逆向与破解-基础理论
虽然很早就喜欢想要学习,但最早接触逆向的时候还是研一,那个时候的一本《加密与解密》真的给了我特别大的帮助,它的基础讲的通俗易懂,小例子程序也很到位,可以让新手或有点基础的迅速掌握基本的理论和工具使用。
回过头来现在已经搞了将近以一年多的恶意代码检测和WEB安全相关的东西,不过逆向并没有落下,因为恶意代码检测也涉及了不少系统的核心原理,例如堆栈,异常处理机制,程序调试等。
工欲善其事,必先利其器。我们从基础的理论开始,一般学习的过程都是理论-例子-实践,这就跟我们学习-考试-工作是一样的流程,只有课程学的明白了,考试才能考好,进而才能找到好工作。
本章主要分2个部分:
1. 汇编语言
2.可执行文件
3. window和linux的动态链接
需要注意的是,这里涉及的大部分都是比较抽象的,没有具体的细节,用于有一个大概的轮廓可以,想具体学习则需要查找对应资料,我也会慢慢更新。
1. 汇编语言基础
在现代编程大家用的都是python,C++,易语言,java等这些高级语言,但是程序经过编译链接之后执行的都是汇编语言。我们都知道计算机是一种数字设备,里面都是电子原件和芯片。像我们数字电路学的触发器,计时器,还有二极管等,他们的所有信息都是通过电路的通断和电平的高低来表示,即电路中只有两种状态-二进制。计算机就是基于二进制的,只能接受和处理二进制信息,CPU处理的指令也是二进制流,我们称之为机器语言。
机器语言中的每个指令都是由01组成,计算机可以直接识别,而指令集则是由对应的CPU等硬性规定。然而人却很难多读懂和理解机器语言的程序,为此发展处了汇编语言。汇编语言使用单词和符号表示指令,使得可理解性大幅提高。然而对整体的理解依旧是很难,所以就进一步的抽象为高级语言。
简单对应一下:
高级语言两行代码=汇编语言几十行代码=数不清的010101.
他们的关系就是这样一步步抽象,使得编程变得越来越简单。做逆向需要十分熟悉汇编语言,能够读懂汇编代码的流程,所以现在简单说一下汇编语言。

一条汇编指令由操作码和操作数组成,操作数分为
源操作数:提供操作的对象
目的操作数:提供操作对象或目标对象,例如加法完成后会将结果存储到目的操作数
汇编语言可用的寄存器有很多,而且部分寄存器可以分为小寄存器使用
8个32位通用寄存器按顺序分别是:
- EAX 通常用来保存函数的返回值 可分为8位AH,AL
- EBX 可分为8位BH,BL
- ECX 用作计数器 与loop循环指令配合 可分为8位CH,CL
- EDX 可分为8位DH,DL
- ESP 栈顶指针寄存器 保存栈顶地址
- EBP 栈底指针寄存器 保存栈底地址
- ESI,EDI 变址寄存器 地址偏移量
还有标志寄存器,很多时候的比较和跳转都是根据计算结果得到的标志,表示不允许使用指令直接操控,而时计算时时时更新。

- CF 无符号进位标志
- PF 最后8位的1的奇偶标志
- AF 辅助进位,借位标志
- ZF 零标志
- SF 符号标志
- OF 有符号溢出标志 当0-7F中的正数相加等于负数时有溢出,当80-FF中的负数相加等于正数时有溢出,正数加负数永远不会溢出。
- DF 方向标志 控制内存串访问的方向
要想读懂汇编代码,另外需要了解的则是寻址方式,除了操作码代表的功能外,操作数来源(寻址)方式多达七种。
- 立即数寻址:MOV EAX,3064H
- 直接内存寻址:MOV EAX,[3064H]
- 寄存器直接寻址:MOV EAX,EBX
- 寄存器间接寻址:MOV EAX,[EBX]
- 寄存器相对寻址:MOV EAX,[EBX+100H]
- 寄存器基址变址寻址:MOV EAX,[EBX+EDI]
- 寄存器相对基址变址寻址:MOV EAX,[EBX+ESI+0x10H]
汇编语言到此为止,具体的操作码类别和功能,寻址方式示例我会转载大佬的文章。
2. 可执行文件
例如windows中的exe文件,linux中的elf文件。当初遇到过这样一个问题,你把一个MP4文件的扩展名改为avi它就会变吗??并不会,文件的信息已经写在文件头中,扩展名仅是用于快速识别的供软件打开。
我们的程序代码经过编译链接生成exe文件,其中的所有资源(图象,文本,外部引用信息)和汇编代码存储到了文件中,而有关的信息则存储在PE头中。

磁盘文件划分位多个结构,执行是装载进内存,也是按照段装载。而后程序进入到入口点开始执行。
这其中有几个地址需要明确:
文件偏移地址:当PE文件存储在磁盘上时,某个数据的位置相对于文件头的偏移量
虚拟偏移地址:实际的内存地址。虚拟地址(VA) = 基地址(Image Base) + 相对虚拟地址(RVA)。
相对虚拟地址:RVA只是内存中的一个简单相对于PE文件装入地址的偏移位置
装载基址(Image Base):PE文件装入内存的 基地址。默认情况下,EXE文件的基址为0x00400000,DLL文件的基址为0x10000000。
造成内存中偏移与文件偏移不同的原因是文件和内存中分段大小是不一样的。
文件中一个关键的是导出表,它记录了文件中包含的函数名和地址,可以根据函数名得到对应的需要,利用序号可以得到函数入口,这个过程的十分重要,在做文件分析的时候有很大帮助,后期再仔细讲。
大端字节序和小端字节序
再计算机存储数据时有两种顺序,一种是常见的intel序的小端模式,另一种则是打断模式。
例如存储数值0x1234,高位字节是0x12,低位字节是0x34。
- 大端字节序:高位字节在前,低位字节在后,即存储顺序为0x1234。
- 小端字节序:低位字节在前,高位字节在后,即以0x3412形式储存。
类型转换
我们存储在计算机中的数据是固定不变的
就像我们编程中创建了一个简短的字符串,当强制转换类型时则是显示的结果不同,本质上所有存储在内存中的数据都是01010,存储的数据不会变,就看你用什么规则来解析它。
例如0x23可以是字符的#,也可以是数字0x23,就看你将它看做什么。
3. windows和linux
在程序运行的初始阶段,都会有很多的额外操作,包括加载基本的链接库,初始化环境等,所以我们一个小小的hello word才会有那么多行的代码,这个初始化过程我们先不考虑。
linux动态链接
linux的关键是动态链接,常说的延时重定位需要的关键是plt表和got表,plt表可以称为内部函数表,got表为全局函数表。
我们编程时引用了很多其他文件库的函数,在程序运行时需要加载进内存然后调用对应的函数。但在可执行文件加载初始化时并不会直接将外部引用库装载进内存,而时当需要时才会进行加载,也就是所谓的延时重定位。
在代码内部所有的外部函数都被编译为XXX@plt,此时程序跳转plt表,由于第一次调用尚未加载外部库函数,所以其会将外部函数地址加载到got表中,而后再次调用该函数就不需要再次加载,可以直接跳转到got相应入口处,大概就是下面的样子
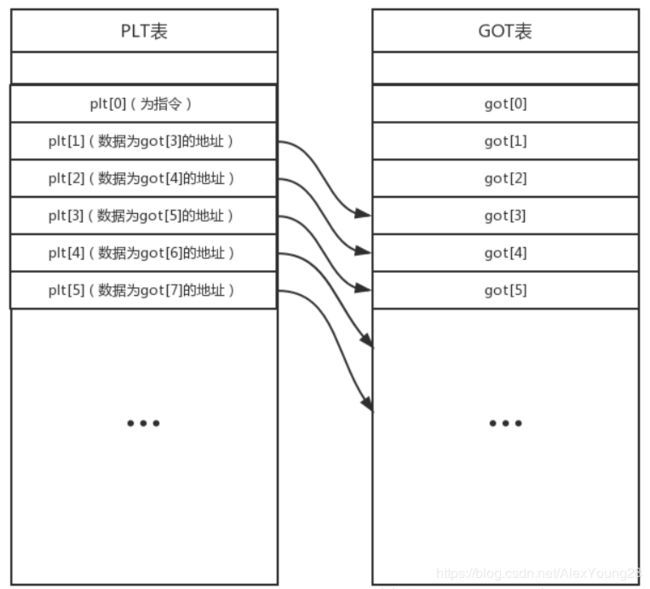
上述多的部分就是加载外部库函数的代码。
windows动态链接
对于windows而言,很多东西要稍微复杂一些。
程序拥有导出表,导出表其中的三个重要成员
- AddressOfNameOrdinals
- AddressOfFunctions
- AddressOfNames
这个的基本原理是使用列表存储函数名 对应的序号 序号对应的函数入口地址。这样通过比对函数名就可以找到对应的函数入口进行调用。

对于外部动态引用,则是通过动态调Windows API函数:Loadlibrary和GetProcAddress
二者通过加载函数库,获取函数地址的方式得到函数入口进行调用。
windows我们常见的user32,kernel32,gdi32时非常基本的核心调用库,里面包含了很多文件,线程,绘制的基本操作。
windows消息驱动
window是消息触发的,系统和程序都存在消息处理回调函数Wndproc,他有四个参数
LRESULT CALLBACK WndProc( //WndProc名称可自由定义
HWND hwnd,
UINT uMsg,
WPARAM wParam,
LPARAM lParam
);后面的三个是消息标识符和两个附带的信息,标识符标识操作的类型。我们主要要说的是句柄hwnd,window中的每个控件,窗体、设备、文件。当需要操作时向系统队列添加对应的句柄的信息,则该消息就会被发送到对应的引用对象,对象根据消息值产生对应的响应。
windows异常处理机制。
这个哪怕没用过,应该也接触过。(类似程序崩溃的例子有很多)
在编程时,我们也会接触try...catch异常捕获关键字,当其中的代码发生错误时,系统会根据给出的解决方法尝试修复并继续执行,当给出的方法不能解决,那么会调用默认的异常处理方法安静的退出程序,不会造成其他损坏。
异常处理结构加载在线程环境信息中,当发生错误时系统会保存当前状态信息到一个异常结构体中,通过遍历已经注册的异常处理判断是否有可以处理该错误的函数,有的话则进入函数并处理出错信息,没有则调用默认异常处理,具体的有一位大佬讲的很清楚,我会转载过来。