利用多 GPU 加速深度学习模型训练
01
—
前言
深度学习模型通常使用 GPU 训练,因为 GPU 具有相比 CPU 更高的计算能力,以 Tesla V100 为例,使用 Tensor Core 加速的半精度浮点计算能力达到 125 TFLOPS【1】,配有 V100 GPU 的单个服务器节点最多可替代 60 个 CPU 节点,正如每年 GTC Keynote 上黄仁勋宣称的“The more you buy, the more you save”。


目前计算机视觉、语音识别、自然语言处理等领域最好的深度学习模型通常采用更高参数量模型结合更大规模数据训练得到。例如 ResNet-50 有大约 2300 万参数量,用于训练的 ImageNet 数据集有 128 万张图片,利用一块 Tesla V100 完成 90 轮(epoch)训练大约需要 2~3 天时间;中英文语音识别模型 DeepSpeech2 拥有 1 亿参数量,语音训练数据总时长超过 2 万小时,单 GPU 训练时间约 3~6 周;用于文本生成的 GPT-2 模型参数量多达 15 亿,预训练所需数据 WebText 多达 800 万篇文章,使用单块 GPU 训练耗时将长达一个月甚至更久。这些顶尖模型由于训练到部署迭代周期长,无法保证业务上线时间需求,为了加快节奏,需要借助更多 GPU 并行处理。
02
—
多 GPU 通信原理
2.1 单机多 GPU 通信
首先我们关注单台服务器上插有多张 GPU 的情况。受限于主板 PCIe 插槽数目和拓扑方式,在一台服务器中一般不超过 16 张卡。单机 8 GPU 或 16 GPU 已经可以承担一般规模训练任务。下图为典型的 8 卡 GPU 服务器外观:

8 卡服务器内部 CPU-CPU、CPU-GPU、GPU-GPU 之间互联拓扑关系如下图所示:
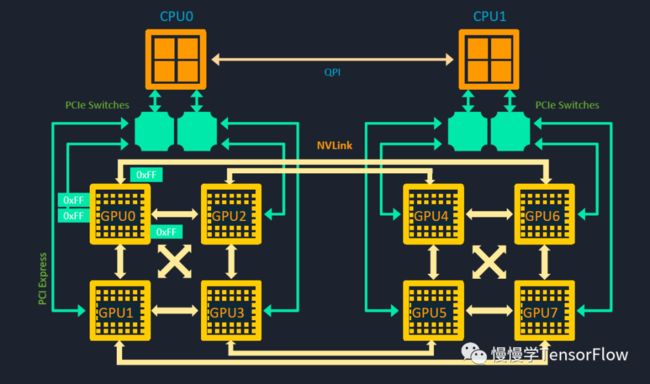
其中 CPU0 和 CPU1 通过 QPI 互联,CPU 与 GPU 则通过 PCIe Switch 互联。GPU 0~3 两两之间可以既可以通过 NVLink 通信又可以走 PCIe Switch,同样 GPU 4~7 也是如此。而 GPU 0 和 GPU 4 之间没有直接通路,需要借助其他途径间接通信。不同互联通路的有效带宽如下图所示:

可以看到两颗 GPU 之间如果有高速通路 NVLink,通信开销将远低于间接通路,从而实现线性扩展。程序设计时应尽可能减少使用低速通路如 QPI。
多 GPU 通信可以借助 CUDA API,通过显式调用 cudaSetDevice() 指定使用哪张卡进行显存分配和执行计算,如需交换数据,可以调用 cudaMemcpyPeer() 拷贝到目标设备,再启动 Kernel 计算。
除此之外,NVIDIA 提供了用于多 GPU 通信库 NCCL(NVIDIA Collective Communications Libary)【2】,实现了 AllReduce、Reduce、Broadcast、ReduceScatter、AllGather 等常用通信原语,面向 PCIe 和 NVLink 做了专门优化,具有更高带宽、更快速度。NCCL 最初只支持单机多 GPU 通信,从 NCCL2 开始支持多机多 GPU 通信。
后文几张图演示了 NCCL 各个原语的具体作用以及相应的 API 封装。约定每个 rank 只对应一块 GPU,rank 后面数字编号与 GPU 设备编号保持一一对应。
Broadcast
广播原语,将某个 rank 上的数据拷贝到其他所有 rank(图中示例将 rank 2 内容广播给 rank0~3)。

NCCL API Broadcast 调用接口如下:
ncclResult_t ncclBroadcast(const void* sendbuff, // 待广播数据地址void* recvbuff, // 接收广播地址size_t count, // 广播数据长度ncclDataType_t datatype, // 广播数据类型,可选:ncclInt8, ncclChar, ncclUint8, ncclInt32, ncclInt, ncclUint32, ncclInt64, ncclUint64, ncclFloat16, ncclHalf, ncclFloat32, ncclFloat, ncclFloat64, ncclDoubleint root, // 待广播设备编号ncclComm_t comm, // NCCL 通信句柄cudaStream_t stream) // 绑定的 CUDA 流
Reduce
归约原语,对所有 rank 数据做归约计算,结果放到其中一个 rank(图中示例将 rank0~3 数据归约后放到 rank2)。
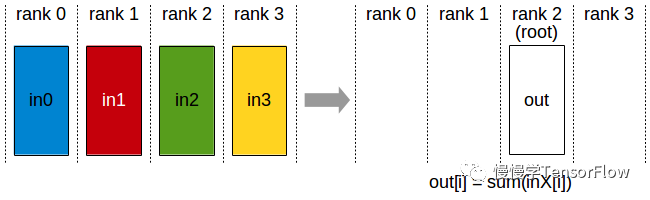
NCCL API Reduce 调用接口如下:
ncclResult_t ncclReduce(const void* sendbuff, // 待归约数据地址
void* recvbuff, // 归约结果存放地址
size_t count, // 归约数据长度
ncclDataType_t datatype, // 归约数据类型,可选:ncclInt8, ncclChar, ncclUint8, ncclInt32, ncclInt, ncclUint32, ncclInt64, ncclUint64, ncclFloat16, ncclHalf, ncclFloat32, ncclFloat, ncclFloat64, ncclDouble
ncclRedOp_t op, // 归约计算类型,可选:ncclSum(+), ncclProd(*), ncclMin, ncclMax
int root, // 归约结果存放 rank
ncclComm_t comm, // NCCL 通信句柄
cudaStream_t stream) // 绑定的 CUDA 流AllReduce
完全归约原语,对所有 rank 数据做归约计算,结果放到每一个 rank。
注:AllReduce 等价于 Reduce+Broadcast。

NCCL API All Reduce 调用接口如下:
ncclResult_t ncclAllReduce(const void* sendbuff, // 待归约数据地址void* recvbuff, // 归约结果存放地址size_t count, // 归约数据长度ncclDataType_t datatype, // 归约数据类型,可选:ncclInt8, ncclChar, ncclUint8, ncclInt32, ncclInt, ncclUint32, ncclInt64, ncclUint64, ncclFloat16, ncclHalf, ncclFloat32, ncclFloat, ncclFloat64, ncclDoublencclRedOp_t op, // 归约计算类型,可选:ncclSum(+), ncclProd(*), ncclMin, ncclMaxncclComm_t comm, // NCCL 通信句柄cudaStream_t stream) // 绑定的 CUDA 流
AllGather
完全汇聚原语,从 K 个 rank 各取长度为 N 的一段数据,结果按 rank 顺序汇聚到每个 rank,长度为 K*N。
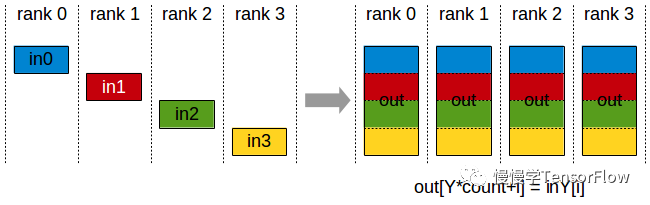
NCCL API AllGather 调用接口如下:
ncclResult_t ncclAllGather(const void* sendbuff, // 待汇聚数据地址void* recvbuff, // 汇聚结果存放地址size_t sendcount, // 汇聚数据长度ncclDataType_t datatype, // 汇聚数据类型,可选:ncclInt8, ncclChar, ncclUint8, ncclInt32, ncclInt, ncclUint32, ncclInt64, ncclUint64, ncclFloat16, ncclHalf, ncclFloat32, ncclFloat, ncclFloat64, ncclDoublencclComm_t comm, // NCCL 通信句柄cudaStream_t stream) // 绑定的 CUDA 流
ReduceScatter
归约+分发原语,和 Reduce 功能类似,区别是归约结果按 rank 顺序平均分发给每个 rank,最终每个 rank 只保存部分结果。
注:ReduceScater + AllGather 等价于 AllReduce。
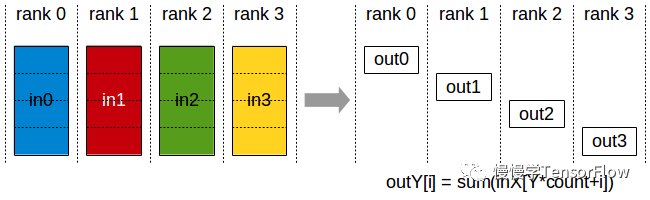
ncclResult_t ncclReduceScatter(const void* sendbuff, // 待归约+分发数据地址void* recvbuff, // 归约+分发结果存放地址size_t recvcount, // 分发数据长度ncclDataType_t datatype, // 归约+分发数据类型,可选:ncclInt8, ncclChar, ncclUint8, ncclInt32, ncclInt, ncclUint32, ncclInt64, ncclUint64, ncclFloat16, ncclHalf, ncclFloat32, ncclFloat, ncclFloat64, ncclDoublencclRedOp_t op, // 归约计算类型,可选:ncclSum(+), ncclProd(*), ncclMin, ncclMaxncclComm_t comm, // NCCL 通信句柄cudaStream_t stream) // 绑定的 CUDA 流
2.2 多机多 GPU 通信
如果单机多 GPU 计算能力仍然不够,只能通过多台机器进行水平扩展。多机多 GPU 典型的架构如下图所示:
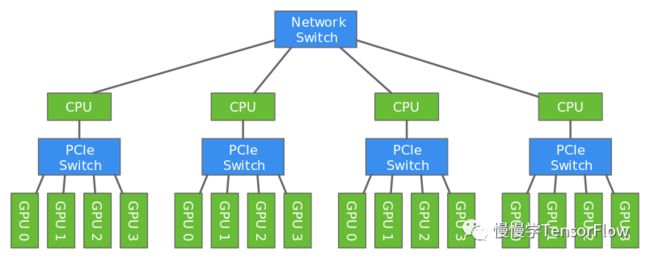
上图中每个服务器都由一颗 CPU + 4 块 GPU 组成,GPU 间通过 PCIe Switch 互联;服务器之间通过 Network Switch 互联,常用的以太网互联按通信速率又可分为千兆、万兆、25G、40G、100G 等,带宽分别为 1Gbps、10Gbps、25Gbps、40Gbps、100Gbps。多机之间通信基于 Socket,通信过程如下图所示:

从上图可见,基于 Socket 的多机通信过程会发生多次数据拷贝(从发送端用户态到内核态,再从接收端内核态到用户态),效率低下。
InfiniBand( 字面意思“无限带宽”,简称 IB) 是一个高速、低延迟、低 CPU 占用、高效可扩展的服务器和存储互联技术,是用于高性能计算的网络通信标准。IB 关键特性是支持远程直接数据存取(Remote Direct Memory Access,简称 RDMA)技术,可以将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统以及 CPU 的介入。IB 单网口速度支持从 10Gb/s(SDR) 到 56Gbps(FDR),目前已成功应用于高性能计算、数据库和存储等领域。IB 虽好,但在数据中心部署起来成本奇高,不仅需要每台服务器插专门支持 IB 的网卡,还要采购价格高昂的交换机设备,它们与已有的网络设备不兼容,无疑增加了运维难度。RoCE(RDMA over Converged Ethernet)是在以太网环境支持 RDMA 的标准,无需复杂和低效的 TCP 传输。基于 RDMA 的多机通信过程:
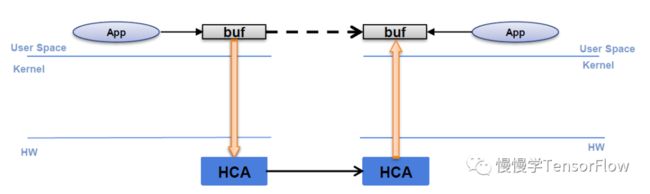
基于 RDMA 的多机通信方式则可以实现“零拷贝”,大幅降低通信延迟。
多机软件设计一般采用 MPI(Message Passing Interface)实现数据交互。MPI 是一种消息传递库接口描述标准,规定了点对点消息传递、协作通信、组和通讯员概念、进程拓扑、环境管理等各项内容,支持 C 和 Fortran 语言。MPI 具有多个实现版本,常用的有 Intel MPI、MPICH、MVAPICH、OpenMPI 等。MPI 同样提供了前面提到的各种通信原语如 Reduce、Scatter、Broadcast 等,对应的 API 与 NCCL 十分相似。事实上,NCCL 出现得更晚一些,参考并兼容了 MPI 已有 API。NCCL 更多考虑了 GPU 的特性,例如任意两块 GPU 之间的通信开销是有区别的,跨 QPI 情况与同一 PCIe Switch 情况,以及有 NVLink/ 无 NVLink 情况就有明显差异,但 MPI 认为两种情况下 GPU 与 GPU 都是等同的,甚至 MPI 认为跨机器的 GPU 也是等同的,这对于多 GPU 通信效率会有影响。
MPI 可以和 NCCL 结合,实现层次化的并行通信机制,即同一台机器上的不同 GPU 之间采用 NCCL 通信,而不同机器上的 GPU 之间采用 MPI 辅助通信。
对于具体训练框架而言也有内置的多机通信支持,例如 TensorFlow 通过 gRPC 实现多机模型,详见后面小节。
03
—
深度学习模型并行训练方法
在单块 GPU 上训练流程为:
-
从磁盘加载批数据(如 64 张图片和对应标签)到内存;
-
调用 cudaMemcpy() 传输到 GPU;
-
启动模型前向计算过程,得到训练 loss;
-
经反向传播计算得到各层可变权重的梯度
-
根据优化器的策略对权重做更新;
如此循环往复,直到损失值下降到可接受范围。
由于所有权重、梯度、中间特征都可以存放于同一块 GPU 的显存,并且所有计算都已经由 GPU 实现,训练过程中除了载入数据涉及 CPU-GPU 拷贝之外并无其他需要交互的环节,如果将完整数据集预先拷贝到 GPU 显存中,模型训练将更高效。一般这种情况只能用于针对 MNIST、CIFAR 等小数据集训练的场景。
如果数据规模较大,比如 ImageNet 有 100 多万张图片,分为 1000 类,完整数据集需要大约 150 GB 存储空间,单张 GPU 训练时只能存放一小部分数据,需要不断从磁盘加载数据到内存再到 GPU,吞吐有限。如果利用多 GPU 可以存放更多数据,从而加快训练。根据不同的计算切分方式,大体分为以下几种类型:
-
数据并行
每块 GPU 负责一部分数据,所有 GPU 共享同一模型权重;
适合数据规模大、单 GPU 可容纳完整模型的场景; -
模型并行
每块 GPU 负责一部分模型,所有 GPU 共享同一批数据;
适合模型参数量大,单 GPU 无法容纳的场景; -
混合方式
兼有上面两种特点,适合特殊模型场景;
下面我们一一介绍这几种并行训练方式。
3.1 数据并行训练
对于数据并行,最常用的是参数服务器(Parameter Server,简称 PS)架构,如下图所示:

图上方为中心化的参数服务器,负责维持当前最新的模型权重;图下方为若干个训练节点,需要从参数服务器获取最新权重,在本地复制一份完整的模型。训练时各个训练节点使用不同的数据,在进行模型前向计算+反向计算结束后,权重更新之前,每个训练节点都需要将局部梯度发送给 PS,由 PS 完成多个局部梯度归约并对权重更新,再将最新权重下发至各个训练节点。根据训练节点之间是否同步,参数服务器可以支持同步工作方式和异步工作方式。
同步方式要求各个训练节点计算能力一致,例如所有服务器都采用相同硬件配置,不能将高端 GPU 和低端 GPU 混用,否则会由于木桶效应,跑得快的训练节点必须等跑得慢的训练节点计算完成才能进行下一步,这将造成不必要的等待浪费计算资源。
异步方式允许每个训练节点分头行动,一旦发送梯度给 PS 将会立即得到最新权重,无需等待其他训练节点。该方式允许不同训练节点使用异构硬件,能者多劳,但该方式存在训练不容易收敛的问题,除了 Google 和微软,几乎没有能真正玩转的。
在参数服务器架构中,PS 节点需要和每个训练节点通信,随着训练节点数量增大,PS 节点很容易成为性能瓶颈。例如在万兆网环境下,单 PS 节点带宽只有约 1GB/s,所有训练节点共享这部分带宽,当存在 100 个训练节点时每个节点只能分到 10MB/s 带宽,很难满足大模型(如 BERT、GPT-2 )训练需求。为了避免该问题,百度 2017 年提出去中心化的梯度同步和权重更新算法,叫做 Ring-AllReduce【3】,每个节点只和相邻的两个节点通信,不需要参数服务器,所有节点同时参与计算和存储。

权重更新主要包含 2 个过程:
-
Scatter-Reduce. 即分发归约,将每张卡局部梯度平均分为 N 份(N 和 GPU 数目相同),每一步每张卡只向下一节点发送 1 份梯度,并接收上一节点 1 份梯度,实施归约计算。经过 N-1 步,归约后的梯度分散在 N 张卡。下面几张图演示了分发归约过程:
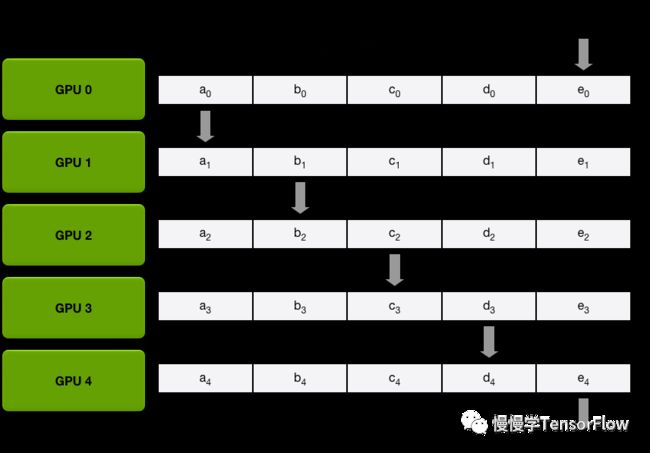
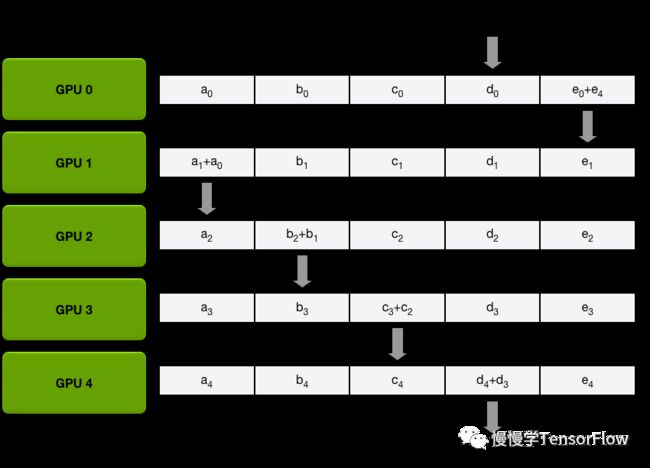

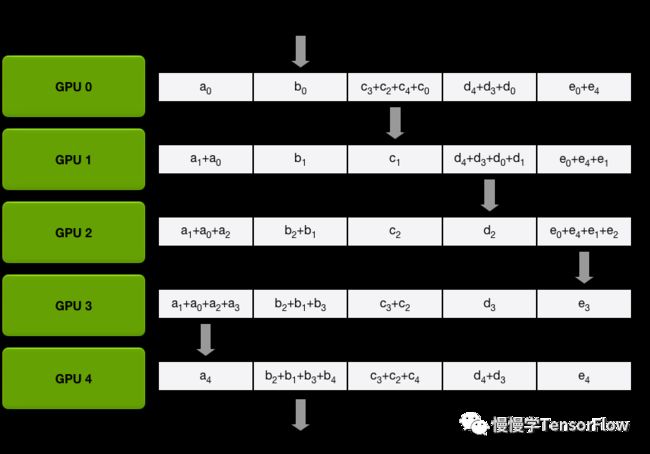
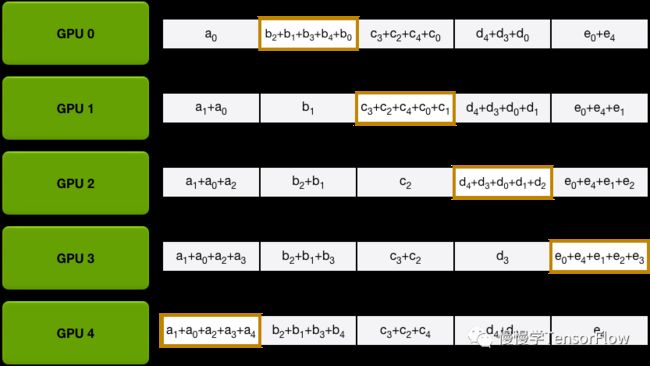
-
AllGather. 即梯度汇聚。将 i 得到的归约梯度汇聚并同步到每张卡,最后根据优化器设置更新权重。示意图如下:
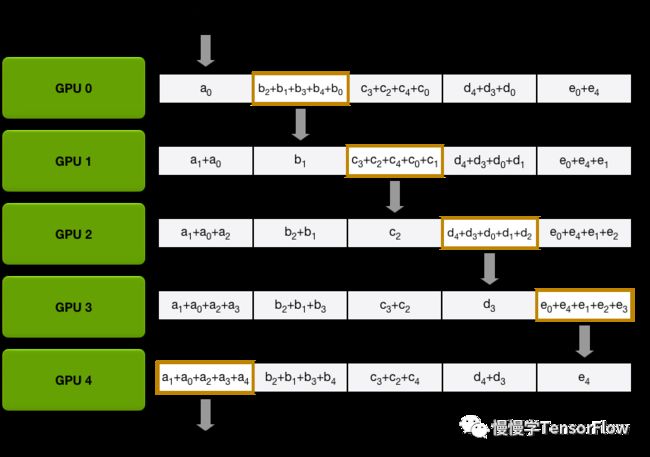
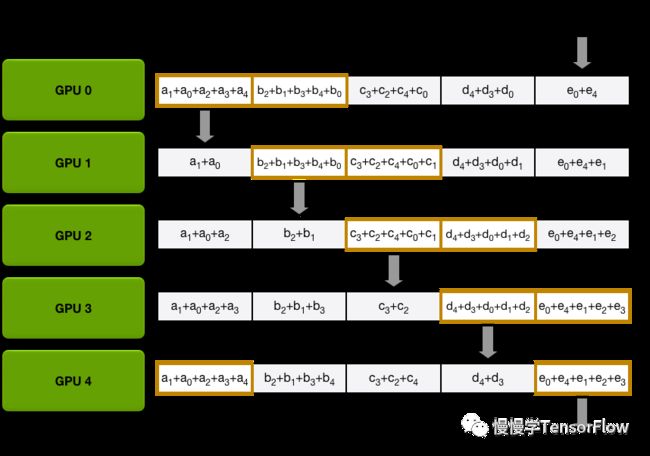
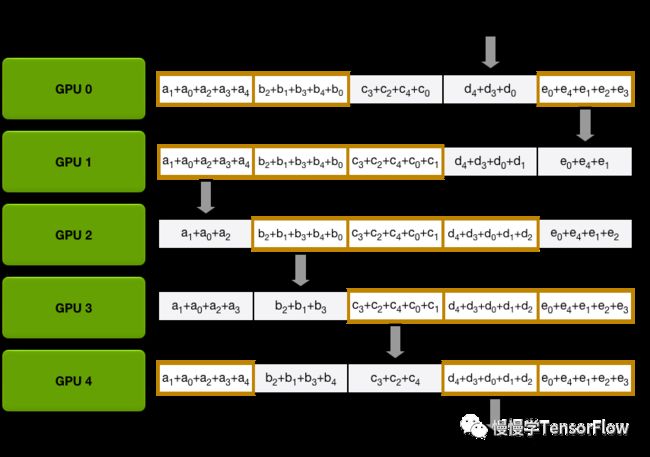


在上述去中心化的梯度同步更新方案中,去掉了参数服务器,训练权重完全分布于每个节点内部,随着节点数量增大,节点间可以保持恒定通信带宽,避免参数服务器的 I/O 瓶颈问题,多机扩展性更好,后面将介绍的 Horovod 就是基于该方案的一种工程实现。Ring-AllReduce 方案中所有计算节点必须以同步方式工作,步调一致,不适合异构网络和计算环境。
3.2 模型并行训练
模型并行适合模型参数量大,单 GPU 无法容纳的场景,当年 AlexNet 作者 Alex Krizhevsky 手头只有 GTX 580,单卡显存容量只有 3 GB,于是将模型部分层分割到两张卡上,实现了简单的模型并行训练【4】。
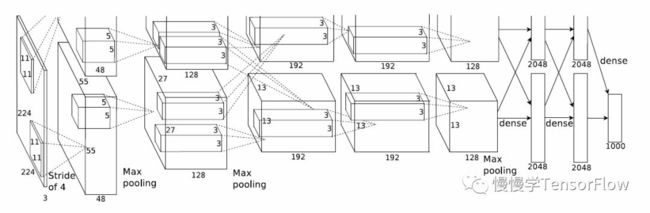
如今我们有了更高端的 Tesla V100,显存容量高达 32 GB,对于训练 AlexNet 这样的模型来说绰绰有余,是否就意味着不再需要研究模型并行了呢?
当然不是。去年 8 月英伟达宣布训练出世界上最大的基于 Transformer 的语言模型,参数量达到 83 亿,比 BERT 大 24 倍,比 OpenAI 的 GPT-2 大 5 倍;最近微软又打破了这项纪录,发布的 T-NLG 模型参数量达 170 亿,隐层单元数为 4256,28 个 attention head,78 个 Transformer 层,训练时采用张量切片法将模型分割到 4 张 V100 上,思路同前面 AlexNet 如出一辙。
模型并行的关键是选择切片部位,避免产生新的通信瓶颈。
3.3 数据并行+模型并行混合方式
还是 Alex Krizhevsky,在 2014 年提出了一种用来并行化卷积神经网络训练的“weird trick”【5】。在多 GPU 上既用数据并行,又用模型并行,按实际模型的计算-通信开销来确定切割方式。架构图如下:

在 CNN 中卷积层占据绝大部分计算量,而最后几个全连接层则占据绝大多数参数量。也就是说一个 CNN 前面几层卷积层参数量少,做数据并行时 GPU 之间同步参数开销更低;而后面几层全连接层参数量大,特征数量相对更少,做模型并行时只需在 GPU 之间传递特征,开销更低。该方案和具体模型相关,近几年的模型已经大幅缩减甚至完全去除了全连接层。
04
—
TensorFlow 分布式实现
4.1 TensorFlow 1.x 分布式实现
截止目前,TensorFlow【6】仍然是最流行的深度学习开源框架,拥有大量用户群体。TensorFlow 从 0.8 开始支持分布式计算。TensorFlow 计算过程基于有向图(graph),包含若干节点(node)。计算图中的节点以各自依赖顺序执行。以下代码实现了 y = ReLU(Wx+b) 计算过程:
import tensorflow as tfb = tf.Variable(tf.zeros([100])) # 100-d vector, init to zeroesW = tf.Variable(tf.random_uniform([784,100],-1,1)) # 784x100 matrix w/rnd valsx = tf.placeholder(name="x") # Placeholder for inputrelu = tf.nn.relu(tf.matmul(W, x) + b) # Relu(Wx+b)C = [...] # Cost computed as a function# of Relus = tf.Session()for step in xrange(0, 10):input = ...construct 100-D input array ... # Create 100-d vector for inputresult = s.run(C, feed_dict={x: input}) # Fetch cost, feeding x=inputprint step, result
对应的计算图如下:
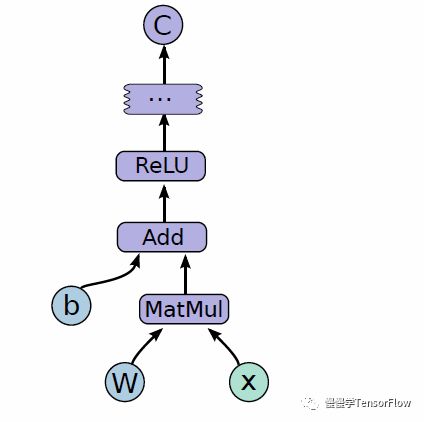
上图中每个节点(node)有 0 到多个输入、0 到多个输出,代表了特定运算符(operation);而不同节点间“流动”的信息在图中用边表示,称为张量(tensor),TensorFlow 这个名字由此而来,即流动的张量(与之类似的命名还有“跳动的字节”)。张量是具有特定类型的多维数组,支持 8-64 位整型,IEEE float 和 double,half 等多种类型。
一般构建好一个计算图后会反复多次执行,大部分张量都是临时的,不会存活到下一次执行,但上面例子中 tf.Variable 输出的张量是个特例,它返回一个持久的张量,将上一次执行的结果保存至下一次执行,一般用于构建深度模型权重,在迭代训练时不断更新。
下图为 TensorFlow 计算图执行过程。

客户端(client)进程负责构建计算图(graph),创建 tensorflow::Session 实例。客户端一般由 Python 或 C++ 编写。当客户端调用 Session.run() 时将向主进程(master)发送请求,主进程会选择特定工作进程(worker)完成实际计算。客户端、主进程和工作进程可以位于同一台机器实现本地计算,也可以位于不同机器即分布式计算。主进程和工作进程的集合称为服务端(server),一个客户端可以同多个服务端交互。服务端进程会创建 tf.train.Server 实例并持续运行。
TensorFlow 集群(cluster)由一组 jobs 构成,每个 job 可以包含多个 tasks,每个 task 与一个 TensorFlow server 关联。
启动 TensorFlow cluster 时,需要为每个 task 启动一个 TensorFlow server,不同 task 可以运行在不同机器上实现多机分布式训练,也可以运行在相同机器占用不同 GPU 实现单机多 GPU 分布式训练。
每个 task 需要创建 tf.train.ClusterSpec 用于描述集群中所有 task 信息,之后以 tf.train.ClusterSpec 作为参数创建 tf.train.Server。task 可以通过 job 名称和 task 索引来确定身份。
举例说明:
# 创建 server0cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})server0 = tf.train.Server(cluster, task_index=0)server0.join()# 新开一个 terminal,运行下面代码创建 server1cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})server1 = tf.train.Server(cluster, task_index=1)server1.join()
以上代码在同一台机器(localhost)上创建了两个 task,分别与 server0、server1 关联。task 命名分别为:/job:local/task:0 和 /job:local/task:1。两个 server 启动后,会显示
Started server with target: grpc://localhost:2222# 以及Started server with target: grpc://localhost:2223
可见 TensorFlow 本身分布式特性是由 gRPC 支持的。gRPC是一个高性能、开源、通用的远程过程调用(Remote Procedure Call, RPC)框架,提供了一套应用程序间通信机制,客户端调用服务端提供的接口时就像调用本地的函数一样,十分适合实现分布式服务。

如果需要在多个机器上跑多个 task,例如实现上一节的参数服务器架构,cluster 描述为:
tf.train.ClusterSpec({"worker": ["192.168.1.100:2222","192.168.1.101:2222","192.168.1.102:2222"],"ps": ["192.168.1.200:2222","192.168.1.201:2222"]})
创建的 5 个 task 为:
/job:worker/task:0/job:worker/task:1/job:worker/task:2/job:ps/task:0/job:ps/task:1
其中运行在机器 192.168.1.100~192.168.1.102 上的 3 个 task 构成了名为 worker 的 job,运行在机器 192.168.1.200~192.168.1.201 上的 2 个 task 构成了名为 ps 的 job,这 5 个 task、2 个 job 共同组建了一个 cluster。cluster 中的所有 server 都可以互相访问。

接着需要为每个 task 创建 tf.train.Server 对象。每个 server 包含一组本地设备,一组同其他 task 通信的连接,以及一个可以用来执行分布式计算的 tf.Session 对象。以下代码实现了参数服务器架构:
# weights_1 和 biases_1 位于参数服务器 0with tf.device("/job:ps/task:0"):weights_1 = tf.Variable(...)biases_1 = tf.Variable(...)# weights_2 和 biases_2 位于参数服务器 1with tf.device("/job:ps/task:1"):weights_2 = tf.Variable(...)biases_2 = tf.Variable(...)# 计算密集部分位于 worker 节点 2 上with tf.device("/job:worker/task:2"):input, labels = ...layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)# ...train_op = ...# 创建会话,连接到 worker2 实现远程调用with tf.Session("grpc://192.168.1.102:2222") as sess:for _ in range(10000):sess.run(train_op)
在上述代码中,前向计算时 worker2 会从 ps0、ps1 访问权重,梯度更新时 worker2 会将更新量发送给 ps0、ps1。TensorFlow 会自动插入合适的数据传输 op 实现节点间通信。前面 cluster 配置中 worker job 下有 3 个 task,在数据并行方式下,三个 task 会使用同一份权重(位于 ps0、ps1),基于不同数据训练。
TensorFlow 设备命名规则包含了设备类型和 job、task、server 中设备索引等信息。例如“/job:worker/task:2/device:gpu:3” 表示 job 为 worker,task 编号 2,第 3 块 GPU 设备。利用设备命名可以在分布式场景下显式指定模型某些计算部署到哪个节点、哪张 GPU 上,实现更自由、更精细的控制,支持数据并行、模型并行以及混合方式。
4.2 TensorFlow 2.0 分布式实现
TensorFlow 2.0 在多机、多 GPU 分布式方面仍处于不断完善阶段,新增了 tf.distribute.Strategy API,简化了分布式训练配置过程。截止目前,TF 2.0 支持 6 种策略:
-
MirroredStrategy, 适合单机多 GPU,使用 AllReduce 方式同步权重;
-
TPUStrategy,用于 TPU 分布式训练,使用 AllReduce 方式同步权重;
-
MultiWorkerMirroredStrategy,适合多机多 GPU,使用 AllReduce 方式同步权重;
-
CentralStorageStrategy,单机 PS 架构;
-
ParameterServerStrategy, PS 架构,和 TF 1.x 类似,支持权重异步更新;
-
OneDeviceStrategy,单卡模式,只用于调试;
官方推荐使用 Keras 高层次 API,对上述策略支持较好。Estimator API 仅提供有限支持,不建议使用。将 TF 2.0 Keras 代码改为分布式训练时只需创建合适的 tf.distribute.Strategy ,之后将所有 Keras 模型搭建和编译部分置于 strategy.scope 之下,示例代码:
strategy = tf.distribute.MirroredStrategy()with strategy.scope():model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1, ))])model.compile(loss='mse', optimizer='sgd')
对于多机分布式策略 ParameterServerStrategy 和 MultiWorkerMirroredStrategy,需要设置环境变量 TF_CONFIG,内容和 TF 1.x 的 tf.train.ClusterSpec 内容类似。
os.environ['TF_CONFIG'] = json.dumps({'cluster': {'worker': ["host1:port", "host2:port", "host3:port"],'ps': ["host4:port", "host5:port"]},'task': {'type': 'worker', 'index': 0}})
上述配置 'cluster' 字段声明需要创建 3 个 worker 和 2 个 ps 任务,另外新增 'task' 字段还指定了当前任务是 worker,索引为 0。注意只有策略为 ParameterServerStrategy 时 'cluster' 字段中才出现 'ps' 。
整体来看,TensorFlow 2.0 分布式实现继承了 1.x 的特性,同时也在逐步向其他框架如 PyTorch、Keras 借鉴学习,目前仍处于不断开发、优化中。
05
—
Horovod 分布式训练框架

从上一节我们了解到虽然 TensorFlow 本身也支持分布式训练,但 cluster、job、task、server、device 等概念众多,设计复杂,最重要的是分布式训练性能并不理想。如下图所示,TensorFlow 使用 128 块 GPU 进行 InceptionV3、ResNet101 分布式训练加速不到理想值的一半(64),也就是说一大半硬件资源浪费掉了(见空白区域)。

Horovod 【7】是 Uber 开发的利用 Ring-AllReduce 算法实现的分布式训练框架,支持多种机器学习框架如 TensorFlow、MXNet、Keras、PyTorch 等。Horovod 一词来源于俄罗斯民族舞,表演者手挽手围成一圈,和 Ring-AllReduce 架构十分相似。我们前面介绍了 PS 架构和 Ring-AllReduce 架构的区别,PS 在进行多机扩展时中心节点容易遇到 I/O 瓶颈,难以线性扩展,而 Ring-AllReduce 架构采用去中心化的方式,避免了 I/O 瓶颈。下图显示在 128 块 GPU 情况下,Horovod 分布式训练性能相比 TensorFlow 原生分布式方案高出一倍!
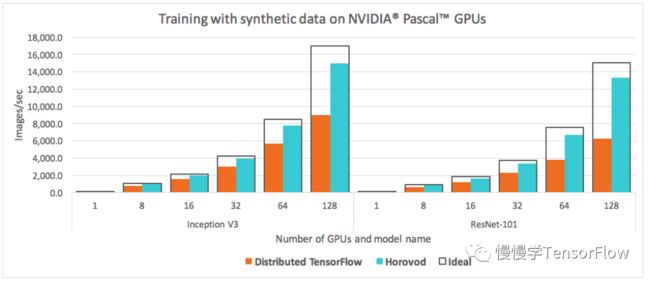
TensorFlow 原生分布式性能差的原因前面第3 节也有介绍,主要是随着训练节点数目增加,PS 节点 I/O 压力越来越大,很容易成为性能瓶颈。Horovod 一方面采用了 Ring-AllReduce 算法做梯度平均,有效利用了节点间通信带宽,另一方面也通过张量融合避免过多的零散 allreduce 运算开销,使得分布式扩展更接近线性加速。
下面举例介绍如何将 TensorFlow 1.x 单机训练代码改为基于 Horovod 实现的多机分布式训练代码。
import tensorflow as tfimport horovod.tensorflow as hvd# 初始化 Horovodhvd.init()# 绑定 GPU 设备config = tf.ConfigProto()config.gpu_options.visible_device_list = str(hvd.local_rank())# 构建模型loss = ...opt = tf.train.AdagradOptimizer(0.01)# 使用 Horovod 分布式优化器opt = hvd.DistributedOptimizer(opt)# 增加钩子函数,用于初始化阶段将 rank 0 权重广播给所有进程hooks = [hvd.BroadcastGlobalVariablesHook(0)]# 构建训练过程train_op = opt.minimize(loss)with tf.train.MonitoredTrainingSession(checkpoint_dir='/tmp/train_logs', config=config, hooks=hooks) as mon_sess:while not mon_sess.should_stop():mon_sess.run(train_op)
运行以下命令启动单机多 GPU 训练,这里使用 4 块 GPU:
# 用 mpirun启动mpirun -np 4 python train.py# 等价命令horovodrun -np 4 -H localhost:4 python train.py
运行以下命令启动多机多 GPU 分布式训练,这里使用 4 个服务器,每个服务器使用 4 块 GPU:
# mpirun 启动mpirun -np 16 -x LD_LIBRARY_PATH \-H server1:4,server2:4,server3:4,server4:4 \python train.py# 等价命令horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
Horovod 同样支持 TF 2.0, 多机分布式代码改动量也不大,示例如下:
import tensorflow as tfimport horovod.tensorflow as hvd# 初始化 Horovodhvd.init()# 绑定 GPU 设备gpus = tf.config.experimental.list_physical_devices('GPU')if gpus:tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')# 构建模型model = ...# 将 tf.GradientTape() 升级为 hvd.DistributedGradientTapewith tf.GradientTape() as tape:probs = model(data, training=True)loss = tf.losses.categorical_crossentropy(target, probs)tape = hvd.DistributedGradientTape(tape, compression=compression)gradients = tape.gradient(loss, model.trainable_variables)opt.apply_gradients(zip(gradients, model.trainable_variables))# 初始化阶段将 rank 0 权重广播给所有进程if first_batch:hvd.broadcast_variables(model.variables, root_rank=0)hvd.broadcast_variables(opt.variables(), root_rank=0)
06
—
TensorFlow2.0 + Horovod 多 GPU 训练实践
硬件环境:
需要一台带有多块 GPU 的服务器,GPU 型号必须一致。如果缺少相应环境,可以到 AWS、阿里云、腾讯云等云厂商临时租用多卡 GPU 实例。以腾讯云 V100 为例,配置如下:
![]()
由于多 GPU 服务器价格较为高昂,预算有限,本节只做单机 8 卡分布式训练。预算充足的读者可以尝试多机分布式训练。需要注意的是,云服务器之间默认不支持 RDMA 通信,如需测试该特性请咨询各个云厂商。
软件环境:
为了简化环境部署,我们利用 NVIDIA GPU Cloud(简称 NGC)【8】搭建本节测试环境。NGC 是针对 GPU 优化的深度学习、机器学习和高性能计算(HPC) 软件中心,方便数据科学家、开发者和研究人员快速构建所需环境。截止目前最新版本 TensorFlow 镜像为 20.01,内置软件版本信息如下:
| 软件名 | 版本信息 |
| NVIDIA CUDA + cuBLAS | 10.2.89 |
| NVIDIA cuDNN | 7.6.5 |
| NVIDIA NCCL | 2.5.6 |
| Horovod | 0.18.2 |
| OpenMPI | 3.1.4 |
为了运行上述 NGC 镜像,需要计算能力 6.0 以上的 GPU,Tesla V100 计算能力为 7.0,符合要求。如果你不确定自己手头显卡是否符合条件,可以运行 CUDA 安装包内置的 deviceQuery 例程查询 Compute Capabilities 一项。
第一步,更新驱动版本为(NGC 推荐)440.33.01:
wget https://cn.download.nvidia.cn/tesla/440.33.01/NVIDIA-Linux-x86_64-440.33.01.runchmod 755 ./NVIDIA-Linux-x86_64-440.33.01.run./NVIDIA-Linux-x86_64-440.33.01.run
第二步,获取 NGC 镜像并启动 docker 实例,使用 TensorFlow 分支,版本号 20.01-tf2-py3,该版本包含了 TensorFlow 2.0 以及上述依赖软件和库:
# 使用 NGC 账号登录docker login nvcr.io# 获取镜像docker pull nvcr.io/nvidia/tensorflow:20.01-tf2-py3nvidia-docker run -ti --rm --shm-size=64G nvcr.io/nvidia/tensorflow:20.01-tf2-py3
第三步,运行 TensorFlow 2.0 + Horovod 单机多 GPU 分布式训练性能评测程序:
git clone https://github.com/horovod/horovod.gitcd horovod/exampleshorovodrun -np 1 -H localhost:1 --mpi python tensorflow2_synthetic_benchmark.pyhorovodrun -np 2 -H localhost:2 --mpi python tensorflow2_synthetic_benchmark.pyhorovodrun -np 4 -H localhost:4 --mpi python tensorflow2_synthetic_benchmark.pyhorovodrun -np 8 -H localhost:8 --mpi python tensorflow2_synthetic_benchmark.py
上述命令分别对 1~8 卡进行 ResNet50 训练速度测试,每张卡 Batch Size 默认为 32,总的 Batch Size 为 32 * GPU 数量。
测试结果如下:
![]()
多 GPU 加速效果:
![]()
从上述测试结果可见,8 卡 V100 相比单卡在深度学习训练速度上有将近 7 倍加速,大大缩短了模型发布所需时间(当然,最大的副作用就是太费钱了)。
07
—
总结
本文首先介绍了深度学习分布式训练原理以及参数服务器、Ring-AllReduce 架构,基于 MPI/NCCL 实现多机、多 GPU 通信的细节。以 Horovod 框架为例介绍了多 GPU 以及分布式训练的实现,最后用实际案例验证采用 8 卡 GPU 方案可以实现 ResNet 50 训练速度提升将近 7 倍,大幅缩短模型发布周期。
08
—
参考文献
【1】 Tesla V100, https://www.nvidia.cn/data-center/v100/
【2】 NCCL, https://developer.nvidia.com/nccl
【3】 Ring-AllReduce, https://github.com/baidu-research/baidu-allreduce
【4】 AlexNet, Image Net Classification with deep convolutional Neural Networks, NIPS 2012
【5】One weird trick for parallelizing convolutional neural networks, 2014
【6】 TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, 2015
【7】 Horovod,https://eng.uber.com/horovod/
【8】 NGC, https://www.nvidia.cn/gpu-cloud/