基于Hive的大数据实战项目
目录
一、项目需求
二、数据介绍
三、创建表结构
四、数据清洗
五、数据加载
六、业务数据分析
七、原始数据
一、项目需求
1.统计视频观看数 Top10
2.统计视频类别热度Top10
3.统计出视频观看数最高的20个视频的所属类别以及类别包含这Top20视频的个数
4.统计视频观看数Top50所关联视频的所属类别的热度排名
5.统计每个类别中的视频热度Top10,以 Music为例
6.统计每个类别中视频流量 Top10 ,以 Music为例
7.统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
8.统计每个类别视频观看数Top10(分组取topN)
二、数据介绍
1.视频数据表:

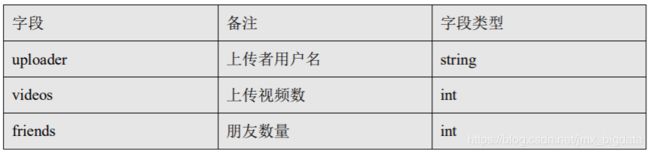
2.用户表:
三、创建表结构
1.视频表:
create table youtube_ori(
videoId string,
uploader string,
age int,
category array,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array)
row format delimited
fields terminated by "\t"
collection items terminated by "&" ; create table youtube_orc(
videoId string,
uploader string,
age int,
category array,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array)
clustered by (uploader) into 8 buckets
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as orc; 2.用户表:
create table youtube_user_ori(
uploader string,
videos int,
friends int)
clustered by (uploader) into 24 buckets
row format delimited fields terminated by "\t";create table youtube_user_orc(
uploader string,
videos int,
friends int)
clustered by (uploader) into 24 buckets
row format delimited fields terminated by "\t"
stored as orc;四、数据清洗
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割, 且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“\t”进 行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清 洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频 id 也使用“&” 进行分割。
1.ETLUtil
package com.company.sparksql;
public class ETLUtil {
public static String oriString2ETLString(String ori){
StringBuilder etlString = new StringBuilder();
String[] splits = ori.split("\t");
if(splits.length < 9) return null;
splits[3] = splits[3].replace(" ", "");
for(int i = 0; i < splits.length; i++){
if(i < 9){
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "\t");
}
}else{
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "&");
}
}
}
return etlString.toString();
}
}
2.DataCleaner
package com.company.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object DataCleaner {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName(DataCleaner.getClass.getSimpleName)
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
val lineDS = spark.read.textFile("e:/0.txt")
import spark.implicits._
val splitedDS = lineDS.map(ETLUtil.oriString2ETLString(_))
splitedDS.write.format("text").save("e:/movie")
}
}五、数据加载
1.视频表:
加载清洗之后的数据到原始视频表
load data local inpath "/opt/datas/cleaned.txt" into table youtube_ori;加载数据到视频的ORC表
insert overwrite table youtube_orc select * from youtube_ori;2用户表:
加载清洗之后的数据到原始用户表
load data local inpath "/opt/datas/user.txt" into table user_ori;加载数据到用户的ORC表
insert overwrite table user_orc select * from user_ori;六、业务数据分析
1.统计视频观看数 Top10
select
videoId,
uploader,
age ,
category ,
length ,
views ,
rate ,
ratings ,
comments
from youtube_orc
order by views desc
limit 10;2.统计视频类别热度Top10
第一种方式:select
category_name,
count(videoId) as video_num
from youtube_orc lateral view explode(category) youtube_view as category_name
group by category_name
order by video_num desc
limit 10;
第二种方式:select category_name as category,
count(t1.videoId) as hot
from (select
videoId,
category_name
from youtube_orc lateral view explode(category) t_catetory as category_name) t1
group by t1.category_name
order by hot desc
limit 10;3.统计出视频观看数最高的20个视频的所属类别以及类别包含这Top20视频的个数
select category_name,
count(videoId) as videonums
from (
select
videoId,
category_name
from
(select
category,
videoId,
views
from
youtube_orc
order by views desc
limit 20) top20view lateral view explode(category) t1_view as category_name )t2_alias group by category_name order by videonums desc;4.统计视频观看数Top50所关联视频的所属类别的热度排名
select
category_name,
count(relatedvideoId) as hot
from
(select
relatedvideoId,
category
from
(select
distinct relatedvideoId
from (select
views,
relatedId
from
youtube_orc
order by views desc
limit 50 )t1 lateral view explode(relatedId) explode_viedeo as relatedvideoId)t2 join youtube_orc on youtube_orc.videoId = t2.relatedvideoId)t3 lateral view explode(category) explode_category as category_name
group by category_name
order by hot desc;5.统计每个类别中的视频热度Top10,以 Music为例
select
videoId,
views
from youtube_orc lateral view explode(category) t1_view as category_name
where category_name = "Music"
order by views desc
limit 10 ; 6.统计每个类别中视频流量 Top10 ,以 Music为例
select
videoId ,
ratings
from youtube_orc lateral view explode(category) t1_view as category_name
where category_name = "Music"
order by ratings desc
limit 10 ;7.统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
select t1.uploader,youtube_orc.videoId,youtube_orc.views
from
(select
uploader,videos
from youtube_user_orc
order by videos desc
limit 10) t1 inner join youtube_orc on t1.uploader = youtube_orc.uploader order by views desc limit 20 ; 8.统计每个类别视频观看数Top10(分组取topN)
select
t2_alias.category_name,
t2_alias.videoId,t2_alias.views
from
(
select
category_name,
videoId,views ,
row_number() over(partition by category_name order by views desc) rank
from
youtube_orc lateral view explode(category) t1_view as category_name ) t2_alias where rank <= 10;七、原始数据
1.视频表
2.用户表
3.清洗之后的视频表
链接:https://pan.baidu.com/s/1OkQ2E5_KCngVRbTkalodrQ
提取码:yzk7