1、数据库分类
关系型数据库(利用二维表及其之间的相互关系联系起来的数据库):mysql、oracle、sqlserver等
非关系型数据库:redis、mencache、mogdb、hadoop等
2、数据库的三范式
最低要满足第三范式
(1)第一范式(1NF)
数据库的每一列都是不可分割的基本数据项,同一列中不可能有多个值,即:实体类的某个属性不能有多个值或者不能有重复的属性(原子性)
例如:在学生表的联系方式字段的只有两个:电话和Email,这是不符合第一范式的
(2)第二范式(2NF)
前提是要满足第一范式,要求数据库表中的每一个实例或行必须可以被唯一的区分,为实现区分通常需要为表加一个列,以存储各个实例的唯一标识(不产生局部依赖,每列都完全依赖于主键,一张表只描述一件事)
也就是说一张表只能做一件事,并且每一张表都要有一个主键
(3)第三范式(3NF)
前提是满足第二范式,要求一个数据库表中不包含已经在其他表中已经包含的非主关键字信息(就是要使用外键的方式将其关联过来,不产生传递依赖,所有的列都直接依赖于主键,同时使用外键关联,外键都来源于其他表的主键)
班级表:

学生表:
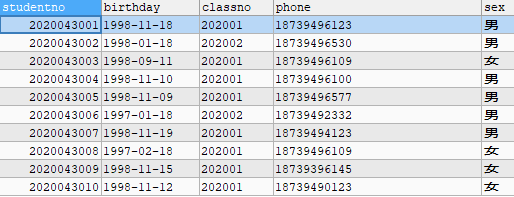
在学生的基本信息中有班级这个字段,如果学生表将班级表中的每一个字段又在表中复制了一遍,那么就会造成数据的冗余。解决方案是将班级表的外键放入到学生表中,因为该外键在班级表中是主键,可以代表班级表。
也就是说在满足一张表只做一件事的基础上,将一张表拆分后,要通过外键建立两张表之间的联系
(4)反三范式
反三范式是为了追求性能,因为3NF提出的目的是为了降低冗余,减少不必要的存储,然而随着存储设备的降价以及人们对性能要求的不断提高,提出了反三范式的概念
例如:在上面的学生表和班级表中如果要查询学生的班级信息的时候要查询两次数据库,但是,如果直接将班级信息存储在学生表中,虽然增加了数据库的冗余,但是每次查询都只需查询一次,提高了程序的性能。