vue中结合element-ui的Pagination 分页组件写出后端给所有数据前端进行分页和有筛选条件的功能(前端数据分页)
vue中结合element-ui的Pagination 分页组件写出后端给所有数据前端进行分页和有筛选条件的功能(前端数据分页)
前言
昨天接到后端的一个获取接口,产品有分页,至今搞不懂为何后端竟然说出让我惊讶好久的话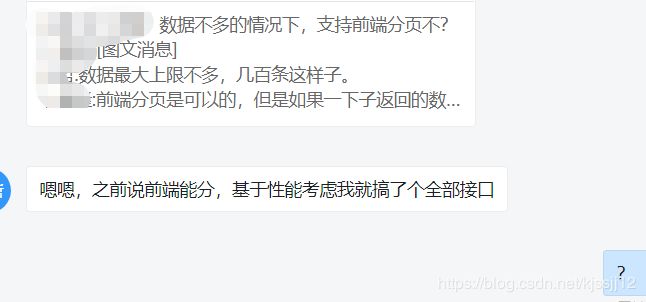
我只能回复一个问号,后面就是各种的讨论了,好吧,对于性能我的看法是在前端分页的话肯定要在前端各种操作数据,如果数据量复杂(几百条应该还好吧),那肯定会导致渲染慢从而耗费大量的内存,有时可能会让页面卡死,以前有做过获取列表的接口有几千条数据,直接卡死,页面都动不了,但是没办法,后台说卡死再执行planB,还是得前端做分页筛选,好吧,要做咱就做,咱也没慌过,又不是做不了对吧,
直奔主题
第一步肯定是要先缕下思路确定要处理多少东西得吧:

有下拉状态筛选有输入关键字搜索有时间排序 还有分页四个逻辑处理,后端就查个表直接返回所有数据
第二步 明白了要做的事,咱就一步步处理呗,先是从获取所有数据的初始化开始 直接上代码和注释呗
//获取数据
getChannelList(){
this.loading = true
this.$axios.get(`请求路径`).then(res => {
console.log(res);
this.loading = false; //lonading效果 v-loading
if(res.data.code==='200'){
this.listData = res.data.data || [];
this.totalRowCount = res.data.data.length
//前端分页 第一次取的是初始的页码1 和pageSize数分页
this.listData = this.listData.filter((item,index)=>index+1<=this.pageSize);
this.listDataBf = JSON.stringify(res.data.data); // 这个很重要,必须要备份深拷贝所有数据 咱把他变成字符串形式就可以打断堆类型的引用浅拷贝问题啦
}else {
this.$message.error(res.data.msg)
}
})
},
第三步处理逻辑
//分页
getPageList(){
//前端分页
//先筛选出筛选项的所有数据再进行分页筛选
this.listData = JSON.parse(this.listDataBf).filter((item,index)=>{
let statusFlag = this.channelListStatus==='全部'?true:item.channelEnabled===this.channelListStatus;
//关键字搜索
let searchFlag = item.corporation.indexOf(this.searchVal)>-1 || item.indChannelName.indexOf(this.searchVal)>-1 || item.managerName.indexOf(this.searchVal)>-1
//关键字匹配标红
let replaceReg = new RegExp(this.searchVal, 'g');
let replaceString = '' + this.searchVal + '';
if(item.corporation.indexOf(this.searchVal)>-1){
this.$set(item,'corporation',item.corporation.replace(replaceReg, replaceString))
}
if(item.indChannelName.indexOf(this.searchVal)>-1){
this.$set(item,'indChannelName',item.indChannelName.replace(replaceReg, replaceString))
}
if(item.managerName.indexOf(this.searchVal)>-1){
this.$set(item,'managerName',item.managerName.replace(replaceReg, replaceString))
}
return statusFlag && searchFlag
});
this.totalRowCount = this.listData.length;
this.listData = JSON.parse(JSON.stringify(this.listData)).filter((item,index)=>{
let pageFlag = index+1<=this.pageNo*this.pageSize&&index+1>(this.pageNo-1)*this.pageSize;
return pageFlag
});
},
//下拉筛选
channelListStatusChange(val){
if(!JSON.parse(this.listDataBf)||!JSON.parse(this.listDataBf).length) return; // 容错
this.pageNo = 1;
//先筛选出筛选项的所有数据
this.listData = JSON.parse(this.listDataBf).filter((item,index)=>{
if(val!=='全部') {
return item.channelEnabled===val
}else {
return true
}
});
//再进行分页筛选
this.totalRowCount = this.listData.length;
this.listData = JSON.parse(JSON.stringify(this.listData)).filter((item,index)=>{
let pageFlag = index+1<=this.pageSize;
return pageFlag
});
},
//搜索
searchGo(val){
if(!JSON.parse(this.listDataBf)||!JSON.parse(this.listDataBf).length) return; // 容错
this.listData = JSON.parse(this.listDataBf).filter(item=>{
let flag = item.corporation.indexOf(val)>-1 || item.indChannelName.indexOf(val)>-1 || item.managerName.indexOf(val)>-1;
let replaceReg = new RegExp(val, 'g');
let replaceString = '' + val + '';
if(item.corporation.indexOf(val)>-1){
this.$set(item,'corporation',item.corporation.replace(replaceReg, replaceString))
}
if(item.indChannelName.indexOf(val)>-1){
this.$set(item,'indChannelName',item.indChannelName.replace(replaceReg, replaceString))
}
if(item.managerName.indexOf(val)>-1){
this.$set(item,'managerName',item.managerName.replace(replaceReg, replaceString))
}
return flag
})
this.totalRowCount = this.listData.length;
this.listData = JSON.parse(JSON.stringify(this.listData)).filter((item,index)=>{
let pageFlag = index+1<=this.pageSize;
return pageFlag
});
},
第四步 逻辑写完了,自测功能可以实现了,作为一个21世纪的祖国花朵,咱接下来是不是要抽取下公共代码和优化下数据处理呢?
//分页
getPageList(){
//前端分页
//先筛选出筛选项的所有数据再进行分页筛选
this.listData = JSON.parse(this.listDataBf).filter((item,index)=>{
let statusFlag = this.channelListStatus==='全部'?true:item.channelEnabled===this.channelListStatus;
//关键字搜索
let searchFlag = item.corporation.indexOf(this.searchVal)>-1 || item.indChannelName.indexOf(this.searchVal)>-1 || item.managerName.indexOf(this.searchVal)>-1
//关键字匹配标红
this.searchActive(item);
return statusFlag && searchFlag
});
this.publicPage()
},
//下拉筛选 //搜索 两个方法改变都是同一个改变
statusOrSearchGo(){
if(!JSON.parse(this.listDataBf)||!JSON.parse(this.listDataBf).length) return; // 容错
this.pageNo = 1;
//先筛选出筛选项的所有数据
this.getPageList()
//再进行分页筛选
this.publicPage()
},
//抽取公用
publicPage(){
//分页抽取
this.totalRowCount = this.listData.length;
this.listData = JSON.parse(JSON.stringify(this.listData)).filter((item,index)=>{
let pageFlag = this.pageNo===1 ? index+1<=this.pageSize : index+1<=this.pageNo*this.pageSize&&index+1>(this.pageNo-1)*this.pageSize; //index+1 下标开始是0 下标加1在页码范围
return pageFlag
});
},
searchActive(item){
//关键字高亮抽取
let replaceReg = new RegExp(this.searchVal, 'g');
let replaceString = '' + this.searchVal + '';
if(item.corporation.indexOf(this.searchVal)>-1){
this.$set(item,'corporation',item.corporation.replace(replaceReg, replaceString))
}
if(item.indChannelName.indexOf(this.searchVal)>-1){
this.$set(item,'indChannelName',item.indChannelName.replace(replaceReg, replaceString))
}
if(item.managerName.indexOf(this.searchVal)>-1){
this.$set(item,'managerName',item.managerName.replace(replaceReg, replaceString))
}
},
抽取完了是不是觉得简便了好多呢?
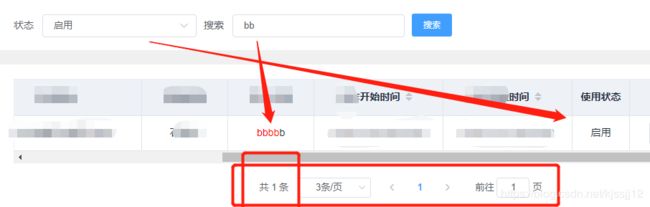
The Last 最后是不是要上点效果图呢
刚开始全部数据是这样的

筛选后
结语
以上是本人个人理解和看法喔,后面有发现bug再更新下,希望自己能坚持不断记录沉淀自己,提升能力,加油!!!!