
2.简单的反爬策略:UA, 代理,延时。其他的策略有待继续学习。
3.把淘宝京东爬一下,就该学学如何提高效率了。
4.scrapy ,scrapy,scrapy,scrapy