1.安装环境说明
- 本机操作系统macOS Sierra 10.12.6
- 采用的虚拟机VirtualBox 5.1.28
- 虚拟机镜像CentOS 7 64bit
2.为什么要编译
因为我们从官方下载的Hadoop安装压缩包(hadoop-2.7.4.tar.gz)是32位系统下的,如果我们将它部署在64位的系统上运行就会报错,所以我们最好在自己的64位系统上自己重新编译Hadoop源码(hadoop-2.7.4-src.tar.gz)(也可以从网上下载他人编译好的Hadoop64位安装包)。
3.编译前的准备
3.1删除预安装的openjdk(如果有)
3.1.1查看是否安装了openjdk
[root@localhost ~]# java -version
openjdk version "1.8.0_65"
OpenJDK Runtime Environment (build 1.8.0_65-b17)
OpenJDK 64-Bit Server VM (build 25.65-b01, mixed mode)
3.1.2查看openjdk源
[root@localhost ~]# rpm -qa | grep java
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
tzdata-java-2015g-1.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
3.1.3依次删除OPENJDK
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
[root@localhost ~]# rpm -e --nodeps tzdata-java-2015g-1.el7.noarch
[root@localhost ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
3.2关闭防火墙
3.2.1查看防火墙的状态
[root@localhost ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2017-10-19 14:45:46 CST; 22min ago
Main PID: 607 (firewalld)
CGroup: /system.slice/firewalld.service
└─607 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
Oct 19 14:45:44 localhost.localdomain systemd[1]: Starting firewalld - dynami...
Oct 19 14:45:46 localhost.localdomain systemd[1]: Started firewalld - dynamic...
Hint: Some lines were ellipsized, use -l to show in full.
3.2.2关闭防火墙
[root@localhost ~]# systemctl stop firewalld.service
3.2.2禁止防火墙开机自启
[root@localhost ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
Removed symlink /etc/systemd/system/basic.target.wants/firewalld.service.
3.3编译环境搭建
3.3.1上传所需要的软件安装压缩包
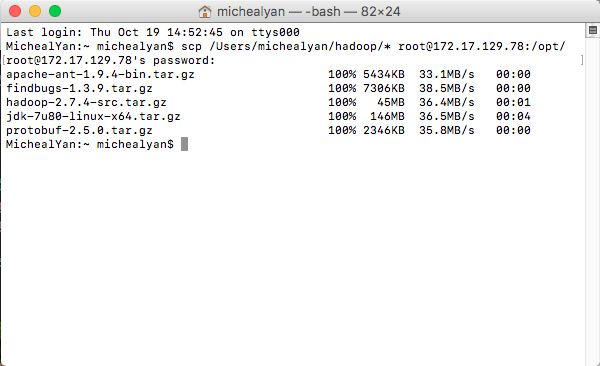
示例:Mac在终端使用scp命令上传本地hadoop目录下的所有软件包到虚拟机的/opt/目录下
3.3.2解压所有的软件到/opt目录下
使用命令tar -zxvf 软件包位置 -C 解压到的路径,例如:
[root@localhost opt]# tar -zxvf /opt/apache-ant-1.9.4-bin.tar.gz -C /opt/
3.3.3安装java、ant和findbugs
1.配置环境变量,修改配置文件[root@localhost opt]# vi /etc/profile,在末尾添加
export JAVA_HOME=/opt/jdk1.7.0_80
export ANT_HOME=/opt/apache-ant-1.9.4
export FINDBUGS_HOME=/opt/findbugs-1.3.9
export PATH=$PATH:$FINDBUGS_HOME/bin:$ANT_HOME/bin:$JAVA_HOME/bin
2.使配置文件生效[root@localhost opt]# source /etc/profile
3.验证是否安装成功
[root@localhost opt]# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
[root@localhost opt]# ant -version
Apache Ant(TM) version 1.9.4 compiled on April 29 2014
[root@localhost opt]# findbugs -version
1.3.9
3.3.4安装protobuf
1.安装一些其他需要依赖的软件(虚拟机需要联网)
[root@localhost ~]# yum -y install maven svn ncurses-devel gcc* lzo-devel zlib-devel autoconf automake libtool cmake openssl-devel
2.安装protobuf,最后一条命令输入后需要耐心等待
[root@localhost ~]# cd /opt/protobuf-2.5.0
[root@localhost protobuf-2.5.0]# ./configure
[root@localhost protobuf-2.5.0]#make && make install
3.验证是否安装成功
[root@localhost protobuf-2.5.0]# protoc --version
libprotoc 2.5.0
4.编译hadoop源码
1.进入hadoop源码的根目录,执行编译命令(编译过程需联网)
[root@localhost ~]# cd /opt/hadoop-2.7.4-src
[root@localhost hadoop-2.7.4-src]# mvn clean package -Pdist -DskipTests -Dtar
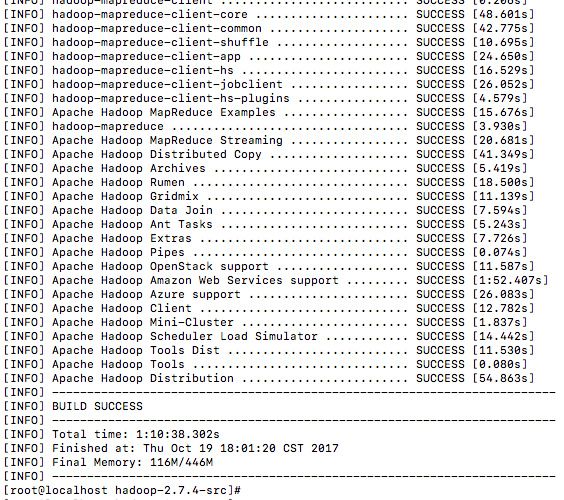
2.编译过程时间很长,需耐心等待
3.编译成功如下图所示
5.安装hadoop
1.复制编译生成的Hadoop文件至/opt/目录下
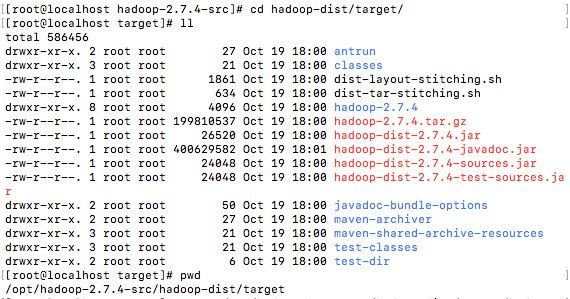
[root@localhost ~]# cp -r /opt/hadoop-2.7.4-src/hadoop-dist/target/hadoop-2.7.4 /opt/hadoop-2.7.4
编译生成目录截图
2.配置环境变量
[root@localhost opt]# vi /etc/profile
在末尾添加
export HADOOP_HOME=/opt/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@localhost opt]# source /etc/profile
3.修改主机名为hadoop,会在后面修改hadoop的配置文件中用到
[root@localhost ~]# hostnamectl set-hostname hadoop
[root@localhost ~]# hostnamectl status
Static hostname: hadoop
Icon name: computer-vm
Chassis: vm
Machine ID: ca98320ca97f4fbebdb7d5a4bd32c052
Boot ID: 6953000caef747c6a65be85f40921f0e
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-327.el7.x86_64
Architecture: x86-64
4.查看当前IP地址
[root@localhost ~]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:6e:65:f5 brd ff:ff:ff:ff:ff:ff
inet 192.168.43.216/24 brd 192.168.43.255 scope global dynamic enp0s3
valid_lft 3524sec preferred_lft 3524sec
inet6 fe80::a00:27ff:fe6e:65f5/64 scope link
valid_lft forever preferred_lft forever
5.设置hosts本地解析,添加主机名和当前ip进行映射关系
[root@localhost ~]# vi /etc/hosts
在末尾添加
#当前IP地址 主机名
192.168.43.216 hadoop
6.配置hadoop,伪分布式需要修改5个配置文件
(1)进入配置文件目录
[root@localhost ~]# cd /opt/hadoop-2.7.4/etc/hadoop
(2)修改第一个配置文件:hadoop-env.sh
[root@localhost hadoop]# vi hadoop-env.sh
找到‘export JAVA_HOME=’,修改为:
export JAVA_HOME=/opt/jdk1.7.0_80
(3)修改第二个配置文件:core-site.xml
[root@localhost hadoop]# vi core-site.xml
fs.defaultFS
hdfs://hadoop:9000
hadoop.tmp.dir
/opt/hadoop-2.7.4/tmp
(4)修改第三个配置文件:hdfs-site.xml
[root@localhost hadoop]# vi hdfs-site.xml
dfs.replication
1
(5)修改第四个配置文件:mapred-site.xml
[root@localhost hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@localhost hadoop]# vi mapred-site.xml
mapreduce.framework.name
yarn
(6)修改第五个配置文件:yarn-site.xml
[root@localhost hadoop]# vi yarn-site.xml
yarn.resourcemanager.hostname
hadoop
yarn.nodemanager.aux-services
mapreduce_shuffle
6.运行hadoop
1.首次运行需要格式化namenode(是对namenode进行初始化
[root@localhost ~]# hdfs namenode -format (或 hadoop namenode -format)
2.启动hadoop
先启动HDFS
[root@localhost ~]# start-dfs.sh
再启动YARN
[root@localhost ~]# start-yarn.sh
3.验证是否启动成功
[root@localhost ~]# jps
12880 SecondaryNameNode
13025 ResourceManager
12725 DataNode
13305 NodeManager
13353 Jps
12607 NameNode
4.使用浏览器查看HDFS管理界面和MR管理界面
http://虚拟机IP地址:50070 (HDFS管理界面)
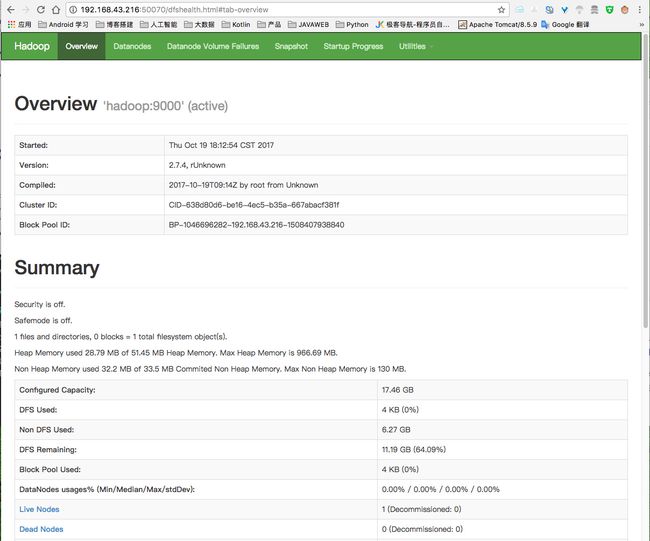
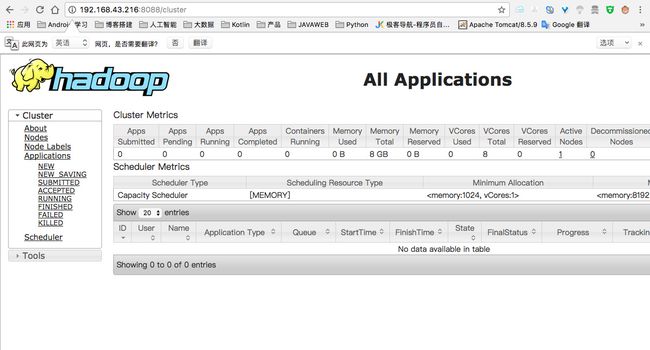
http://虚拟机IP地址:8088 (MR管理界面)
7.总结
7.1创建虚拟机的一些注意事项
- 创建的虚拟机的内存大小和虚拟硬盘大小不要设置的太小,否则会引起一些不必要的麻烦。比如,如果虚拟机内存太小,则在后面编译Hadoop的mavn项目的时候,就有可能产生内存溢出而编译失败的情况。(我创建的时候分配了2G的内存和20G的虚拟硬盘)
- 虚拟机网络设置,由于安装编译的过程需要联网,所以我是用了桥接的方式,并且没有设置静态IP,所以搭建成功后每次运行hadoop前,都需要先查看当前的IP地址,然后修改主机名和IP地址的映射关系,才能正常运行。
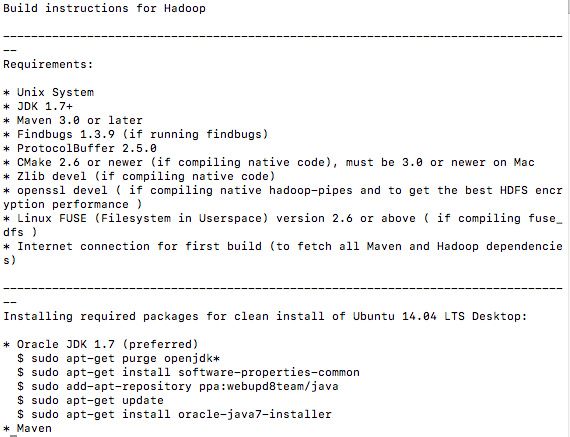
7.2编译其他版本的hadoop
大致的编译过程基本上是一致的,只不过用到的相关依赖软件的版本号,需要从hadoop源码包的根目录中的BUILDING.txt文件中查看。下图是部分内容截图:
7.3配置ssh免登陆(可选)
按上述方式搭建好hadoop后,每次运行除了要修改修改主机名和IP地址的映射关系外(通过设置静态IP解决),在每次执行start-dfs.sh和start-yarn.sh脚本的时候,都要输入Linux的登入密码。我们可以通过配置ssh免登陆的方式,来避免每次都要输入密码。
配置方式:
1.生成ssh公钥和私钥,执行下面的命令并连续按下回车三次
[root@localhost ~]# ssh-keygen -t rsa
2.将公钥拷贝到要免密登陆的目标机器上(localhost 本机)
[root@localhost ~]# ssh-copy-id localhost
7.4设置静态ip(可选)
- 通过
ip a命令查看网卡名称,默认情况下会有两个一个lo回环网卡,而另一个就是我们所需要修改的网卡 - 修改网卡的配置文件方式
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-网卡名
修改或添加下面的内容
BOOTPROTO="static"
ONBOOT="yes"
IPADDR="设置一个静态ip"
NETMASK="255.255.255.0"
7.5推荐使用远程连接的方式来操作
- Windows推荐使用secureCRT,进行操作和上传文件
- MacOS推荐使用终端,使用ssh命令进行连接执行命令,使用scp命令上传和下载文件,eg:
远程连接linux虚拟机
$ ssh [email protected]
上传本地文件到linux虚拟机
$ scp /Users/michealyan/hadoop/* [email protected]:/opt/
7.6其他说明
1.所用的到相关软件下载地址:飞机
2.参考链接:
CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装
https://my.oschina.net/u/1428349/blog/31364
Hadoop编译安装2.7.3(CentOS7)
https://www.2cto.com/net/201612/567546.html
3.仅供参考,欢迎指正