python爬虫实现下载电影天堂电影
这段时间一直在学习Python爬虫,为了加强学习过程,也为了以后的学习留下点痕迹,特此记录下整篇爬虫的过程。以电影天堂为例,提取出当前界面的最新电影。
# -*- coding:utf-8 -*-
import urllib2
import os
import re
url = 'http://www.dy2018.com/html/gndy/dyzz/index.html' #这是电影天堂最新电影的网站
conent = urllib2.urlopen(url)
conent = conent.read()
conent = conent.decode('gb2312','ignore').encode('utf-8','ignore') #为了避免中文乱码
f = open('conent.txt','w')
f.write(conent)
f.close()得到的context.txt文件为 电影天堂,浏览器打开后的F12界面,形如下图。(该文件共有1126行)
初步过滤,过滤出来586行:
pattern = re.compile ('.*?>
(.*?)',re.S)
items = re.findall(pattern,conent)#先把含有最新电影的网页代码选出来,再进行下一次筛选
str = ''.join(items)
f = open('str.txt','w')
f.write(str)
f.close()pattern = re.compile ('(.*?)',re.S)
news = re.findall(pattern, str)
f = open('movie.txt','w')
for j in news:
f.write(j[1]+'\n')
f.close()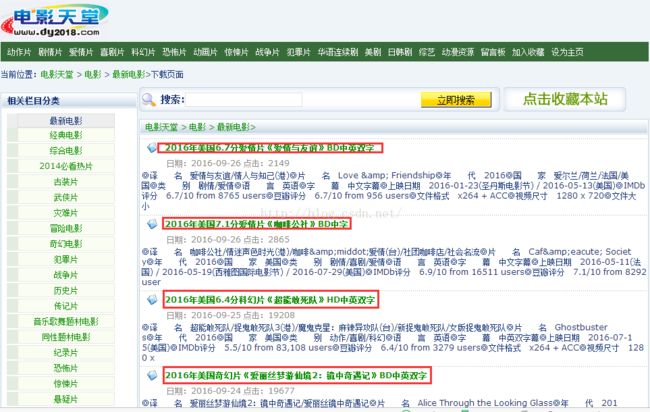

OK,大功告成!
全部代码如下:
# -*- coding:utf-8 -*-
import urllib2
import os
import re
url = 'http://www.dy2018.com/html/gndy/dyzz/index.html' #这是电影天堂最新电影的网站
conent = urllib2.urlopen(url)
conent = conent.read()
conent = conent.decode('gb2312','ignore').encode('utf-8','ignore')
#这个‘ignore’差点就忘了,主要是对一些可以忽略的参数进行编码忽略,下午一直没想起来总是出错
'''
f = open('conent.txt','w')
f.write(conent)
f.close()
'''
pattern = re.compile ('.*?>
(.*?)',re.S)
items = re.findall(pattern,conent)#先把含有最新电影的网页代码选出来,再进行下一次筛选
str = ''.join(items)
'''
f = open('str.txt','w')
f.write(str)
f.close()
'''
pattern = re.compile ('(.*?)',re.S)
news = re.findall(pattern, str)
f = open('movie.txt','w')
for j in news:
f.write(j[1]+'\n')
f.close()