VGG16模型训练自己数据集
什么是VGG16模型
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。这就是说VGG模型能够很好的适用于分类和定位任务。
可能大家会想,这样一个这么强的模型肯定很复杂吧?
其实一点也不复杂,它的结构如下图所示:

这是一个VGG被用到烂的图,但确实很好的反应了VGG的结构:
**
1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
3、conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
4、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
5、conv4三次[3,3]卷积网络,输出的特征层为256,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
6、conv5三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
**
不通结构卷积网络配置平铺图(重点关注结构D即VGG16):
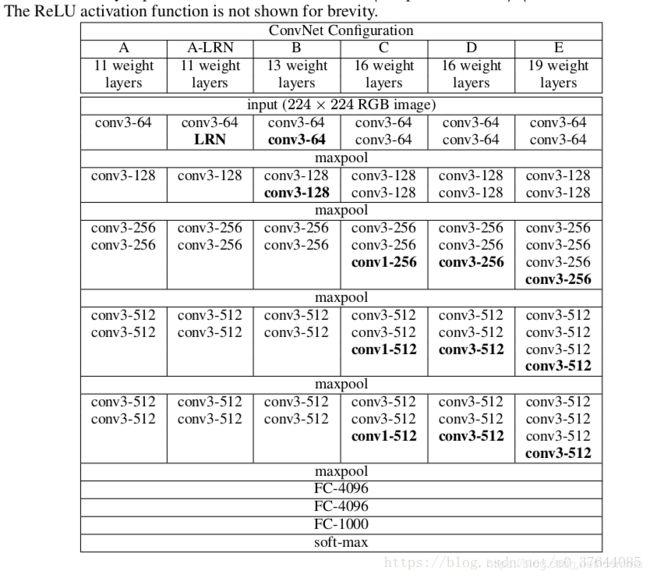
在训练期间,ConvNets的输入是固定大小的224×224 RGB图像。 唯一预处理是从每个像素中减去在训练集上计算的平均RGB值,(eg:VGG16是:VGG_MEAN = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32))处理时候转换成了RGB→BGR格式。
图像通过一堆卷积(转换)层,使用具有非常小的感知域的滤波器(卷积核): 3×3(这是捕捉左/右,上/下,中心概念的最小尺寸)。 在配置C的RGG16中,我们还使用1×1卷积滤波器,可以看作是输入通道的线性变换(后面是非线性)。
卷积步幅固定为1个像素; 卷积层输入的空间填充使得在卷积之后保持空间分辨率,即对于3×3个卷积层,填充是1个像素。 空间池由五个最大池组执行,这些层跟随一些转换。 图层(并非所有转换图层都跟随最大池)。 最大池化在2×2像素窗口上执行,步幅为2。
卷积层(在不同的体系结构中具有不同的深度)的stack之后是三个完全连接(FC)层:前两个层各有4096个通道,第三个层执行1000路ILSVRC分类,因此包含1000个通道(每个类一个)。最后一层是soft-max层。在所有网络中,完全连接层的配置是相同的。所有隐藏层都具有整流(ReLU)非线性特性。网络(除了一个)都不包含本地响应规范化(LRN)规范化,因为作者尝试了这种规范化不会提高ILSVRC数据集的性能,但会增加内存消耗和计算时间。
The convolutional layer parameters are denoted as “conv receptive field size - number of channels ”
vgg有五种模型:ABCDE,D就是VGG16,E就是VGG19。19层数的计算是conv层+FC。
卷积:conv:f=33,s=11,p=11;Maxpool: f=22,s=2*2,p=0
**卷积核:**是每stack层卷积核的个数3×3
**特征层数:**由首阶段64,逐层增一倍至512