ReLU和BN层简析
卷积神经网络中,若不采用非线性激活,会导致神经网络只能拟合线性可分的数据,因此通常会在卷积操作后,添加非线性激活单元,其中包括logistic-sigmoid、tanh-sigmoid、ReLU等。
sigmoid激活函数应用于深度神经网络中,存在一定的局限性,当数据落在左右饱和区间时,会导致导数接近0,在卷积神经网络反向传播中,每层都需要乘上激活函数的导数,由于导数太小,这样经过几次传播后,靠前的网络层中的权重很难得到很好的更新,这就是常见的梯度消失问题。这也是ReLU被使用于深度神经网络中的一个重要原因。
在之前的学习中,我一直认为ReLU的应用,仅仅是因为在非零区间中,ReLU的导数为1,可以很好的传递反向传播中的误差。最近被问到Dead ReLU问题,于是复习了一下,网上有很多有用的材料,将列在参考材料中,我在这里总结一下。
1. ReLU与生物神经元激活的联系
在我的理解中,人工神经网络的发明,是受到生物神经网络的启发。2001年,神经科学家Dayan、Abott从生物学角度,模拟出了脑神经元接受信号更精确的激活模型,该模型如图所示:图片来源于参考材料

从图中我们可以看到,生物神经元的激活与Sigmoid的不同,(1)单边抑制 (2)兴奋区域较大 (3)稀疏激活性
2003年Lennie等人估测大脑同时被激活的神经元只有1~4%,进一步表明神经元工作的稀疏性。
而在Sigmoid激活中,神经网络中约有一半的神经元被激活了,这可以看出与模拟生物神经网络的想法相违背。
ReLU在负区间中为0,相当于使数据稀疏了,符合生物神经网络的规律。
2. Dead ReLU
若数据落在负区间中,ReLU的结果为0,导数也是0,就会导致反向传播无法将误差传递到这个神经元上,这会导致该神经元永远不会被激活,导致Dead ReLU问题。
解决方法:
1)Leraning Rate
导致Dead ReLU问题的其中一个潜在因素为Learning Rate太大,假设在某次更新中,误差非常大,这时候若LR也很大,会导致权重参数更新后,神经元的数据变化剧烈,若该层中多数神经元的输出向负区间偏向很大,导致了大部分权重无法更新,会陷入Dead ReLU问题中。
当然,小learning rate也是有可能会导致Dead ReLU问题的,于是出现了Leaky ReLU和PReLU。
2)Leaky ReLU
普通的ReLU为:
![]()
Leaky ReLU为:
![]()
其中 取一个很小的数,作者的默认值为0.01,这样可以保证输出小于0的神经元也会进行很小幅度的更新。
取一个很小的数,作者的默认值为0.01,这样可以保证输出小于0的神经元也会进行很小幅度的更新。
3)PReLU
PReLU是Leaky ReLU的进一步优化版,公式表达为:
![]()
其中是一个可以学习的参数,更新是反向传播使用的是momentum来更新,更新方式如下:
![]()

其中 为动量,
为动量, 为学习率。文章中初始化为0.25,且不添加正则化,因为很有可能会很大可能被置0,变成ReLU。
为学习率。文章中初始化为0.25,且不添加正则化,因为很有可能会很大可能被置0,变成ReLU。
3. Batch Normalization
在SegNet网络简析的博文中,我提到过BN层的基本操作和作用。
BN层的出现,主要是为了解决机器学习IID问题,即训练集和测试集保持独立同分布。如果输入的分布不能保持稳定,那么训练就会很难收敛,而在图像处理领域的白化处理,即将输入数据转换为以0为均值,1为方差的正态分布。这样能够让神经网络更快更好的收敛,而这就是BN层所要做的。
“深度神经网络之所以收敛慢,是由于输入的分布逐渐向非线性函数的两端靠拢”,而BN层的作用,就是将输入的分布,拉回到均值为0,方差为1的正态分布上,这样就使输入激活函数的值,在反向传播史能够产生更明显的梯度,更容易收敛,避免了梯度消失的问题。之所以能够在反向传播时产生更明显的变化,我们将输入分布变为标准正态分布后,输入的值靠近中心的概率会变大,若我们的激活函数为sigmoid函数,那么即使输入存在微小的变化,也能够在反向传播时产生很明显的变化。

每层神经网络在线性激活后,通过如下公式进行转换,这个转换就是BN层的操作。

公式中的x是经过该层线性变换后的值,即x = wu+b,u为上一层神经层的输出。
通过这个操作,将输入非线性激活函数的输入值,尽量拉伸到变化较大的区域,即激活函数中间区域。这样能够增大激活函数的导数值,使收敛更快速。而这样也会引入一个问题,强行变换分布后,会导致部分特征无法学习到,因此引入了另一种操作Scale,操作如下:
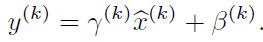
mean和variance是不会进行学习的,而gamma和beta两个参数是可以通过反向传播学习的,通过这两个参数对数据进行扩大和平移,恢复部分特征的分布。
BN层的主要功能总结为两点:
1)归一化scale
没有BN层时,若LR设置较大,在配合ReLU激活函数时,容易出现Dead ReLU问题。
2)数据初始化集中,缓解overfitting(这里还理解得不是很透彻)
Overfitting主要发生在一些较远的便捷点,BN操作可以使初始化数据在数据内部。
通常提到BN层,我们会想到,若使用sigmoid激活函数时,它可以将数据归一化到梯度较大的区域,便于梯度更新。
但很少有人提到BN层和ReLU的联系,https://blog.csdn.net/wfei101/article/details/79997708这篇转载文章中有提到。
在BN中的gamma对于ReLU的影响很小,因为数值的收缩,不会影响是否大于0。但是如果没有偏移量beta,就会出现数据分布在以0为中心的位置,强行将一半的神经元输出置零。因此偏移量beta是必不可少的。