多分类问题的性能评价指标 f1-score
本文主要从二分类开始说起,介绍多分类问题的性能评价指标 f1-score
首先,先给出二分类问题 f 1 − s c o r e f1-score f1−score的计算公式,
f 1 − s c o r e = 1 1 2 ( 1 P + 1 R ) = 2 P R P + R f1-score = \frac{1}{\frac{1}{2}(\frac{1}{P}+\frac{1}{R})}=\frac{2PR}{P+R} f1−score=21(P1+R1)1=P+R2PR P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
其中 P P P叫做查准率precision, R R R叫做查全率recall。
分类结果的混淆矩阵如下,
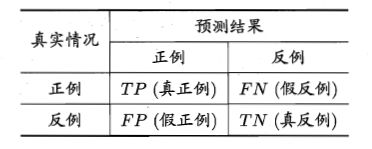
对于 T P , T N , F P , F N TP,TN,FP,FN TP,TN,FP,FN怎么去理解呢? T T T或者 F F F表示分类器是分对了还是分错了,分对了就是 T T T,分错了就是 F F F; P P P或者 N N N表示分类器把该样本分成了什么,分成了正例就是 P P P,分成了负例就是 N N N。以 F P FP FP为例,表示分类器把该样本分错了,并且把它分成了正例。
那么 P P P和 R R R怎么理解呢?以好坏瓜的分类为例, P P P表示被分类器分成好瓜的样本中确实是好瓜的比例; R R R表示所有的好瓜中被分类器分成是好瓜的比例。
所以,如果 P P P很高, R R R很小,说明分类器太过谨慎,只把有很大把握认为是好瓜的样本才确认为是好瓜;反之,如果 P P P很小, R R R很高,说明分类器就是"宁愿错杀三千,也不漏过一个"。这两种情况显然都不是一个好的分类器。
所以我们希望能够有一个 P P P和 R R R都比较高的分类器,那么我们怎样通过 P P P和 R R R来量化分类器的性能呢?类似于ROC-AUC,可以使用P-R曲线下面积来表示分类器的性能。面积越大的表示分类器性能越好,但是一般这个面积不太好求,所以引入了开头提到的 f 1 − s c o r e f1-score f1−score的概念, f 1 − s c o r e f1-score f1−score越接近1,分类器性能越好。
上述是对于二分类问题 f 1 − s c o r e f1-score f1−score的求法,那么对于多分类问题呢?一般多分类的问题的处理方法是"ovo"或者"ovr",分别会存在 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)或者 n n n个混淆矩阵,那么我们如何在 m m m个混淆矩阵上求 f 1 − s c o r e f1-score f1−score呢?
有两种作法,分别是 m a c r o − F 1 macro-F1 macro−F1以及 m i c r o − F 1 micro-F1 micro−F1
macro-F1
对各个 P i P_i Pi和 R i R_i Ri求平均,再求 F 1 F1 F1
m a c r o − P = 1 m Σ i P i macro-P=\frac{1}{m}\Sigma_i P_i macro−P=m1ΣiPi m a c r o − R = 1 m Σ i R i macro-R=\frac{1}{m}\Sigma_i R_i macro−R=m1ΣiRi m a c r o − F 1 = 2 ∗ m a c r o − P ∗ m a c r o − R m a c r o − P + m a c r o − R macro-F1 =\frac{2*macro-P*macro-R}{macro-P+macro-R} macro−F1=macro−P+macro−R2∗macro−P∗macro−R
micro-F1
对各个 T P , T N , F P , F N TP,TN,FP,FN TP,TN,FP,FN求平均,再求 P , R , F 1 P,R,F1 P,R,F1
m i c r o − P = T P ˉ T P ˉ + F P ˉ micro-P=\frac{\bar {TP}}{\bar {TP}+\bar {FP}} micro−P=TPˉ+FPˉTPˉ m i c r o − R = T P ˉ T P ˉ + F N ˉ micro-R=\frac{\bar{TP}}{\bar{TP} + \bar{FN}} micro−R=TPˉ+FNˉTPˉ m i c r o − F 1 = 2 ∗ m i c r o − P ∗ m i c r o − R m i c r o − P + m i c r o − R micro-F1 =\frac{2*micro-P*micro-R}{micro-P+micro-R} micro−F1=micro−P+micro−R2∗micro−P∗micro−R
m a c r o − F 1 macro-F1 macro−F1以及 m i c r o − F 1 micro-F1 micro−F1也是越接近1越好。
sklearn接口
在 sklearn 中也提供了计算 f 1 − s c o r e f1-score f1−score的接口,官网给出的实例如下,
>>> from sklearn.metrics import f1_score
>>> y_true = [0, 1, 2, 0, 1, 2]
>>> y_pred = [0, 2, 1, 0, 0, 1]
>>> f1_score(y_true, y_pred, average='macro')
0.26...
>>> f1_score(y_true, y_pred, average='micro')
0.33...
可见上述接口求 m i c r o − F 1 micro-F1 micro−F1和 m a c r o − F 1 macro-F1 macro−F1的时候,都是建立了n个混淆矩阵,每个混淆矩阵是把一个类当作正例,其他的类当负例求出 T P , T N , F P , F N TP,TN,FP,FN TP,TN,FP,FN的值,再按照之前介绍的方法,求出 F 1 F1 F1的值。
参考资料:
《机器学习》周志华
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score