【编译原理】语法分析(三)
常用的语法分析方法包括自顶向下和自底向上的方法,在上一篇文章中已经介绍了自顶向下的语法分析方法,本文将介绍自底向上的语法分析方法。
文法&约定
按照惯例,我们给出一个贯穿全文的表达式文法G:
E→E+T|T
T→T*F|F
F→(E)|id以及使用的符号约定:
- 大写字母:表示非终结符号,如A、B、C等;
- 小写字母:表示终结符号,如a、b、c等;
- 希腊字母:表示由终结符号和非终结符号组成的串或者空串,如α、β、γ、ω等;
- 开始符号:用S表示文法的开始符号;
- 结束符号:用$表示结束标记,如输入结束、栈为空等;
- 空串:用ε表示长度为0的串,即空串。
自底向上的语法分析
顾名思义,自底向上的语法分析过程对应于为一个输入串构造语法分析树的过程,它从叶子结点开始逐渐向上到达根结点。和自顶向下的语法分析过程相反,自底向上的语法分析过程把几个叶子结点或中间结点归约成一个中间结点,每次归约是一次最右推导的逆过程,当完成一次自底向上的语法分析后,对相应的输入串可以得到一个反向的最右推导。
句柄
对文法G和输入串id*id,我们使用自底向上的方法构造它的语法分析树:

如果从最右边的语法分析树开始,到最左边的语法分析树为止,把每棵语法分析树的根结点用![]() 符号连接起来,那么就可以得到串
符号连接起来,那么就可以得到串id*id的一个最右推导:
E![]()
T![]()
T*F![]()
T*id![]()
F*id![]()
id*id
也就是说,对串id*id的自底向上的语法分析过程就是从id*id开始,经过一次次归约,最终得到E的过程。其中,每次归约是某个最右推导的逆过程。
自底向上的语法分析的关键问题是确定每次对哪一个串进行归约,我们把这个串叫作句柄。正式地,如果S![]() …
…![]() αAγ
αAγ![]() αβγ,那么产生式A→β是αβγ的一个句柄,可以把A→β化简为β,即说β是αβγ的一个句柄。
αβγ,那么产生式A→β是αβγ的一个句柄,可以把A→β化简为β,即说β是αβγ的一个句柄。
对上面得到的串id*id的最右推导,因为有F*id![]()
id*id,所以第一个id是id*id的一个句柄;又因为有T*id![]()
F*id,所以F是F*id的一个句柄;依此类推。
这样的话,对一个输入串ω,假设它的一个最右推导为S![]() α1
α1![]() α2
α2![]() …
…![]() αn
αn![]() ω,如果我们能知道所有αi(1<=i<=n)和ω的一个句柄,就能使用自底向上的方法构造ω的语法分析树。
ω,如果我们能知道所有αi(1<=i<=n)和ω的一个句柄,就能使用自底向上的方法构造ω的语法分析树。
注意,对某个串可能有不止一个句柄,例如二义性文法。
移入-归约语法分析技术
移入-归约语法分析是一种通用的自底向上的语法分析技术。它使用一个栈来保存文法符号,并用一个输入缓冲区存放剩余的输入符号,使用这种方法时,句柄在被识别之前都出现在栈顶。
一个移入-归约语法分析器可以执行四种动作:
- 移入:将下一个输入符号压入栈顶;
- 归约:被归约的符号串的右端必然是栈顶,语法分析器在栈中确定这个串的左端,并决定用哪个非终结符号来替换这个串;
- 接受:宣布语法分析过程成功完成;
- 报错:发现一个语法错误,并调用一个错误恢复子例程。
对输入串id*id,它的一个移入-归约语法分析过程如下:

在上图中,栈的顶部在右边,并且每次句柄出现时都在栈顶。这里我们并没有介绍什么时候执行移入,什么时候执行归约,即如何识别一个句柄。下一节内容将介绍一种发现句柄的方法。
另外,还需要注意的是,在移入-归约语法分析过程中,可能会产生冲突,包括移入/归约冲突和归约/归约冲突。移入/归约冲突是指在移入-归约语法分析的某一步中,既可以执行移入动作,也可以执行归约动作,从而发生的冲突。归约/归约冲突是指在移入-归约语法分析的某一步中,栈顶的句柄可以选择归约成两个或多个产生式头,从而发生的冲突。
简单LR技术:SLR
目前最流行的自底向上的语法分析器都基于所谓的LR(k)语法分析的概念。其中,“L”表示对输入进行从左到右的扫描,“R”表示反向构造一个最右推导序列,“k”表示在做出语法分析决定时向前看k个输入符号。当省略(k)时,假设k=1。
本节将介绍简单LR技术(简称为SLR),它是一种最简单的构造移入-归约语法分析器的方法。SLR依赖于一张语法分析表,该语法分析表包括ACTION和GOTO集合,它们是根据LR(0)自动机得到的,一个LR(0)自动机由一个状态集合和一个转移函数组成。
规范LR(0)项和LR(0)自动机
一个LR语法分析器通过维护一些状态,用这些状态来表明在语法分析过程中所处的位置,从而做出移入-归约决定。
一个文法的一个LR(0)项(简称为项)是该文法的一个产生式加上一个位于它的体中某处的点。举个例子,对产生式A→αβγ来说,它有四个项,分别为A→·αβγ、A→α·βγ、A→αβ·γ和A→αβγ·。项A→·αβγ表明我们希望在接下来的输入中看到一个可以从αβγ推导得到的串;项A→α·βγ表明我们刚刚在输入中看到了一个可以从α推导得到的串,并且我们希望在接下来的输入中看到一个可以从βγ推导得到的串;项A→αβγ·表明我们已经在输入中看到了一个可以从αβγ推导得到的串,并且是时候把这个串归约为A了。
一个或多个项可以组成一个项集,而一组项集提供了构建一个DFA的基础,这个DFA可用于做出语法分析决定,这样的DFA称为LR(0)自动机。
LR(0)自动机的每个状态代表一个项集。为了确定LR(0)自动机的每个状态代表的项集中包含哪些项,我们需要用到两个函数CLOSURE和GOTO,这两个函数的作用有点类似于DFA的ε-closure和move函数。
对文法的一个项集I,CLOSURE(I)的构造规则如下:
- 把I中的所有项加入CLOSURE(I)中;
- 如果A→α·Bβ在CLOSURE(I)中,B→γ是一个产生式,并且B→·γ不在不在CLOSURE(I)中,就把项B→·γ加入CLOSURE(I)中。不断应用这个规则,直到没有新项可以加入CLOSURE(I)中为止。
对文法G,计算项集{ E→·E+T }的CLOSURE集合的过程如下:
- 把项
E→·E+T加入CLOSURE集合中; - 由于
E→T是一个产生式,且E→·T不在CLOSURE集合中,因此把它加入CLOSURE集合中; - 由于
T→T*F|F是一个产生式,且T→·T*F和T→·F都不在CLOSURE集合中,因此把它们加入CLOSURE集合中; - 由于
F→(E)|id是一个产生式,且F→·(E)和F→·id都不在CLOSURE集合中,因此把它们加入CLOSURE集合中。到此,已经没有新的项可以加入CLOSURE集合中,最终的CLOSURE集合为:
E→·E+T
E→·T
T→·T*F
T→·F
F→·(E)
F→·id对文法的一个项集I和一个文法符号X,GOTO(I, X)的构造规则如下:
- 如果A→α·Xβ在I中,就把项A→αX·β加入GOTO(I, X)中;
- 把GOTO(I, X)作为CLOSURE函数的参数,计算GOTO(I, X)的闭包。
对上面得到的项集{ E→·E+T }的CLOSURE集合和符号“(”,计算它的GOTO集合的过程如下:
- 把项
F→(·E)加入GOTO集合中; - 由于
E→E+T|T是一个产生式,且E→·E+T和E→·T都不在GOTO集合中,因此把它们加入GOTO集合中; - 由于
T→T*F|F是一个产生式,且T→·T*F和T→·F都不在GOTO集合中,因此把它们加入GOTO集合中; - 由于
F→(E)|id是一个产生式,且F→·(E)和F→·id都不在GOTO集合中,因此把它们加入GOTO集合中。到此,已经没有新的项可以加入GOTO集合中,最终的GOTO集合为:
F→(·E)
E→·E+T
E→·T
T→·T*F
T→·F
F→·(E)
F→·id到此,我们已经知道如何确定LR(0)自动机的每个状态(CLOSURE函数)和转移函数(GOTO函数)。另外,为了规范一个文法的LR(0)自动机,我们把该文法表示为一个增广文法,即在该文法中加入新的开始符号S’和产生式S’→S得到的文法。引入这个新的开始符号和产生式的目的是告诉语法分析器何时应该停止语法分析并宣称接受输入符号串。也就是说,当且仅当语法分析器使用S’→S进行归约时,输入符号串被接受。
文法G的增广文法的LR(0)自动机如下:
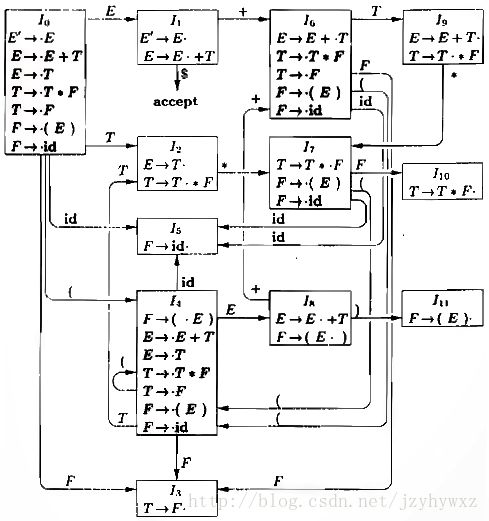
LR(0)自动机是如何帮助做出移入-归约决定的呢?假设串γ使LR(0)自动机从开始状态0运行到某个状态j,如果下一个输入符号为a且状态j有一个在a上的转换,就移入a,否则进行归约操作,状态j的项将告诉我们使用哪个产生式进行归约。
对文法G和输入串id*id,使用上面给出的文法G的LR(0)自动机对它进行移入-归约语法分析的过程如下:

实际上,在一个LR语法分析器中,LR(0)自动机会被转换成一张LR语法分析表,在下一小节中,我们继续介绍如何从LR(0)自动机构建LR语法分析表。
LR语法分析表
一个LR语法分析器的语法分析表由一个语法分析动作函数ACTION和一个转换函数GOTO组成:
- ACTION函数:ACTION函数有两个参数,一个是状态i,一个是终结符号(包括输入结束标记$)a,ACTION[i, a]有四种取值:
- 移入。如果状态i上有一个转移a到达状态j,那么ACTION[i, a]=移入j;
- 归约。如果状态i上没有一个转移a,那么ACTION[i, a]=按照状态i上的产生式进行归约;
- 接受。语法分析器接受输入并完成语法分析过程;
- 报错。语法分析器在它的输入中发现一个错误并执行某个纠正动作。
- GOTO函数:实质上和项集的GOTO函数一样,只不过把项集替换成了状态。即:如果对项集的GOTO函数,有GOTO[Ii, A]=Ij,那么对LR语法分析表的GOTO函数,有GOTO[i, A]=j。
根据一个LR(0)自动机,我们可以立马得出LR语法分析表的GOTO函数,但是,对ACTION函数,应用下面的规则计算:
- 在LR(0)自动机中,如果项A→α·aβ在项集Ii中并且GOTO[Ii, a]=Ij,那么将ACTION[i, a]设为“移入j”;
- 在LR(0)自动机中,如果项A→α·在项集Ii中,那么对于FOLLOW(A)中的所有a,将ACTION[i, a]设为“按照A→α归约”,这里A不等于S’;
- 在LR(0)自动机中,如果项S’→S·在项集Ii中,那么将ACTION[i, $]设为“接受”。
除此之外,将所有空白的ACTION和GOTO设为“报错”。
PS:如果不清楚如何计算FOLLOW函数,可以浏览上一篇文章【编译原理】语法分析(二)。
现在尝试对文法G构建LR语法分析表,为了方便,我们对文法G中的每个产生式进行编号:
(1) E→E+T (2) E→T
(3) T→T*F (4) T→F
(5) F→(E) (6) F→id并约定ACTION函数中的每个符号的意义:
- si表示移入并将状态i压栈;
- rj表示按照序号为j的产生式进行归约;
- acc表示接受;
- 空白表示报错。
得到的LR语法分析表如下:

PS:对每个终结符号的ACTION函数,如果ACTION函数取值为移入,那么其实质就是GOTO函数。
为了说明LR语法分析表的使用方法,这里举一个例子:维护一个状态栈,初始时状态0位于栈顶,如果下一个输入符号是“id”,则将状态5压栈;位于状态5时,如果下一个输入符号是“*”,则使用产生式F→id进行归约,把id替换成F并将状态5从栈顶弹出,此时位于状态0(状态0在栈顶),由于状态0经过符号F的转移到达状态3,因此将状态3压栈;依次类推。对LR语法分析表完整系统的使用方法将在下一小节介绍。
LR语法分析算法
一个LR语法分析器由一个输入缓冲区、一个状态栈、一个语法分析表和一个结果输出组成,如下图所示:

语法分析表在上一小节中已经介绍过了,这里重点说一下状态栈。状态栈维护一个状态序列s0s1…sn,其中sn位于栈顶,每个状态si对应于LR(0)状态机中的某个状态,并且除了初始状态之外,每个状态都有一个唯一的相关联的文法符号。也就是说,在LR(0)状态机中,如果从Ii经过符号α转移到Ij,那么状态j的关联符号为α。
用状态栈和剩余的输入符号串可以完整的表示语法分析器在某一刻的状态,这个状态本质上是反向最右推导中的某个句型。我们用(s0s1…sm, a1a2…an$)表示语法分析器的状态,并称其为语法分析器的格局。其中,第一个分量是状态栈中的状态序列(sm是栈顶),第二个分量是剩余的输入符号串,如果把第一个分量中的每个状态替换为其关联的文法符号,再与第二个分量连接,就能得到反向最右推导中的一个句型。
假定LR语法分析器当前的格局为(s0s1…sm, aiai+1…an$),在根据当前格局决定下一个动作时,首先读入下一个输入的符号ai和栈顶的状态sm,然后查询LR语法分析表中的条目ACTION[sm, ai],执行相应的动作:
- 如果ACTION[sm, ai]=移入s,那么将状态s压入栈顶,格局变为(s0s1…sms, ai+1ai+2…an$);
- 如果ACTION[sm, ai]=按照A→β归约,那么将r(r是β的长度)个状态从栈顶弹出,并将状态s(s=GOTO[sm-r, A])压入栈顶,格局变为(s0s1…sm-rs, aiai+1…an$)。注意,在执行归约动作时,当前的输入符号不会改变;
- 如果ACTION[sm, ai]=接受,那么语法分析过程完成;
- 如果ACTION[sm, ai]=报错,那么语法分析器发现了一个语法错误,并调用一个错误恢复例程。
综上所述,一个LR语法分析器和LL语法分析器一样,也是表驱动的。两个LR语法分析器的唯一不同之处在于它们的语法分析表不同。
现在对文法G和输入符号串id*id+id,相应的LR语法分析表已经在上面得到了,分析其LR语法分析过程:
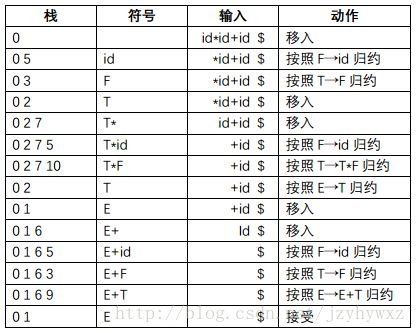
其中,状态栈的栈顶在右侧,符号是栈中每个状态关联的文法符号(初始状态0没有相关联的文法符号),并且,从最后一行开始到第一行,把每行的符号和输入连接起来得到文法G的一个句型,把这些句型用![]() 符号连接起来(除去重复的句型),就得到一个最右推导。
符号连接起来(除去重复的句型),就得到一个最右推导。

欢迎关注微信公众号fightingZh٩(๑❛ᴗ❛๑)۶