大数据面试题分享:大数据职位面试需要知道的知识
在面试大数据职位的时候,你会遇到多种问题(hdfs、map reduce、zookeeper、hadoop、hbase等等),当时你的内心是崩溃的。写下这篇文章的意义是提高你的面试成功率,让你用出洪荒之力,职业生涯进一步发展。
1. hdfs原理,以及各个模块的职责
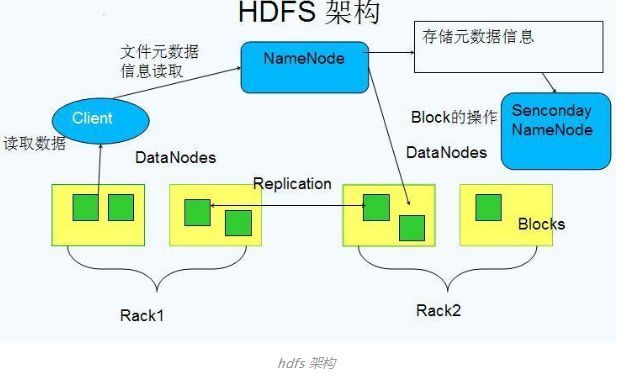
Namenode 的目录结构:

很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习qq群:458345782,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系
对于 任何对文件系统元数据产生修改 的操作, Namenode 都会使用一种称为 EditLog 的事务日志记录下来。
整个文件系统的命名空间 ,包括数据块到文件的映射、文件的属性等,都存储在一个称为 FsImage 的文件中
DataNode
Datanode 将 HDFS 数据以文件的形式存储在本地的文件系统中,它并不知道有关 HDFS 文件的信息。它把每个 HDFS 数据块存储在本地文件系统的一个单独的文件中。
当一个 Datanode 启动时,它会扫描本地文件系统,产生一个这些本地文件对应的所有 HDFS 数据块的列表,然后作为报告发送到 Namenode ,这个报告就是块状态报告。
Secondary NameNode
Secondary NameNode 定期合并 fsimage 和 edits 日志,将 edits 日志文件大小控制在一个限度下。
Secondary NameNode处理流程
(1) 、 namenode 响应 Secondary namenode 请求,将 edit log 推送给 Secondary namenode , 开始重新写一个新的 edit log 。
(2) 、 Secondary namenode 收到来自 namenode 的 fsimage 文件和 edit log 。
(3) 、 Secondary namenode 将 fsimage 加载到内存,应用 edit log , 并生成一 个新的 fsimage 文件。
(4) 、 Secondary namenode 将新的 fsimage 推送给 Namenode 。
(5) 、 Namenode 用新的 fsimage 取代旧的 fsimage , 在 fstime 文件中记下检查 点发生的时
HDFS的安全模式
Namenode 启动后会进入一个称为安全模式的特殊状态。处于安全模式 的 Namenode 是不会进行数据块的复制的。 Namenode 从所有的 Datanode 接收心跳信号和块状态报告。块状态报告包括了某个 Datanode 所有的数据 块列表。每个数据块都有一个指定的最小副本数。当 Namenode 检测确认某 个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全 (safely replicated) 的;在一定百分比(这个参数可配置)的数据块被 Namenode 检测确认是安全之后(加上一个额外的 30 秒等待时间), Namenode 将退出安全模式状态。接下来它会确定还有哪些数据块的副本没 有达到指定数目,并将这些数据块复制到其他 Datanode 上。
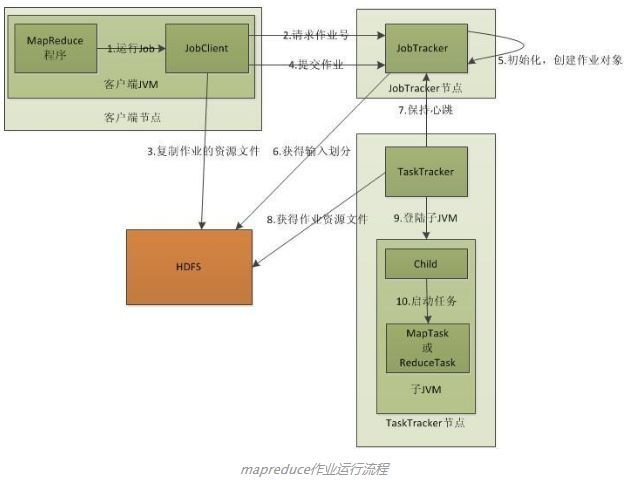
2. map reduce 的工作原理

3. hadoop1 与 hadoop2 的区别
见 hadoop面试
4. zookeeper
Zookeeper中的角色主要有以下三类
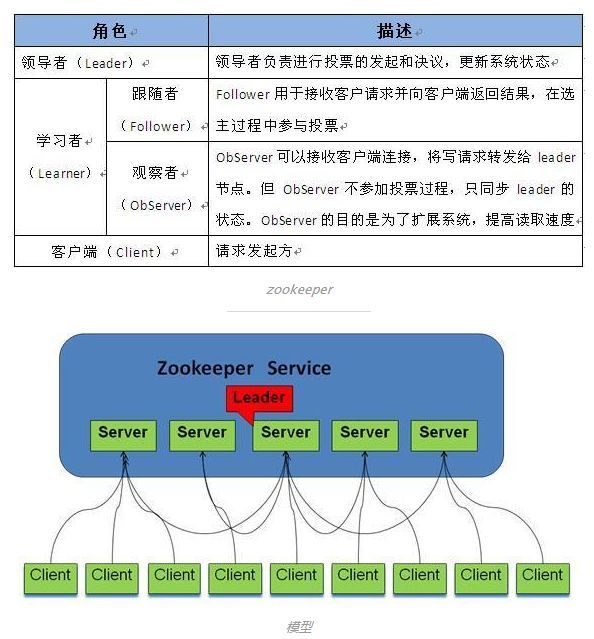
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。
5. hbase
HBase是一个构建在HDFS上的分布式列存储系统;
HBase是基于Google BigTable模型开发的,典型的key/value系统;
HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储。
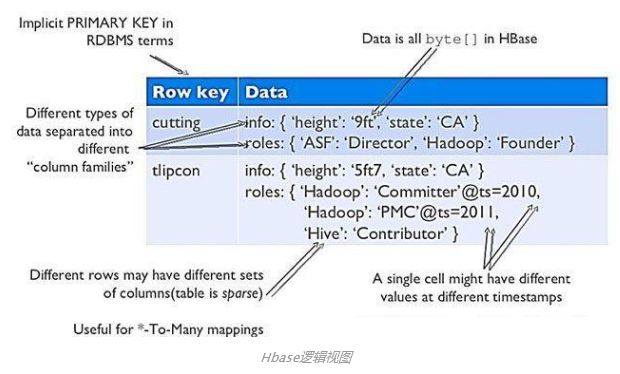
多级索引:
物理存储:
Table在行的方向上分割为多个Region。
Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阈值的时候,region就会等分会两个新的region,之后会有越来越多的region。
Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。
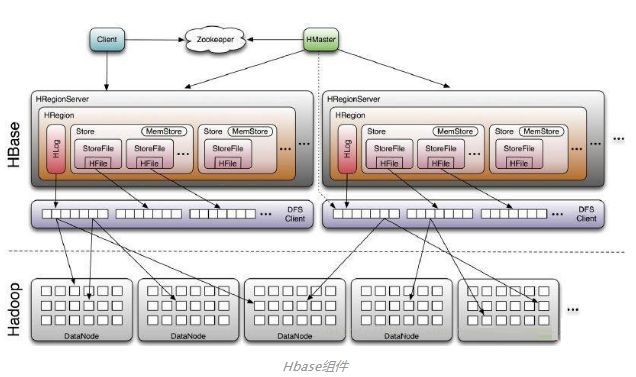
Client
包含访问HBase的接口,并维护cache来加快对HBase的访问,比如region的位置信息
Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改查操作
Region Server
Regionserver维护region,处理对这些region的IO请求
Regionserver负责切分在运行过程中变得过大的region
Zookeeper作用
通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
存贮所有Region的寻址入口
实时监控Region server的上线和下线信息。并实时通知给Master
存储HBase的schema和table元数据
默认情况下,HBase 管理ZooKeeper 实例,比如, 启动或者停止ZooKeeper
Zookeeper的引入使得Master不再是单点故障
Master容错:Zookeeper重新选择一个新的Master
RegionServer容错:定时向Zookeeper汇报心跳
很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习qq群:458345782,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系