斗鱼直播数据分析(一)之利用python3爬虫获取数据
-
-
-
- 前言
- 一、网站爬取逻辑分析
- 二、爬虫步骤实现
- 1.获取每个分类的URL
- 2.获取每个分类下的游戏url
- 3.获取游戏名称、直播人数、观看热度
- 三、将爬虫数据保存到mysql数据库
- 1.创建表
- 2.连接数据库
- 3.拼装sql语句,写入数据库
- 4.最后关闭数据库连接
- 四、定时爬取
- 1.获取开始爬取时间
- 2.设置定时器
- 五、数据展示
- 1.爬取过程控制台日志展示
- 2.数据库数据展示
- 六、总结
-
-
前言
随着2012年开始直播行业的兴起,吃外卖看直播成了很多大学生每天都会做的事(当年我们宿舍的就是这么过来的╮( ̄▽ ̄)╭),伴随着最近自己很喜欢的一位主播跳槽到海鲜台,所以就打算扒一扒这个海鲜台,本篇文章分成2个部分:
- 利用python3爬虫获取数据
- 爬虫数据分析及可视化
本篇先对第一部分进行阐述。
一、网站爬取逻辑分析
基于上图,我们可以看出:
将分类做为入口,获取每个分类下的游戏列表,爬取分类下每个游戏的url,然后进入具体的游戏页面,拿英雄联盟为例:
基于上图,我们在页面可以轻易的获取到以下三个信息:
游戏名称:game_name、开播人数:paly_num、观看热度:watch_num
海鲜台已经帮我们做好统计,我们直接截取就ok了。
但是,万一有些直播节目斗鱼没有做这方面的统计呢?比如下面这个游戏直播页面是这样的:
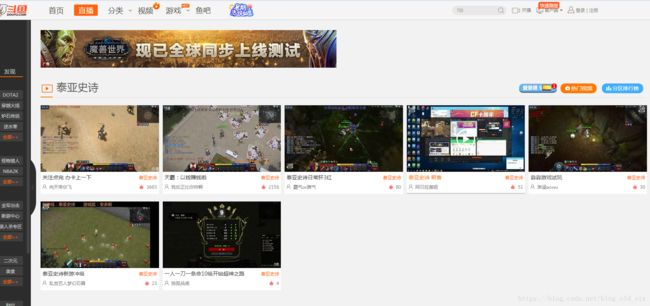
从上图可以发现,我们只能获取到游戏名称:game_name,拿不到开播人数:paly_num和观看热度:watch_num。
对于这样的情况,我们能想到的就是自己做统计,或许搜索框是我们的一个入手点:
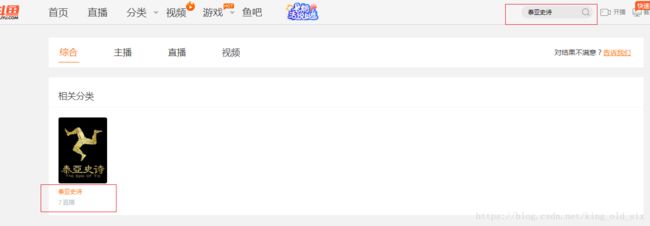
果然,通过搜索框,我们能获取到开播人数paly_num,通过搜索接口查询相比我们进去游戏直播列表一个一个页面做统计是不是便捷了很多,有了开播人数paly_num,观看热度watch_num的获取也挺容易:
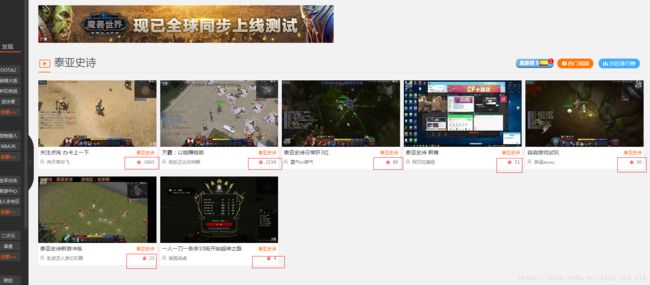
将每一个直播的热度做一个统计就能得到观看热度。
二、爬虫步骤实现
1.获取每个分类的URL
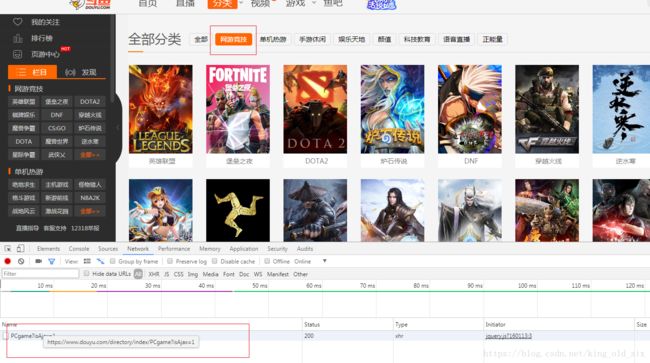
点击顶部的网游竞技,我们能从浏览器的network中获取到如下url:https://www.douyu.com/directory/index/PCgame?isAjax=1,这就是我们需要的分类url,其他分类也可以通过这样的做法来查看获取,获取到全部分类的url之后,我们可以定义一个字典来存放我们的分类:
# 斗鱼直播分类字典,key为直播分类名称,value为分类URL
classify_dict = {
'网游竞技' : 'https://www.douyu.com/directory/index/PCgame?isAjax=1',
'单机热游' : 'https://www.douyu.com/directory/index/djry?isAjax=1',
'手游休闲' : 'https://www.douyu.com/directory/index/syxx?isAjax=1',
'娱乐天地' : 'https://www.douyu.com/directory/index/yl?isAjax=1',
'颜值' : 'https://www.douyu.com/directory/index/yz?isAjax=1',
'科技教育' : 'https://www.douyu.com/directory/index/kjjy?isAjax=1',
'语音直播' : 'https://www.douyu.com/directory/index/voice?isAjax=1',
'正能量' : 'https://www.douyu.com/directory/index/znl?isAjax=1'
}2.获取每个分类下的游戏url
通过浏览器访问分类url,比如我们访问网游竞技的url,并查看页面源代码:

从源代码上看,a标签里面的href属性就是我们需要的游戏url,具体做法:
首先我们先定义一个浏览器伪装池,每次访问url时进行浏览器伪装,保证url访问的正常:
# 浏览器伪装列表
user_agent_pools = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'Mozilla/5.0(Macintosh;IntelMacOSX10.6;rv:2.0.1)Gecko/20100101Firefox/4.0.1',
'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',
'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Trident/4.0;SE2.XMetaSr1.0;SE2.XMetaSr1.0;.NETCLR2.0.50727;SE2.XMetaSr1.0)'
]然后定义一个公共的url访问的方法,所有的url访问都通过该方法;同时,为了保证容错性,需要有访问失败的重连机制,代码如下:
# 通过urllib模块获取url的html信息
# 这里通过while循环,利用线程睡眠控制程序2秒进行重连,增加容错性
def open_url(url):
# 从浏览器伪装池中随机获取一个头信息,并设置给opener对象
user_agent = random.choice(user_agent_pools)
headers = ('User-Agent', user_agent)
opener = ur.build_opener()
opener.addheaders = [headers]
# 将opener对象设为全局
ur.install_opener(opener)
flag = False
while not flag:
try:
# 获取html信息
data = ur.urlopen(url).read().decode('utf-8')
except Exception as e:
print('url [' + url + '] HTTP请求失败!正在准备重连……')
time.sleep(2)
continue
flag = True
return data接下来,遍历访问分类字典,获取每个游戏的url和data-tid(后面有用):
# 遍历斗鱼网站的分类字典列表,获取分类名称(key)与对应的URL(value)
for classify in classify_dict.items():
# 获取分类下的游戏列表
game_list_data = open_url(classify[1])
# 通过BeautifulSoup截取游戏列表中每个游戏对应的直播列表url和data-tid(后面有用)
game_list = bs(game_list_data)
# 遍历页面所有a标签,获取每个a标签里面的href、data-tid
for i in game_list.find_all('a'):
detail_url = "https://www.douyu.com" + str(i['href'])
data_id = str(i['data-tid'])3.获取游戏名称、直播人数、观看热度
访问每个游戏的url,即上一步获取到的detail_url,获取我们需要的信息,以英雄联盟(https://www.douyu.com/g_LOL)为例,同样查看页面源代码:
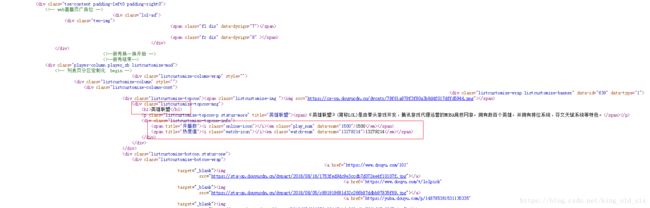
我们就可以获取需要的数据:
game_detail_data = open_url(detail_url)
game_detail = bs(game_detail_data)
# 获取h1标签为游戏名称
game = game_detail.h1.text
# 获取class=play_num为开播人数
play_num = int(game_detail.select(".play_num")[0].text)
# 获取class=watch-num为观看热度
watch_num = int(game_detail.select(".watch-num")[0].text)对于斗鱼没有做统计的游戏,做法如下:
将上一步的game游戏名称传入搜索url,进行查询来获取直播人数:
keyword = ur.quote(game) # 对中文进行编码
search_url = 'https://www.douyu.com/search/?kw=' + keyword
play_num = play_search(search_url)由于在爬取的过程中,有时候会出现搜索结果的直播人数获取失败,故定义play_search函数做处理,代码如下:
# 通过斗鱼网站的搜索获取游戏的开播人数,偶尔会出现获取直播人数失败的情况(一天1~2次),导致索引越界,具体原因没有明查
# 这里通过while循环,利用线程睡眠控制程序2秒重连,增加容错性
def play_search(url):
flag = False
while not flag:
try:
err_data = open_url(url)
# 使用正则表达式进行匹配
play_num = re.compile('\\s+(.*)直播').findall(err_data)[0]
except IndexError as e:
print('url [' + url + '] 获取直播人数失败!正在准备重连……')
time.sleep(2)
continue
flag = True
return play_num成功获取到直播人数后,开始统计观看热度,首先我们需要计算该游戏的直播列表分页数量,斗鱼默认的pageSize为120,故定义如下函数:
# 运用除法运算向上取整,来获取当前直播人数的直播列表分页数
def page_num(playNum, pageSize):
return int((playNum + pageSize - 1) / pageSize)得到游戏列表的分页数之后,遍历每页获取每页中每个直播的热度进行统计:
还是拿英雄联盟来研究研究:
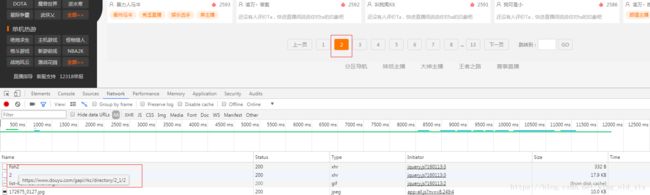
当我们点击第二页时,network中的https://www.douyu.com/gapi/rkc/directory/2_1/2这个url返回了一串json
通过将json串和页面显示内容进行比较,可以知道:json[data][rl][ol]就是每个直播的热度
在测试其他的游戏,得到url的规律为:https://www.douyu.com/gapi/rkc/directory/ + 1或2 + _ + data-tid + / + 页数
前面的data-tid的用处在这里就体现了,代码如下:
# 根据开播人数计算游戏的直播列表分页页数
pageNum = page_num(int(play_num), 120)
# 定义热度总和变量
watch_num = 0
# 获取每页的直播列表,并统计热度
for i in range(1, pageNum + 1):
# 该url返回为json对象,由于有的游戏url为'1_'+data_id,有的url则为'2_'+data_id,没有发现什么规律
# 故这里的做法为两个url都拼起来,先查询第一个,若第一个查询结果数据长度为空,则使用第二个
detail_url = 'https://www.douyu.com/gapi/rkc/directory/1_' + str(data_id) + '/' + str(i)
# 获取json字符串
err_data = open_url(detail_url)
# 将json字符串转化为json对象
obj = json.loads(err_data)
if len(obj['data']['rl']) == 0:
detail_url = 'https://www.douyu.com/gapi/rkc/directory/2_' + str(data_id) + '/' + str(i)
err_data = open_url(detail_url)
obj = json.loads(err_data)
for j in range(0, len(obj['data']['rl'])):
watch_num += int(obj['data']['rl'][j]['ol']) # 统计热度到这一步,代码的逻辑基本完成,接下来就是将爬取的数据保存下来
三、将爬虫数据保存到mysql数据库
使用pymysql模块将爬虫数据保存入库
1.创建表
DROP TABLE IF EXISTS `douyu_crawl_data`;
CREATE TABLE `douyu_crawl_data` (
`classify_name` varchar(255) DEFAULT NULL COMMENT '分类名称',
`game_name` varchar(255) DEFAULT NULL COMMENT '游戏名称',
`play_num` int(11) DEFAULT NULL COMMENT '直播人数',
`watch_num` int(11) DEFAULT NULL COMMENT '观看热度',
`crawl_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '爬取时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;2.连接数据库
# 准备数据库连接
db = pymysql.Connect(host="127.0.0.1", user="root", password="123456", db="crawl", port=3306)
cur = db.cursor()
print('连接数据库成功!开始爬取网页数据……')3.拼装sql语句,写入数据库
# 组装sql语句
sql = "INSERT INTO douyu_crawl_data (classify_name, game_name, play_num, watch_num, crawl_time) VALUES ('" + str(classify[0]) + "','" + str(game) + "','" + str(play_num) + "','" + str(watch_num) + "','" + str(crawl_start_time) + "')"
# 执行sql语句
cur.execute(sql)
db.commit()4.最后关闭数据库连接
# 关闭数据库连接
cur.close()
db.close()四、定时爬取
使用Timer模块实现定时爬取
1.获取开始爬取时间
在开始爬取之前,获取系统当前时间,为了便于后期的数据分析更加方便,将该时间作为该批爬取数据的crawl_time,实际误差在5分钟左右
# 记录该次爬取时间,为了便于后期的分析,开始爬取时记录当前的爬取时间作为该次爬取到的所有数据的爬取时间
crawl_start_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 爬取时间2.设置定时器
当爬取任务完成后,再次获取系统当前时间,计算本次爬取时长;同时,为了满足半个小时爬取一次的需求,需要计算:从开始爬取时间crawl_start_time到下一个爬取时间点的所剩时长crawl_space_time,将crawl_space_time的时间设置给定时器,让定时器执行下一次的爬取任务:
# 定时器,定时半小时执行爬取程序,计算整个过程一次爬取时间,1800-爬取所用时间为间隔时长
crawl_space_time = 1800.0 - (float(int(datetime.datetime.now().timestamp())) - time.mktime(time.strptime(crawl_start_time,'%Y-%m-%d %H:%M:%S')))
print("==========================================================================================")
print(" 爬取结束!等待下一次爬取,下一次爬取将于[" + str(crawl_space_time) + '] 秒后进行…… ')
print("==========================================================================================")
t = Timer(crawl_space_time, crawl)
t.start()五、数据展示
1.爬取过程控制台日志展示

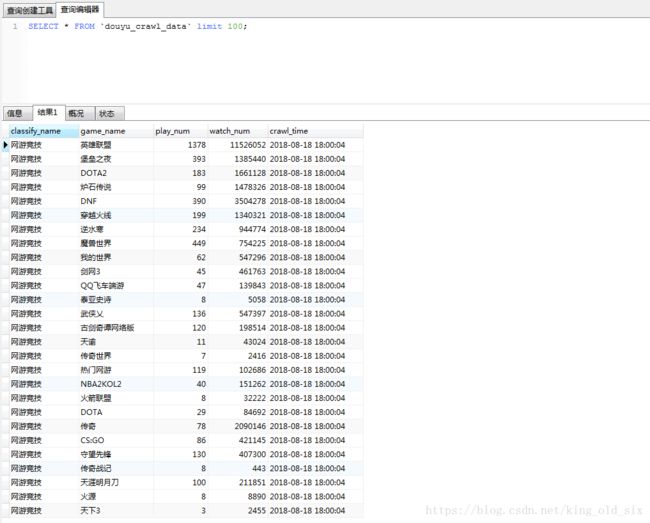
2.数据库数据展示
六、总结
至此,数据的爬取基本完成,完整代码查看点击这里。个人水平有限,代码写的有点粗糙,python也是现学现用( ̄▽ ̄)~*,望大家见谅,有什么问题也希望大家在评论区指出,不胜感激!
下篇预告:《斗鱼直播数据分析(二)之爬虫数据分析及可视化》