XXL-JOB任务分片
背景
假设有k个地市,每个地市有x个订单执行,总共kx个订单,而每个订单中又有一个字段体现出地市信息。
@Component
@Slf4j
public class AhOrdersXxlJob {
//城市编号
private static final List<Integer> CITY_ID_LIST = Arrays.asList(550, 551, 552, 553, 554, 555, 556, 557, 558, 559, 561, 562, 563, 564, 566);
//每个城市的任务数
private static final int PER_LATN_TASK_NUM = 30;
// 任务数据库
private static final Map<Integer, List<String>> singleMachineMultiTasks;
static {
singleMachineMultiTasks = new HashMap<>();
CITY_ID_LIST.forEach(city -> {
List<String> tasks = new ArrayList<>(PER_LATN_TASK_NUM);
IntStream.rangeClosed(1, PER_LATN_TASK_NUM).forEach(index -> {
String orderInfo = city + "------NO." + index ;
tasks.add(orderInfo);
});
singleMachineMultiTasks.put(city, tasks);
});
}
}
现使用xxljob进行分片任务执行,有两种解决思路。
单机多任务
自定义业务规则,配置多个xxl任务,来实现分片功能。
配置多个任务

每个任务指定不同的参数,但使用相同的jobhanlder:
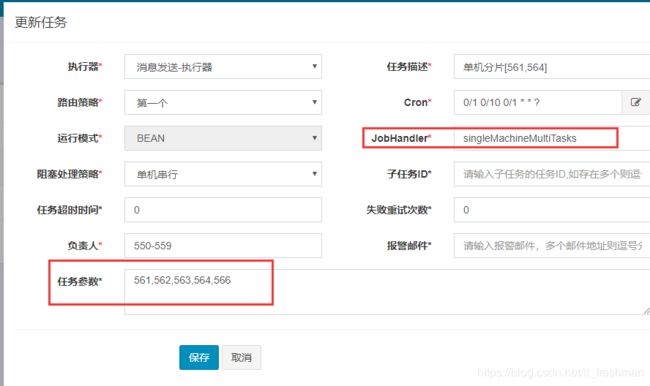
JobHandler实现
@XxlJob(value = "singleMachineMultiTasks", init = "init", destroy = "destroy")
public ReturnT<String> singleMachineMultiTasks(String cities) throws Exception {
if (StringUtils.isEmpty(cities)) {
return new ReturnT(FAIL_CODE, "latnIds不能为空");
}
Arrays.stream(cities.split(",")).map(String::trim).filter(StringUtils::isNotBlank).map(Integer::parseInt).forEach(latnId -> {
List<String> tasks = singleMachineMultiTasks.get(latnId);
Optional.ofNullable(tasks).ifPresent(todoTasks -> {
todoTasks.forEach(task -> {
XxlJobLogger.log("【{}】执行【{}】,任务内容为:{}", Thread.currentThread().getName(), latnId, task);
});
});
});
return ReturnT.SUCCESS;
}
执行结果
分别启动两个任务,查看执行日志:
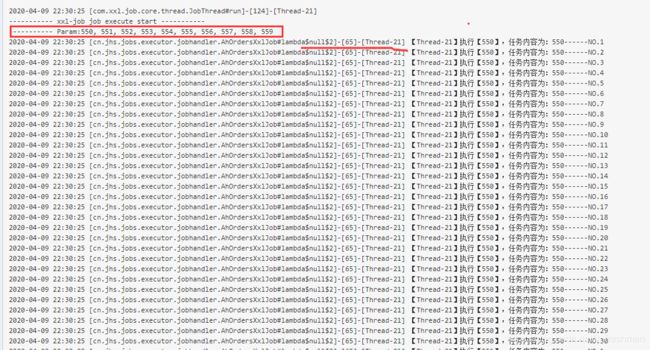
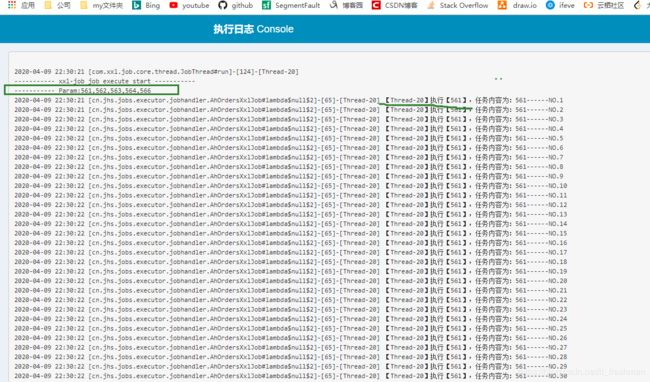
分两个线程,分别执行各自的任务清单;
多机分片
采用多机器取模的方式,来为不同的机器指定各自服务的城市列表。
一致性hash ?
启动多个执行管理器实例
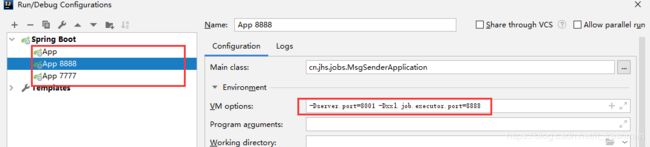
xxl执行管理器

配置多实例分片任务
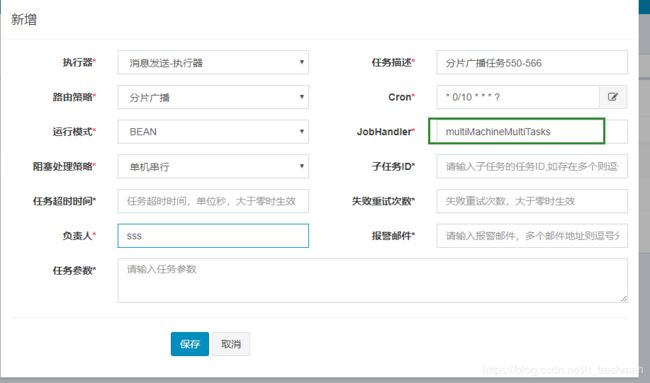
JobHandler实现
@XxlJob(value = "multiMachineMultiTasks", init = "init", destroy = "destroy")
public ReturnT<String> multiMachineMultiTasks(String params) throws Exception {
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
int n = shardingVO.getTotal(); // n 个实例
int i = shardingVO.getIndex(); // 当前为第i个
IntStream.range(0, CITY_ID_LIST.size()).forEach(cityIndex -> {
if (cityIndex % n == i) {
int city = CITY_ID_LIST.get(cityIndex);
List<String> tasks = singleMachineMultiTasks.get(city);
Optional.ofNullable(tasks).ifPresent(todoTasks -> {
todoTasks.forEach(task -> {
XxlJobLogger.log("实例【{}】执行【{}】,任务内容为:{}", i, city, task);
});
});
}
});
return ReturnT.SUCCESS;
}
执行结果
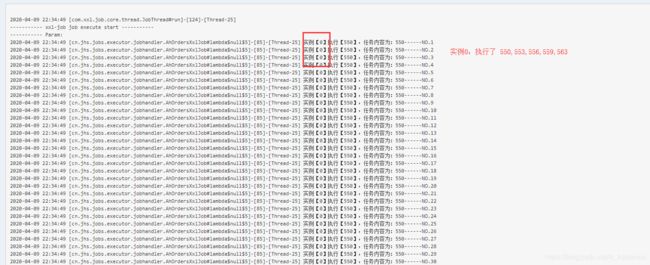
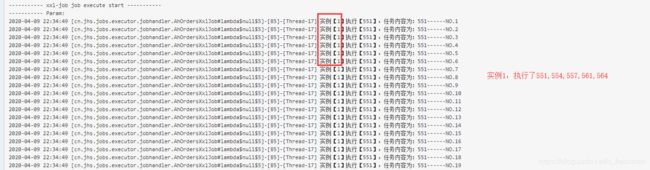
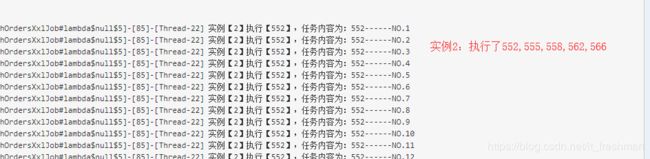
生命周期函数
@XxlJob(value = "singleMachineMultiTasks", init = "init", destroy = "destroy")
public ReturnT<String> singleMachineMultiTasks(String cities) throws Exception {
//.....
}
@XxlJob(value = "multiMachineMultiTasks", init = "init", destroy = "destroy")
public ReturnT<String> multiMachineMultiTasks(String params) throws Exception {
//.....
}
public void init() {
log.info("init");
}
public void destroy() {
log.info("destory");
}
如果不显示的指明生命周期函数,在方法执行完之后,会被销毁。
todo - - 思考
如果执行器管理某一个实例挂掉了? 如何保证那一部分数据不会丢失,不会重复消费?